
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
1. 功能说明
使用snappy压缩来提升mapreduce和hbase的性能。其实就是用CPU换IO吞吐量和磁盘空间。配置并使用snappy有如下几点要求:
- 首先需要hadoop集群的native库已经收到编译好,并且添加了对snappy的支持。编译hadoop源码之前安装了snappy并且编译时指定-Drequire.snappy参数。(我使用的版本是hadoop-2.5.0-cdh5.3.3伪分布式)
- 安装了maven(我使用的版本是3.0.5)
- jdk已经成功安装并设置了JAVA_HOME(我使用的版本是1.7.0_75)
2. MapReduce配置snappy
配置过程参考官网(但是有所区别)
2.1 测试MR
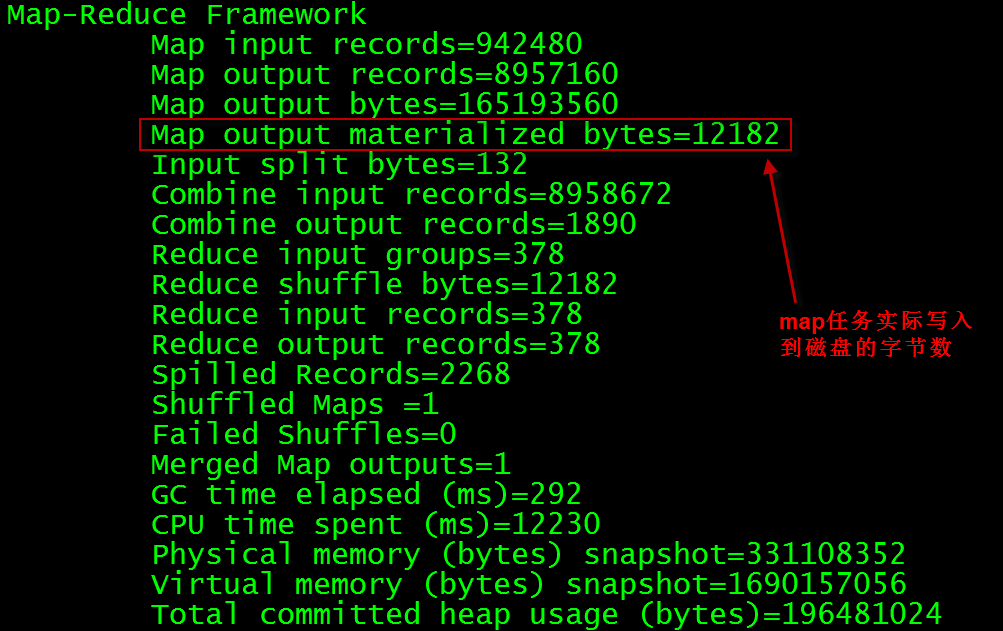
为了与后期配置完成snappy后进行对比我们先测试一个简单mapreduce程序,然后记录map的输出bytes大小
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.3.jar wordcount /wordcount/in /wordcount/out
2.2 安装依赖
首先在服务器上安装snappy,而安装snappy需要一系列的依赖,为了避免麻烦我们首先安装好这些依赖
$ sudo yum -y install gcc c++ autoconf automake libtool2.3 下载snappy安装包
从官网下载snappy的安装包
2.4 上传部署
将snappy-1.1.1.tar.gz上传到服务器解压重命名为snappy-1.1.1,【SNAPPY_HOME】为【/usr/local/cdh-5.3.3/snappy-1.1.1】
2.5 安装snappy
进入【SNAPPY_HOME】目录下安装snappy
$ sudo ./configure
$ sudo make
$ sudo make install注:一定要确保全程无Error!
如果安装成功的话进入【/usr/local/lib】目录下(默认位置),可以看到已经生成了snappy的库文件
$ cd /usr/local/lib
$ ll

2.6 下载hadoop-snappy
从github上将hadoop-snappy压缩包下载下来
2.7 上传部署
将hadoop-snappy-master.zip部署到服务器解压重命名为hadoop-snappy-master
$ unzip hadoop-snappy-master.zip2.8 编译hadoop-snappy
进入hadoop-snappy-master,使用maven进行编译
$ cd hadoop-snappy-master
$ mvn clean package
注:如果你的snappy是使用其他方式安装的请一定找到snappy的安装路径,并在编译的时候添加参数-Dsnappy.prefix=SNAPPY_INSTALLATION_DIR,不指定的话默认为【/usr/local】目录。
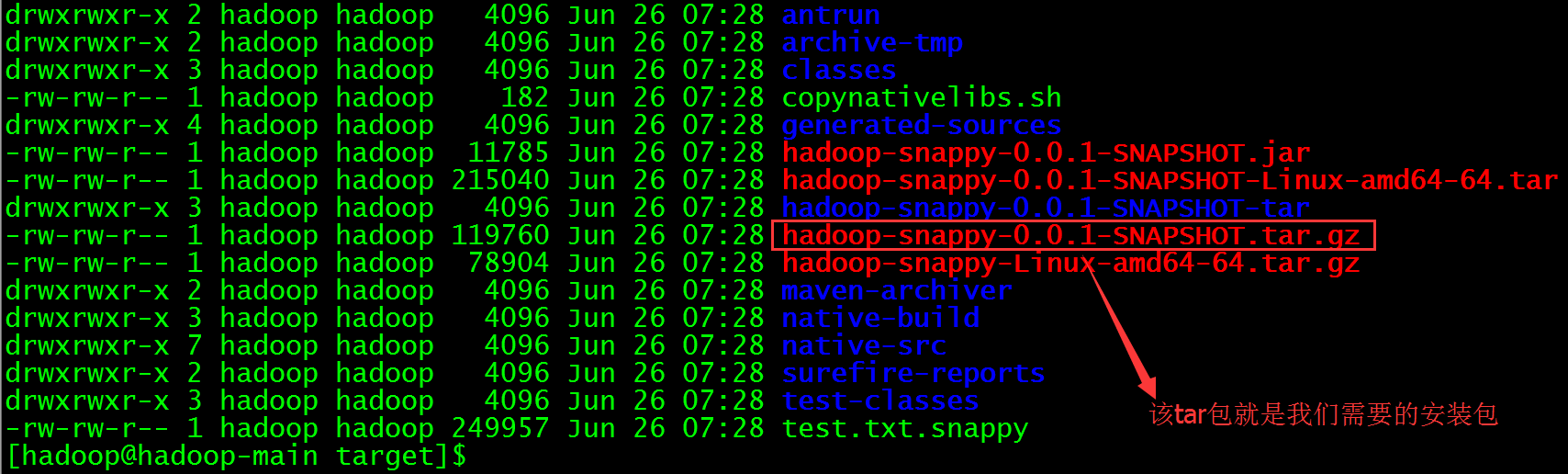
编译好的tar包在当前目录下的target目录下(hadoop-snappy-0.0.1-SNAPSHOT.tar.gz)
2.9 配置
2.9.1 配置native
将2.7中编译得到的hadoop-snappy-0.0.1-SNAPSHOT.tar.gz解压,拷贝需要的jar包和native到hadoop的lib目录下
$ tar -zxvf hadoop-snappy-0.0.1-SNAPSHOT.tar.gz
$ cp hadoop-snappy-0.0.1-SNAPSHOT/lib/hadoop-snappy-0.0.1-SNAPSHOT.jar $HADOOP_HOME/lib
$ cp hadoop-snappy-0.0.1-SNAPSHOT/lib/native/Linux-amd64-64/* $HADOOP_HOME/lib/native/2.9.2 配置core-site.xml
配置hadoop集群的的core-site.xml文件,添加如下参数:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec
,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property>2.9.3 配置mapred-site.xml
配置hadoop集群的mapred-site.xml,添加如下参数:
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>注:为了测试方便我们只配置map的输出压缩。
2.9.4 重启hadoop集群
修改完core-site.xml和mapred-site.xml文件后重启hadoop集群。
2.10 验证MapReduce
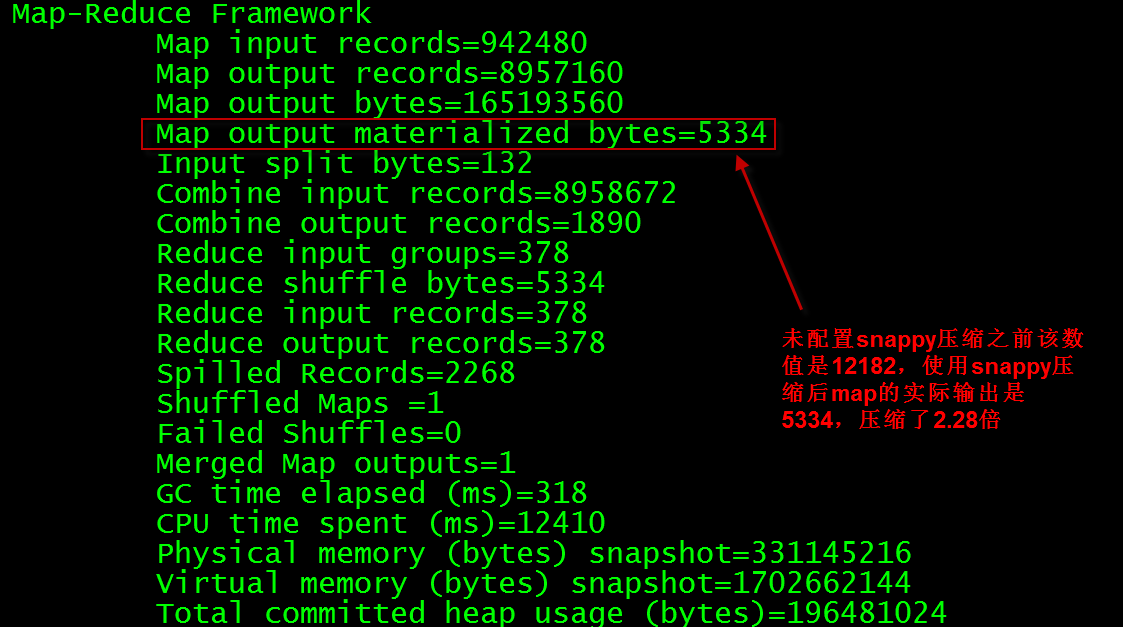
重新运行2.1节中的mapreduce程序
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.3.jar wordcount /wordcount/in /wordcount/out2
2.11 错误记录
问题描述
在2.9.1节中配置native库时按照官方文档是将整个编译解压后的snappy lib目录下的所有内容都拷贝到HADOOP_HOME/lib目录下
$ cp -r hadoop-snappy-0.0.1-SNAPSHOT/lib/* $HADOOP_HOME/lib但是在测试MR的时候提示无法加载到snappy的library
Caused by: java.lang.RuntimeException: native snappy library not available: SnappyCompressor has not been loaded.
at org.apache.hadoop.io.compress.SnappyCodec.checkNativeCodeLoaded(SnappyCodec.java:69)
at org.apache.hadoop.io.compress.SnappyCodec.getCompressorType(SnappyCodec.java:132)
at org.apache.hadoop.io.compress.CodecPool.getCompressor(CodecPool.java:148)
at org.apache.hadoop.io.compress.CodecPool.getCompressor(CodecPool.java:163)
at org.apache.hadoop.mapred.IFile$Writer.<init>(IFile.java:114)
at org.apache.hadoop.mapred.IFile$Writer.<init>(IFile.java:97)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.sortAndSpill(MapTask.java:1602)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.access$900(MapTask.java:873)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer$SpillThread.run(MapTask.java:1525)解决办法
按照2.9.1节中配置native库即可,其实就是将Linux-amd64-64文件夹下的snappy库文件都直接放到$HADOOP_HOME/lib/native目录下。网上说的各种配置环境变量什么的都试过了,没有起到作用。
3. HBase配置snappy
3.1 配置native
参照2.9.1中步骤将hadoop-snappy-0.0.1-SNAPSHOT.jar和snappy的library拷贝到HBASE_HOME/lib目录下即可
$ cp hadoop-snappy-0.0.1-SNAPSHOT/lib/hadoop-snappy-0.0.1-SNAPSHOT.jar $HBASE_HOME/lib
$ mkdir $HBASE_HOME/lib/native
$ cp -r hadoop-snappy-0.0.1-SNAPSHOT/lib/native/Linux-amd64-64/* $HBASE_HOME/lib/native/注: 如果创建失败则使用如下命令
$ cp hadoop-snappy-0.0.1-SNAPSHOT/lib/hadoop-snappy-0.0.1-SNAPSHOT.jar $HBASE_HOME/lib
$ mkdir $HBASE_HOME/lib/native/Linux-amd64-64
$ cp -r hadoop-snappy-0.0.1-SNAPSHOT/lib/native/Linux-amd64-64/* $HBASE_HOME/lib/native/Linux-amd64-64/3.2 重启HBase集群
重启HBase集群
3.3 验证
先使用以下命令测试snappy对hbase是否可用
$ bin/hbase org.apache.hadoop.hbase.util.CompressionTest hdfs://hadoop-main.dimensoft.com.cn:8020/wordcount/out2/part-r-00000 snappy
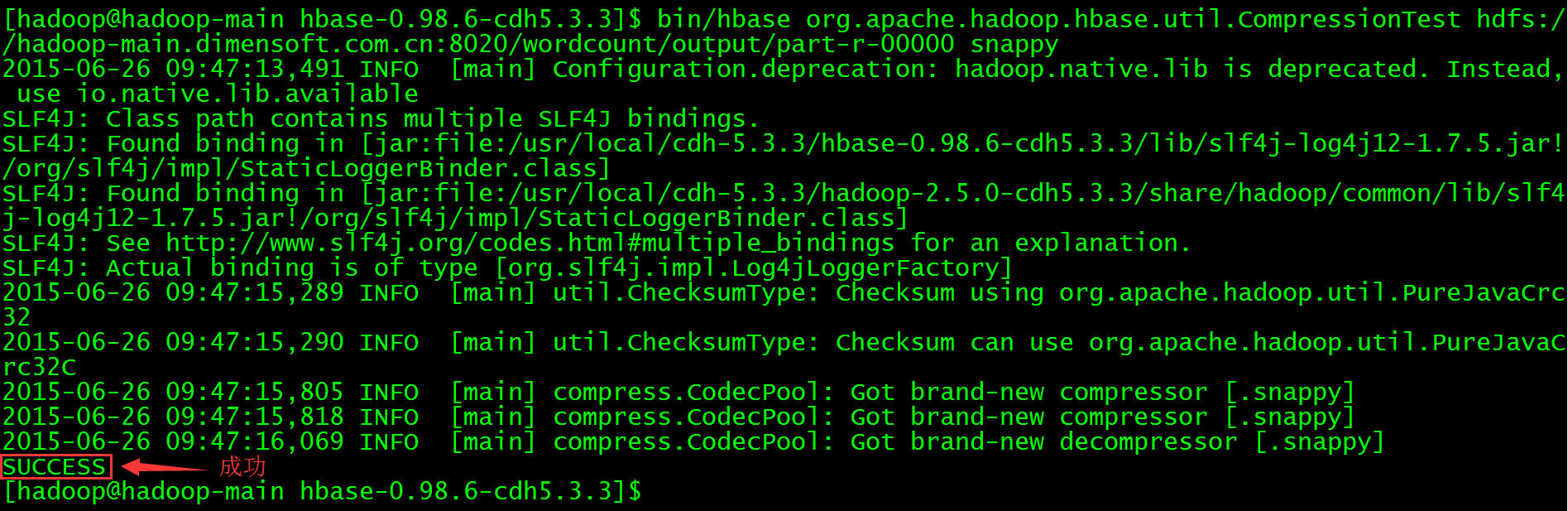
注:hdfs://hadoop-main.dimensoft.com.cn:8020/wordcount/put2/part-r-00000是在2.10节中验证MapReduce使用snappy时候的输出文件
进入HBase的CLI创建数据表,指定压缩方式
> create 'company', { NAME => 'department', COMPRESSION => 'snappy'}
> describe 'company'
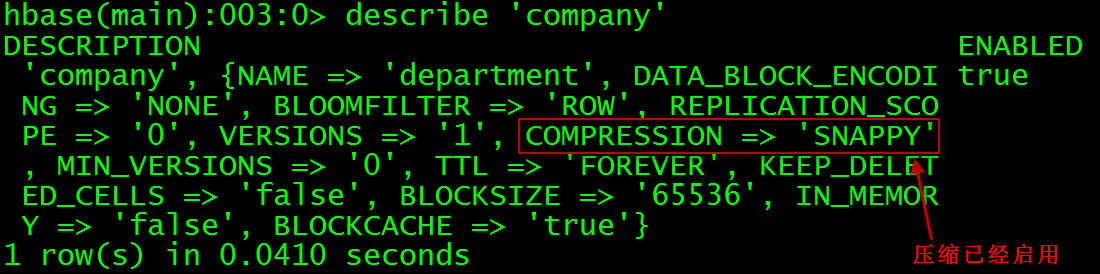
插入数据
> put 'company', '001', 'department:name', 'develop'
> put 'company', '001', 'department:address', 'sz'查询
> scan 'company'

4. Uber模式使用Snappy
配置了uber模式后使用上述的snappy压缩配置方法后mapreduce程序运行报错:
2015-06-17 04:27:48,905 FATAL [uber-SubtaskRunner] org.apache.hadoop.mapred.LocalContainerLauncher: Error running local (uberized) 'child' : java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCodeLoader.buildSupportsSnappy()Z
at org.apache.hadoop.util.NativeCodeLoader.buildSupportsSnappy(Native Method) at org.apache.hadoop.io.compress.SnappyCodec.checkNativeCodeLoaded(SnappyCodec.java:63) at org.apache.hadoop.io.compress.SnappyCodec.getCompressorType(SnappyCodec.java:132) at org.apache.hadoop.io.compress.CodecPool.getCompressor(CodecPool.java:148) at org.apache.hadoop.io.compress.CodecPool.getCompressor(CodecPool.java:163) at org.apache.hadoop.mapred.IFile$Writer.<init>(IFile.java:114) at org.apache.hadoop.mapred.IFile$Writer.<init>(IFile.java:97) at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.sortAndSpill(MapTask.java:1602) at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.flush(MapTask.java:1482) at org.apache.hadoop.mapred.MapTask$NewOutputCollector.close(MapTask.java:720) at org.apache.hadoop.mapred.MapTask.closeQuietly(MapTask.java:2012) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:794) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.LocalContainerLauncher$EventHandler.runSubtask(LocalContainerLauncher.java:370) at org.apache.hadoop.mapred.LocalContainerLauncher$EventHandler.runTask(LocalContainerLauncher.java:295) at org.apache.hadoop.mapred.LocalContainerLauncher$EventHandler.access$200(LocalContainerLauncher.java:181) at org.apache.hadoop.mapred.LocalContainerLauncher$EventHandler$1.run(LocalContainerLauncher.java:224) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745)这是因为在uber模式下无法加载到snappy的native,解决办法是在mapred-site.xml中添加如下配置:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>LD_LIBRARY_PATH=$HADOOP_HOME/lib/native</value>
</property>注:如果是CM安装的CDH版本hadoop则snappy的native在【/opt/cloudera/parcels/CDH/lib/hadoop/lib/native】目录下。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/234332.html原文链接:https://javaforall.net

![Spring Boot 使用 JAX-WS 调用 WebService 服务[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
