


各位同学们,好久没写原创技术文章了,最近有些忙,所以进度很慢,给大家道个歉。
警告:本教程仅用作学习交流,请勿用作商业盈利,违者后果自负!如本文有侵犯任何组织集团公司的隐私或利益,请告知联系猪哥删除!!!
淘宝系列教程:
- 第一篇:Python模拟登录淘宝,详细讲解如何使用requests库登录淘宝pc端。
- 第二篇:淘宝自动登录2.0,新增Cookies序列化,教大家如何将cookies保存起来。
- 第三篇:Python爬取淘宝商品避孕套,教大家如何爬取淘宝pc端商品信息。
- 第四篇:Python分析2000款避孕套,教大家如何做数据分析得出结论。

一、淘宝登录复习
前面我们已经介绍过了如何使用requests库登录淘宝,收到了很多同学的反馈和提问,猪哥感到很欣慰,同时对那些没有及时回复的同学说声抱歉!
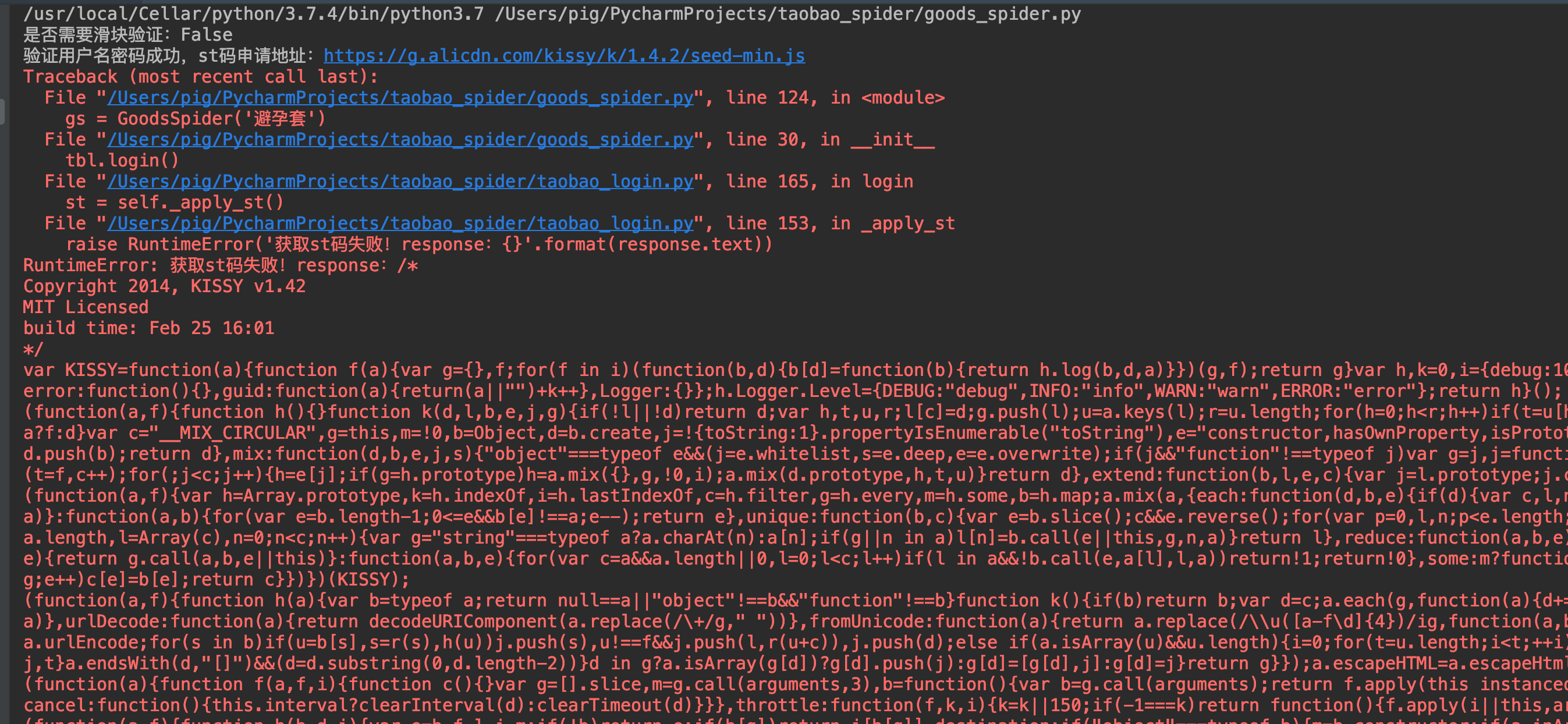
顺便再提一下这个登录功能,代码是完全没有问题。如果你登录出现申请st码失败的错误时候,可以更换_verify_password方法中的所有请求参数。
在淘宝登录2.0改进中我们增加了cookies序列化的功能,目的就是为了方便爬取淘宝数据,因为如果你同一个ip频繁登录淘宝的话可能就会触发淘宝的反扒机制!
关于淘宝登录的成功率,在猪哥实际的使用中基本都能成功,如果不成功就按上面的方法更换登录参数!
二、淘宝商品信息爬取
这篇文章主要是讲解如何爬取数据,数据的分析放在下一篇。之所以分开是因为爬取淘宝遇到的问题太多,而猪哥又打算详细再详细的为大家讲解如何爬取,所以考虑篇幅及同学吸收率方面就分两篇讲解吧!宗旨还会不变:让小白也能看得懂!
本次爬取是调用淘宝pc端搜索接口,对返回的数据进行提取、然后保存为excel文件!
看似一个简单的功能却包含了很多问题,我们来一点一点往下看吧!
三、爬取单页数据
开始写一个爬虫项目我们都需要量化后再分步,而一般第一步便是先爬取一页试试!
1.查找加载数据URL
2. 是否有返回纯json数据接口?
3.使用请求网页接口
所以我们选择类似第一页(请求url中不带ajax=true参数,返回整个网页形式)的请求接口,然后再把数据提取出来!
这样我们就可以爬取到淘宝的网页信息了
四、提取商品属性
爬到网页之后,我们要做的就是提取数据,这里先从网页提取json数据,然后解析json获取想要的属性。
1.提取网页中商品json数据
既然我们选择了请求整个网页,我们就需要了解数据内嵌在网页的哪个位置,该怎么提取出来。
经过猪哥搜索比较发现,返回网页中的js参数:g_page_config就是我们要的商品信息,而且也是json数据格式!
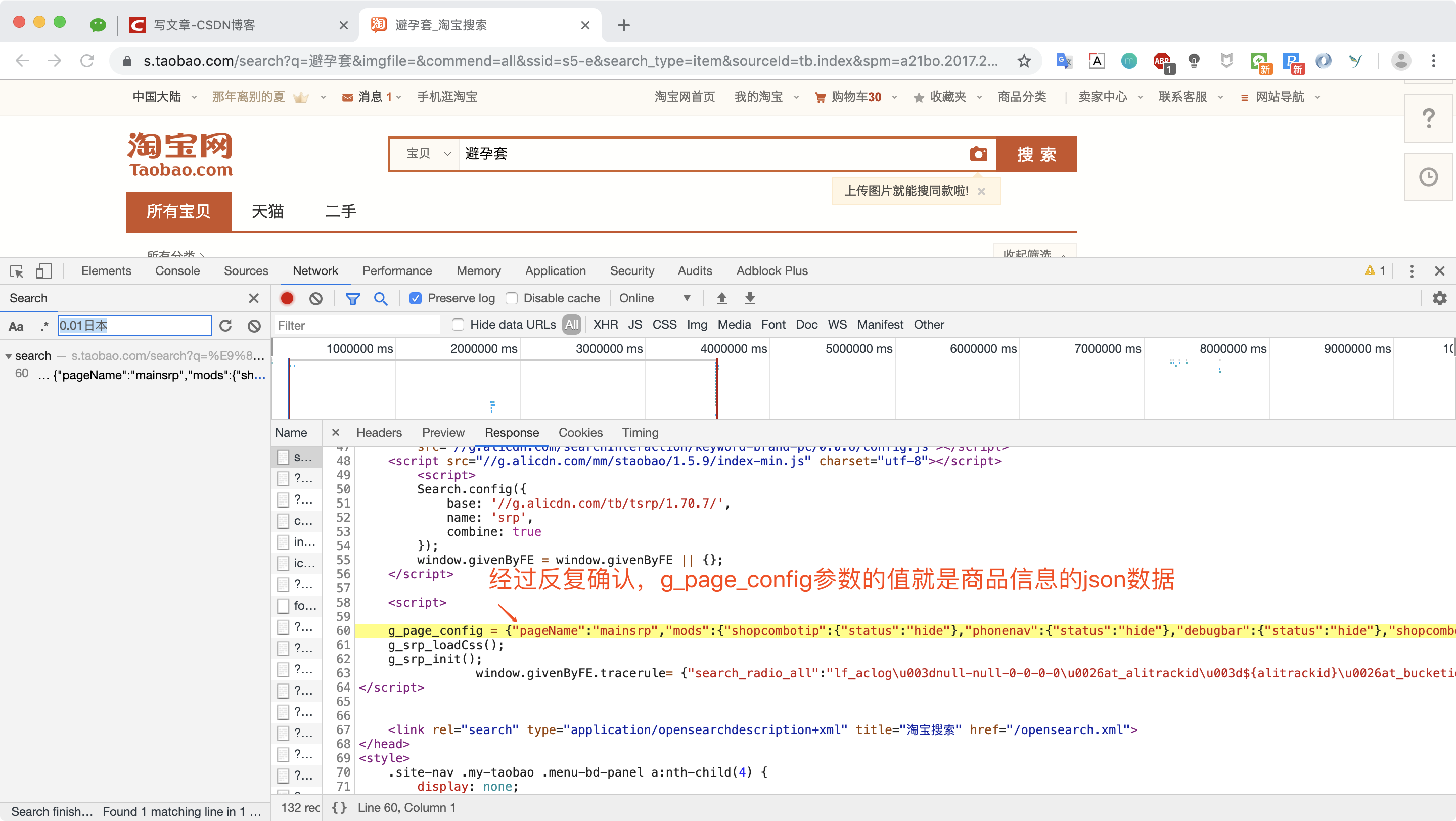
然后我们写一个正则就可以将数据提取出来了!
goods_match = re.search(r'g_page_config = (.*?)}};', response.text) 2.获取商品价格等信息
五、保存为excel
操作excel有很多库,网上有人专门针对excel操作库做了对比与测评感兴趣可以看看:https://dwz.cn/M6D8AQnq
猪哥选择使用pandas库来操作excel,原因是pandas比较操作方便且是比较常用数据分析库!
1.安装库
pandas库操作excel其实是依赖其他的一些库,所以我们需要安装多个库
pip install xlrd pip install openpyxl pip install numpy pip install pandas 2.保存excel

这里有点坑的是pandas操作excel没有追加模式,只能先读取数据后使用append追加再写入excel!
六、批量
七、爬取淘宝遇到的问题
爬取淘宝遇到了非常多的问题,这里为大家一一列举:
1.登录问题
问题:申请st码失败怎么办?
回答:更换_verify_password方法中的所有请求参数。
参数没问题的话登录基本都会成功!
2.代理池
但是有一个网站的ip很好 站大爷:http://ip.zdaye.com/dayProxy.html ,这个网站每小时都会更新一批ip,猪哥试过还是有很多ip是可以爬取淘宝的。
3.重试机制
pip install retry 4.出现滑块
5.目前这只爬虫
目前这只爬虫并不完善,只能算是半成品,有很多可以改进的地方,比如自动维护ip池功能,多线程分段爬取功能,解决滑块问题等等,后面我们一起来慢慢完善这只爬虫,使他可以成为一只完善懂事的爬虫!
获取源码,vx扫描下方二维码,关注vx公众号「裸睡的猪」 回复:淘宝 即可获取!

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233345.html原文链接:https://javaforall.net


