


一般来说我们可以使用正则化来避免过度拟合。但是实际上什么是正则化,什么是通用技术,以及它们有何不同?
那么,如何修改逻辑回归算法以减少泛化误差呢?
我发现的常见方法是高斯,拉普拉斯,L1和L2。
高斯还是L2,拉普拉斯还是L1?这有什么不同吗?
可以证明L2和高斯或L1和拉普拉斯正则化对算法具有同等影响。获得正则化效果的方法有两种。
第一种方法:添加正则项
第一种方法
但是为什么我们要惩罚高系数呢? 如果一个特征仅在一个类别中出现,则将通过逻辑回归算法为其分配很高的系数。 在这种情况下,模型可能会非常完美地了解有关训练集的所有详细信息。
被添加以惩罚高系数的两个常见的正则化项是l1范数或范数l2的平方乘以½,这激发了名称L1和L2正则化。
注意。 系数½用于L2正则化的某些推导中。 这使得计算梯度更容易,但是,仅常数值可以通过选择参数λ来补偿。
第二种方法:
贝叶斯正则化观点
第二种方法假定系数的给定先验概率密度,并使用最大后验估计(MAP)方法。 例如,我们假设系数为均值0和方差σ2的高斯分布或系数为方差σ2的拉普拉斯分布。
在这种情况下,我们可以通过选择方差来控制正则化的影响。 较小的值导致较小的系数。 但是,σ2的较小值可能会导致拟合不足。
所提及的两种方法密切相关,并且通过正确选择控制参数λ和σ2,可得出该算法的等效结果。 在KNIME中,以下关系成立:
选择线性回归的先验
主要思想是在使我们达到L1和L2正则化的线性回归系数上选择贝叶斯先验。 让我们看看它是如何工作的。
并根据公式:
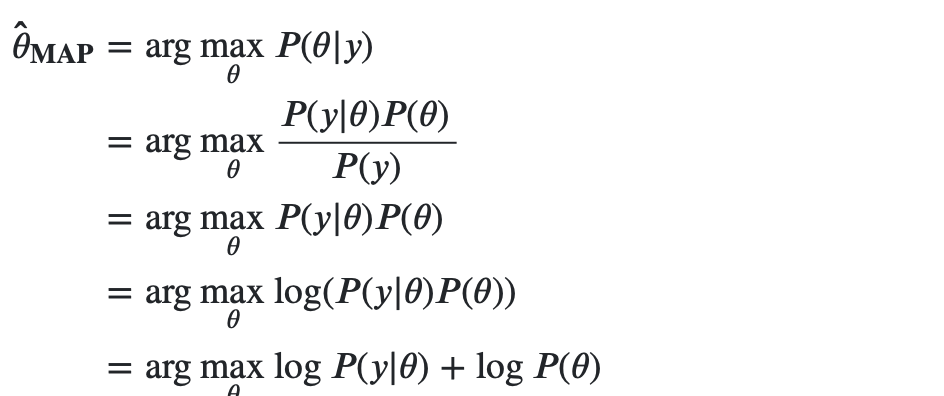
我们删除了许多常量。我们可以看到,这与(L2正则化)相同,其中? = ?2 / ?2假定为在常规线性模型中为常数) 回归,我们就可以选择我们的先验。 我们可以通过更改adjust来调整所需的正则化量。 同样,我们可以调整要加权先验系数的数量。 如果我们有一个很小的方差大large,那么系数将非常接近0; 如果我们有很大的方差(小的?,那么系数不会受到太大的影响(类似于我们没有任何正则化的情况)。
因此,L2正则化没有任何特定的内置机制来支持归零系数,而L1正则化实际上偏爱这些稀疏解。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233785.html原文链接:https://javaforall.net

![C语言中的sizeof()和strlen()的区别[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
