
ResNet34网络结构
先上图
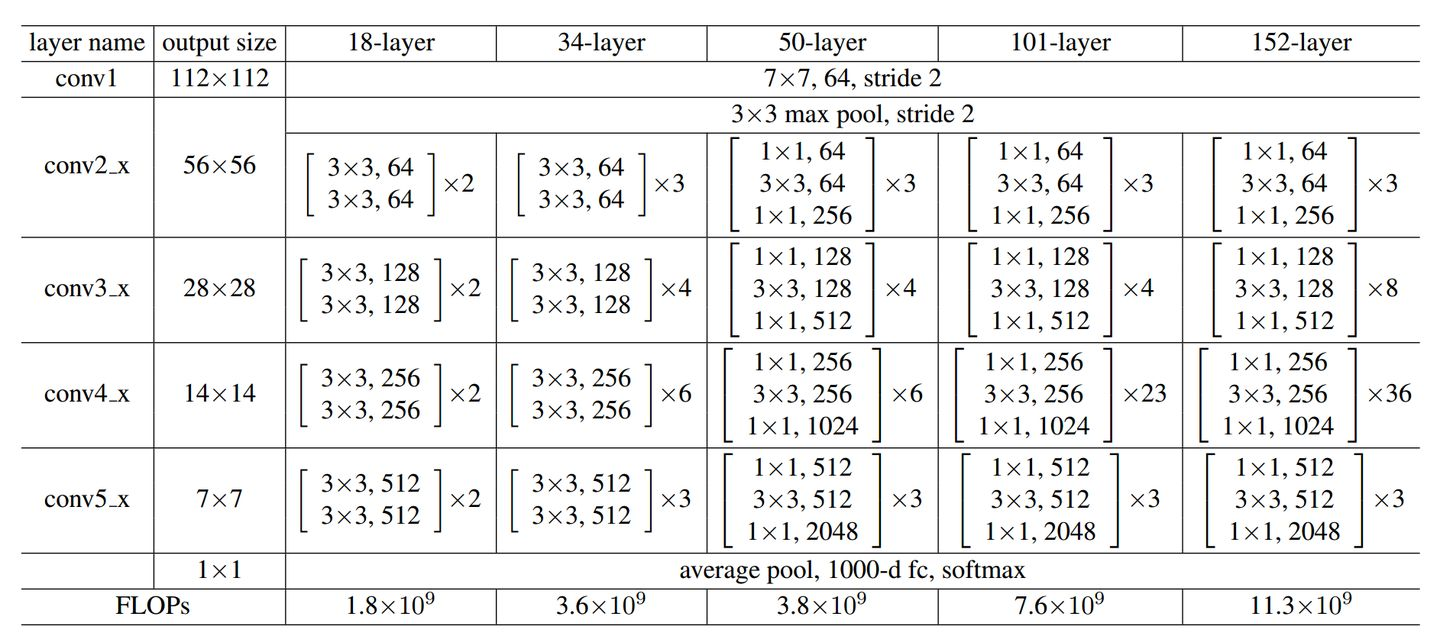

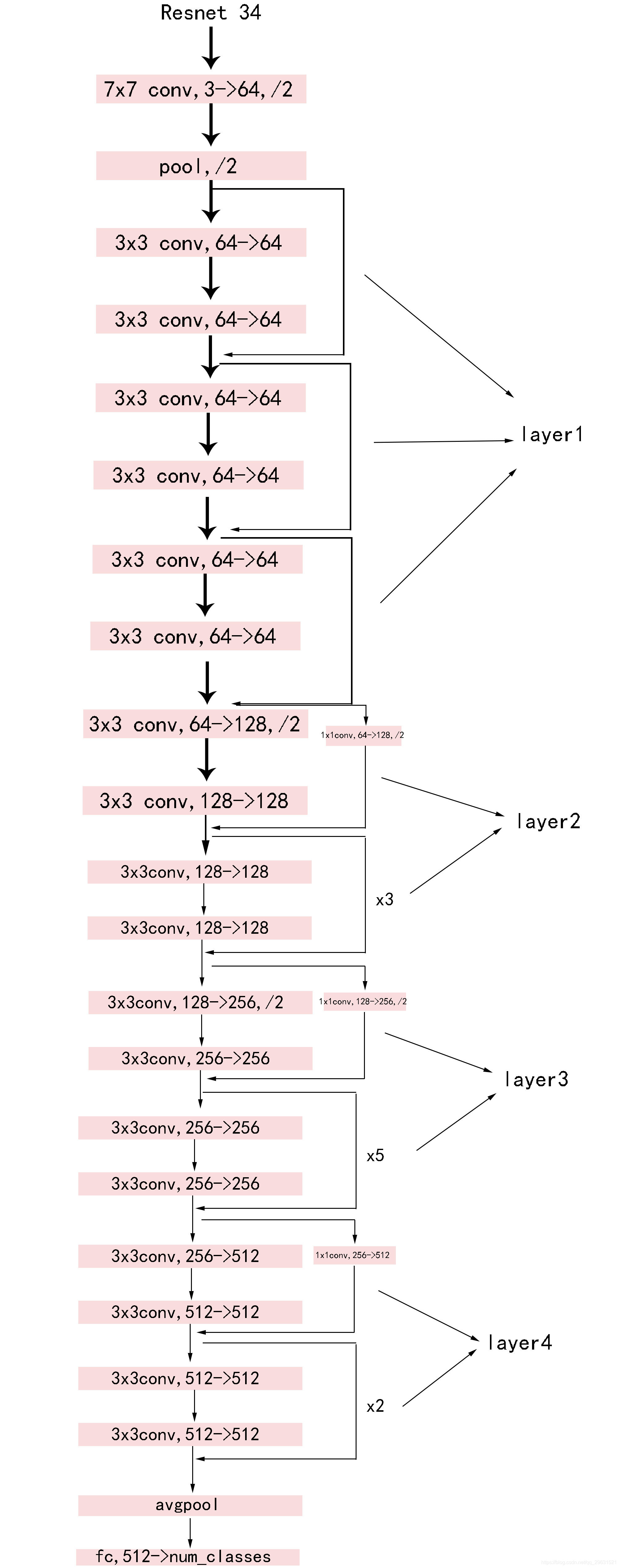
参照ResNet18的搭建,由于34层和18层几乎相同,叠加卷积单元数即可,所以没有写注释,具体可以参考我的ResNet18搭建中的注释,ResNet34的训练部分也可以参照。
使用PyTorch搭建ResNet18网络
ResNet34的model.py模型部分
import torch import torch.nn as nn from torch.nn import functional as F class CommonBlock(nn.Module): def __init__(self, in_channel, out_channel, stride): super(CommonBlock, self).__init__() self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(out_channel) self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(out_channel) def forward(self, x): identity = x x = F.relu(self.bn1(self.conv1(x)), inplace=True) x = self.bn2(self.conv2(x)) x += identity return F.relu(x, inplace=True) class SpecialBlock(nn.Module): def __init__(self, in_channel, out_channel, stride): super(SpecialBlock, self).__init__() self.change_channel = nn.Sequential( nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride[0], padding=0, bias=False), nn.BatchNorm2d(out_channel) ) self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride[0], padding=1, bias=False) self.bn1 = nn.BatchNorm2d(out_channel) self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=stride[1], padding=1, bias=False) self.bn2 = nn.BatchNorm2d(out_channel) def forward(self, x): identity = self.change_channel(x) x = F.relu(self.bn1(self.conv1(x)), inplace=True) x = self.bn2(self.conv2(x)) x += identity return F.relu(x, inplace=True) class ResNet34(nn.Module): def __init__(self, classes_num): super(ResNet34, self).__init__() self.prepare = nn.Sequential( nn.Conv2d(3, 64, 7, 2, 3), nn.BatchNorm2d(64), nn.ReLU(inplace=True), nn.MaxPool2d(3, 2, 1) ) self.layer1 = nn.Sequential( CommonBlock(64, 64, 1), CommonBlock(64, 64, 1), CommonBlock(64, 64, 1) ) self.layer2 = nn.Sequential( SpecialBlock(64, 128, [2, 1]), CommonBlock(128, 128, 1), CommonBlock(128, 128, 1), CommonBlock(128, 128, 1) ) self.layer3 = nn.Sequential( SpecialBlock(128, 256, [2, 1]), CommonBlock(256, 256, 1), CommonBlock(256, 256, 1), CommonBlock(256, 256, 1), CommonBlock(256, 256, 1), CommonBlock(256, 256, 1) ) self.layer4 = nn.Sequential( SpecialBlock(256, 512, [2, 1]), CommonBlock(512, 512, 1), CommonBlock(512, 512, 1) ) self.pool = nn.AdaptiveAvgPool2d(output_size=(1, 1)) self.fc = nn.Sequential( nn.Dropout(p=0.5), nn.Linear(512, 256), nn.ReLU(inplace=True), nn.Dropout(p=0.5), nn.Linear(256, classes_num) ) def forward(self, x): x = self.prepare(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.pool(x) x = x.reshape(x.shape[0], -1) x = self.fc(x) return x 版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233959.html原文链接:https://javaforall.net


