
前言:最近公司有个项目要进行压测,压测完之后发现tps没有达到预期目标,最后自己手动计算了一遍tps,偶然间发现一个问题,JMeter报告中的吞吐量误差较大!
按照经典理论模型计算吞吐量TPS或者QPS应该是等于并发线程数除以平均响应时间:
tps =Thread / AVG(t)(并发线程数除以平均响应时间)
或者 tps = COUNT(request) / T(总的请求数除以总的请求时间)
大家看上图汇总结果:平均响应时间494ms,30并发,计算得到的吞吐量为:60.73/s,JMeter给出的吞吐量为50.04,误差相差10。
到底是什么原因导致误差这么大呢,经过我反复的压测实验,发现我的demo使用了较多的正则匹配来校验响应返回值,以及各种各样的断言,那么是不是JMeter在处理返回值消耗的时间较多导致了计算吞吐量误差的呢?
那么我们通过一个实验验证一下:首先写一个脚本,我用了单线程的脚本,请求10次看结果:
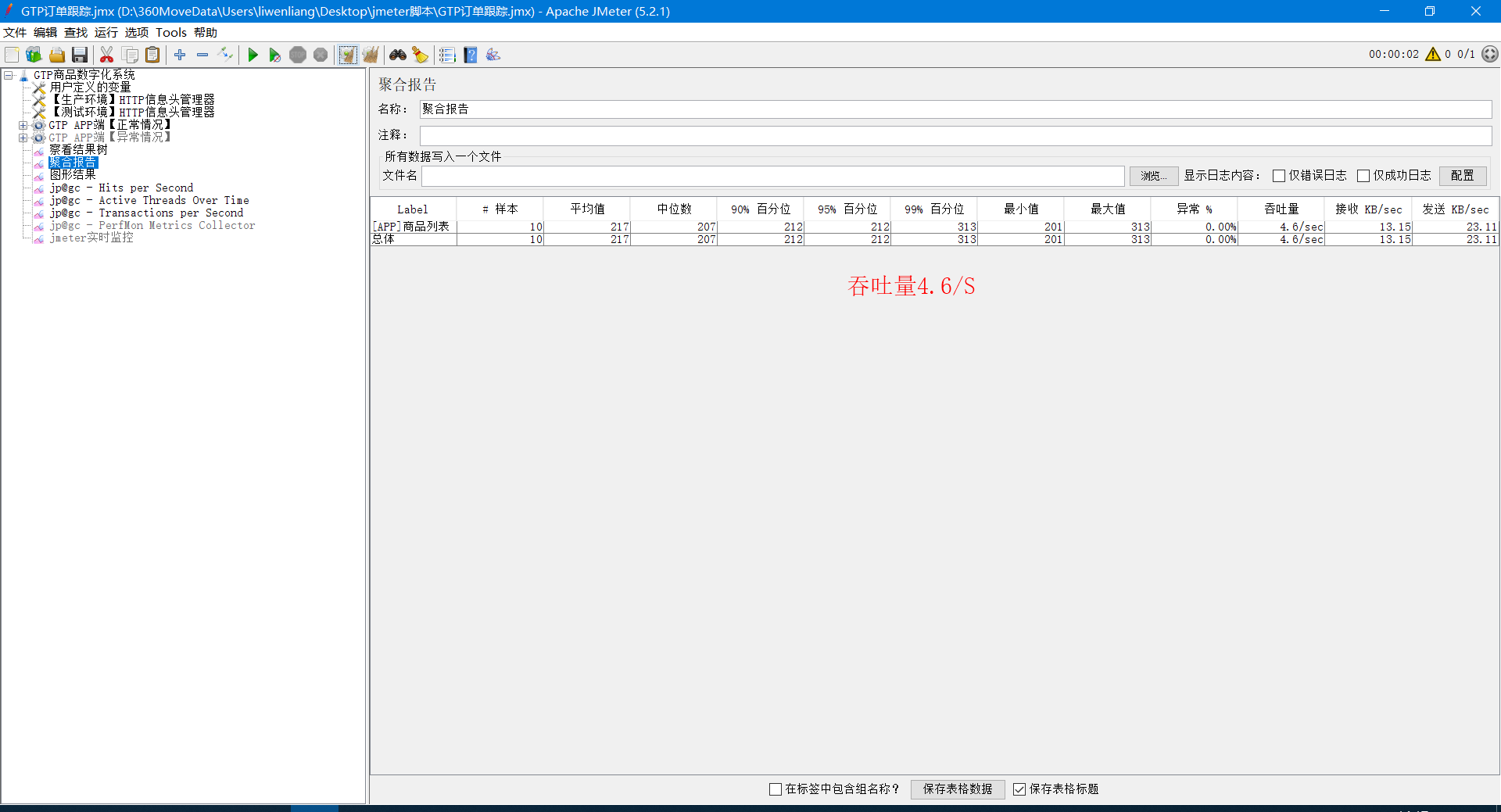

看结果,平均响应时间217ms,一个并发,计算得到的结果为4.61/s,JMeter给出的结果4.6/s,符合预期。
那么1.5/s的吞吐量是怎么来的呢?我们给219ms加上我们的等待500ms(这里是应该加上500 * 9 / 10),计算结果为1/(219+500 * 9 / 10)=1.49,跟JMeter给出的1.5符合,基本可以断定JMeter在计算吞吐量时候,把本机处理的过程给计算在内了。
如果JMeter在整个请求过程中平均响应时间是正常统计请求发出到接收到响应的时间,但是吞吐量却是用本机的整个线程一次循环的时间作为吞吐量计算的依据。
如果你在线程中做了别的事情,比如正则提取,参数校验,变量赋值等等都会导致吞吐量会变小。而一旦本机处理时间增加,那么压测过程中给服务端的实际压力也是比配置的要小,如果本机性能消耗过大或者某些地方发生等待,那么得到的吞吐量就可以当做一个假数据处理了。
如果发现误差较大,一定要进行结果修正,避免假数据。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/234020.html原文链接:https://javaforall.net

![jquery事件delegate()方法用法详解[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
