
Flume
- 简介:
Flume 是一个分布式、高可用的服务,用于高效收集、聚合和移动大量日志数据。 - 作用:
Flume 主要承载的作用是收集各个数据源的事件或日志数据,然后将其Sink到数据库


- 架构
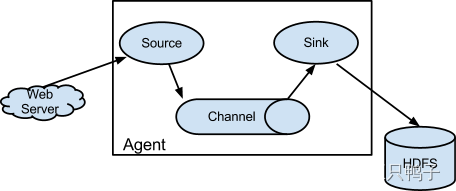
Flume的实现架构原理也非常简单,通过Agent代理来实现数据的收集,一个Agent包含了Source,channel,Sink三个组件。- Source:采集的数据来源,不同的数据源对应不同的格式,flume支持的source类型有很多,比如avro、thrift、twitter、exec、jms等
所有的Source类型可参考flume的官方文档:
https://flume.apache.org/FlumeUserGuide.html#flume-sources - Channel:缓冲区,将接收到的source数据缓存起来,供下游的sink消费,只有当数据被sink消费或者进入下一个channel的时候才会被删除。为了保证channel的可用性,flume也提供了多种channel类型,有memory、JDBC、File、Spillable Memory(当内存队列满了会存储到磁盘上) 、还支持自定义channel
- Sink:消费channel里的数据,将数据发送到目的地,比如hive、hbase等。
- Source:采集的数据来源,不同的数据源对应不同的格式,flume支持的source类型有很多,比如avro、thrift、twitter、exec、jms等
Sqoop
HDFS
- NameNode:负责管理metadata元数据,记录了文件所对应的块信息。
- DataNode,通常集群中每个节点都有一个DataNode,里面存储了具体的数据。
YARN
YARN是一个hadoop的资源管理器,负责管理资源和任务调度。
- ResourceManager :负责系统内所有应用的资源调度
- NodeManager 是每台机器的框架客户端/代理,负责容器管理,监控他们的资源使用情况,例如 cpu、memory、 disk、network,并汇报给ResourceManager/Scheduler
Spark
- SparkCore:实现了 Spark 的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块
- SparkSQL:通过SQL的方式连接数据库的数据,并将数据转化成DataFrame。SparkSQL支持多种数据源,包括 Hive、Avro、Parquet、ORC、JSON 和 JDBC。
- Spark Mllib:是Spark的机器学习库,高质量的算法比MapReduce快100倍。MIlib 提供了丰富和算法和统计方法
- 分类:逻辑回归、朴素贝叶斯、…
- 回归:广义线性回归,生存回归,…
- 决策树、随机森林和梯度提升树
- 建议:交替最小二乘法 (ALS)
- 聚类:K-means、高斯混合(GMM)、…
- 主题建模:潜在狄利克雷分配(LDA)
- 频繁项集、关联规则和序列模式挖掘
- 统计:线性代数、假设检验
- Spark Streaming:Spark的流式计算框架,实际上是基于时间的微批处理。通常Apache Flink可取而代之。
- GraphX:是 Apache Spark 用于图形计算的API
Kafka
Mahout
Lucene / Solr / ElasticSearch
Oozie
Zookeeper
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
ZooKeeper 的架构通过冗余服务实现高可用性。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
Ambari
Apache Ambari 是一个用于配置、管理和监控 Apache Hadoop 集群的工具。由一组 RESTful API 和一个web界面组成。
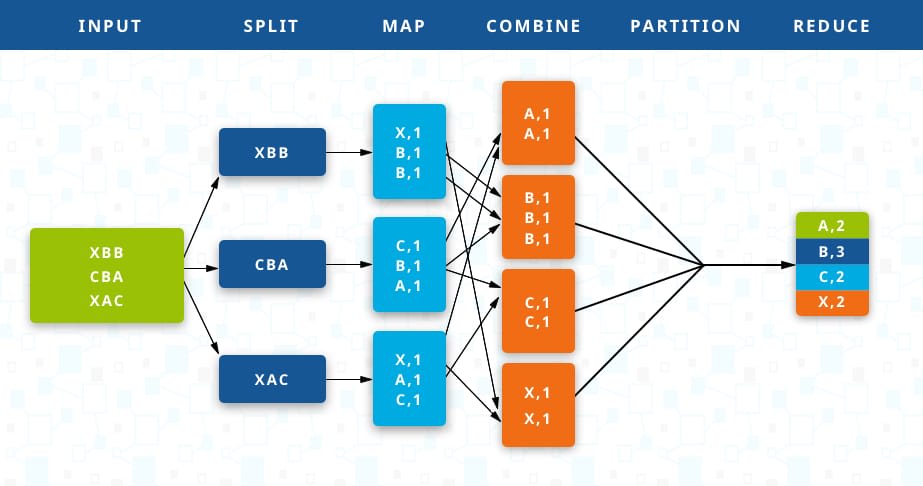
MapReduce
Hive
架构于Hadoop之上,可以将结构化的HDFS文件映射成一张表,并提供了类似于SQL语法的HQL查询功能。毫不夸张的说正是因为有了Hive的诞生,Hadoop才会被大面积推广和使用,并且经久不息。
核心本质:将HQL语句转换成MapReduce任务
- HIVE:
Meta Store: 元数据,一般存储在mysql
Client: 客户端
Driver:驱动器
HQL Parse: 解析器,HQL解析和语法分析
Physical Plan: 编译生成逻辑执行计划
Query Optimizer: 对逻辑执行计划进行优化
Execution: 把逻辑执行计划转换成物理执行计划 - Hadoop
Map Reduce: 执行计算
HDFS: 文件存储
Pig
HBase
届于大数据技术革新太快,本文会不定时更新,如果感兴趣的话,可以关注下。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233037.html原文链接:https://javaforall.net


