
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
RBF神经网络及拟合实例
RBF神经网络介绍
RBF神经网络结构
径向基函数(Radial Basis Function, RBF)神经网络是一种单隐含层的三层前馈神经网络,网络结构如下图所示

RBF神经网络模拟了人脑中局部调整,相互覆盖接受域(或者说感受域,Receptive Field)的神经网络结构。与BP神经网络相同,研究人员已经证明RBF神经网络能够以任何精度逼近任意非线性函数。
RBF神经网络算法
便于分析,记RBF神经网络的输入为m维,隐含层有 s 1 s_1 s1个神经元,输出层有 s 2 s_2 s2个神经元。
RBF神经网络隐含层神经元的激活函数为如下所示的高斯基函数
h j = exp ( − ∣ ∣ x − c j ∣ ∣ 2 2 b j 2 ) , j = 1 , 2 , . . . , s 1 h_j = \exp(-\frac{||\bm{x}-\bm{c}_j||^2}{2b_j^2}),j=1,2,…,s_1 hj=exp(−2bj2∣∣x−cj∣∣2),j=1,2,...,s1
其中, c j = [ c j 1 , c j 2 , . . . , c j m ] T \bm{c}_j=[c_{j1},c_{j2},…,c_{jm}]^T cj=[cj1,cj2,...,cjm]T为第j个隐含层神经元高斯基函数的中心向量, m m m表示网络输入 x \bm{x} x的维数, b j b_j bj为第j个隐含层神经元高斯基函数的宽度。与之前提及的BP神经网络中的sigmod函数不同,高斯基函数只在有限的范围内,输入是非零的,超过一定的范围,其输出则为零。
在一维情况下,不同的 c j \bm{c}_j cj和 b j b_j bj对高斯基函数的影响如下图所示
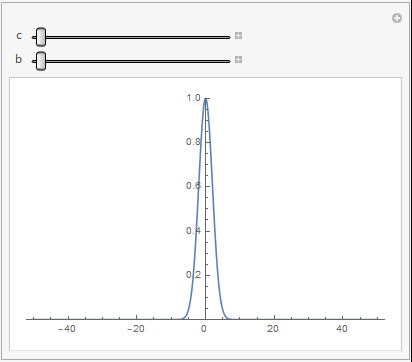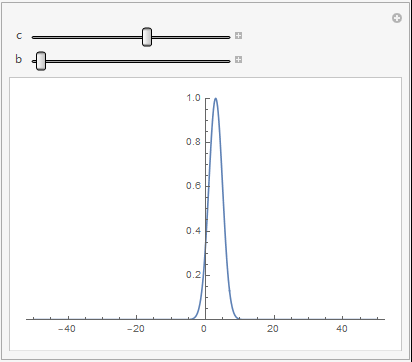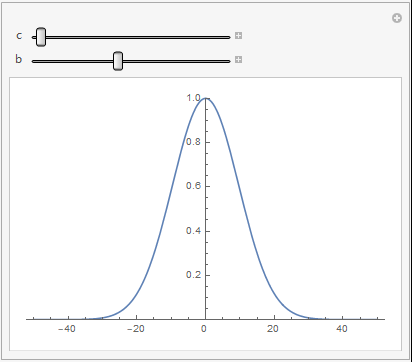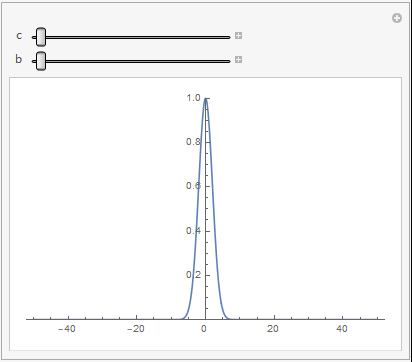
可以看到, b j b_j bj越大,高斯基函数的非零输出区域越大,表明对输入的映射能力越强。 c j \bm{c_j} cj表示非零输出区域的中心位置,输入离中心越近,其输出值会更大,表明高斯基函数对输入更加敏感。
RBF神经网络的输出为
y = W H \bm{y} = \bm{WH} y=WH
其中, W ∈ R s 2 × s 1 \bm{W}\in R^{s_2 \times {s_1}} W∈Rs2×s1为RBF神经网络输出层权值矩阵, H ∈ R s 1 H \in R^{s_1} H∈Rs1为隐含层输出, H = [ h 1 , h 2 , . . . , h s 1 ] T \bm{H} = [h_1,h_2,…,h_{s_1}]^T H=[h1,h2,...,hs1]T。
RBF神经网络逼近算法
相较BP神经网络,RBF神经网络结构更加简单,同时需要调节的参数也更少,只有输出层的权值矩阵 W \bm{W} W需要在训练过程中调节。与BP神经网络类似,我们可以以采用梯度下降法来调节权值矩阵。
定义RBF神经网络的估计误差指标为
E = 1 2 ∑ i = 1 s 2 ∣ ∣ e i ∣ ∣ 2 = 1 2 ∑ i = 1 s 2 ∣ ∣ y d − y ∣ ∣ 2 E =\frac{1}{2}\sum_{i=1}^{s_2}||e_i||^2= \frac{1}{2} \sum_{i=1}^{s_2}|| \bm{y_d}-\bm{y}||^2 E=21i=1∑s2∣∣ei∣∣2=21i=1∑s2∣∣yd−y∣∣2
其中, y d \bm{y_d} yd为期望输出。
对误差指标关于输出层权值矩阵 W \bm{W} W中元素进行求导得到
∂ E ∂ W i 0 = ∂ E ∂ e i ∂ e i ∂ y i ∂ y i ∂ W i 0 = − e i h i \frac{\partial E}{\partial W_{i0}}=\frac{\partial E}{\partial e_i} \frac{\partial e_i}{\partial y_i} \frac{\partial y_i}{\partial W_{i0}}=-e_ih_i ∂Wi0∂E=∂ei∂E∂yi∂ei∂Wi0∂yi=−eihi
那么,权值可按如下方式调节
Δ W i 0 = − η e i h i W i 0 ( k + 1 ) = W i 0 ( k ) + Δ W i 0 + α ( W i 0 ( k − 1 ) − W i 0 ( k − 2 ) ) \Delta W_{i0} = -\eta e_ih_i \\ W_{i0}(k+1) = W_{i0}(k)+\Delta W_{i0} + \alpha (W_{i0}(k-1)-W_{i0}(k-2)) ΔWi0=−ηeihiWi0(k+1)=Wi0(k)+ΔWi0+α(Wi0(k−1)−Wi0(k−2))
其中, η ∈ ( 0 , 1 ) \eta\in(0,1) η∈(0,1)为学习速度, α ∈ ( 0 , 1 ) \alpha \in(0,1) α∈(0,1)为动量因子。
采用RBF神经网络逼近非线性函数
采用RBF神经网络,逼近简单的正弦函数
y = s i n ( t ) y=sin(t) y=sin(t)
可知,采用的RBF神经网络输入和输出层神经元数量都为1,设置隐含层神经元数量为10个。
由于RBF神经网络采用的激活函数在有限区域内输出为非零,因此在设计RBF神经网络的时候,需要根据网络的输入来确定每个隐含层神经元激活函数的参数,即 c j c_j cj和 b j b_j bj。合适的网络参数能够提升网络的逼近效果和性能,而不合适的参数会导致神经网络训练失败,或者达不到想要的效果。
通常来说, c j c_j cj参数需要与网络的输入相匹配,要保证输入在高斯基函数的有效映射区域内;同样的,根据输入的范围和高斯基函数的中心,来设置一个合适的宽度参数 b j b_j bj。
在本例中,神经网络的输入为时间 t ∈ [ 0 , 10 ] t \in[0,10] t∈[0,10],因此取径向基函数中心和宽度为
C = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ] T B = [ b j ] 10 × 1 , b j = 1 , j = 1 , 2 , . . . 10 \bm{C} = [1,2,3,4,5,6,7,8,9,10] ^T \\ \bm{B} = [b_j]_{10\times 1},b_j = 1,j=1,2,…10 C=[1,2,3,4,5,6,7,8,9,10]TB=[bj]10×1,bj=1,j=1,2,...10
神经网络逼近结果
训练过程中误差收敛情况如下所示
将训练得到的神经网络进行验证
代码如下
%训练简单的RBF神经网络来拟合非线性函数
clear,clc
%% 生成训练数据
ts = 0.01;
u1 = 0;
y1 = 0;
for k=1:1000
u(k) = k*ts;
y(k) = sin(u(k));
end
len = length(u);
%% RBFNN初始设置
% RBFNN结构为1-10-1
n = 1;
s1 = 10;
s2 = 1;
c = (1:1:10); %高斯基函数中心
b = ones(s1,1).*2; %高斯基函数宽度
W = rand(s2,s1); %输出权值矩阵
DW = zeros(s2,s1);
Wt1 = zeros(s2,s1); %上一时刻权值阵
Wt2 = zeros(s2,s1); %上上时刻权值阵
H = zeros(s1,1); %隐含层输出
m = 500;
Error = zeros(m,s2);
%% 训练算法
e_tol = 1e-4;
irt_max = 20000;
e = ones(irt_max,1);
eta = 0.3;
alpha = 0.1;
for cnt = 1:irt_max
idx_rand = randperm(1000);
u_train = u(idx_rand);
y_train = y(idx_rand);
% 前向计算
for i = 1:m
x = u_train(i);
for j = 1:s1
H(j) = exp(-(x-c(j))^2/(2*b(j)^2)); %隐含层计算
end
y_etm = dot(W,H); %神经网络预测值
Error(i) = y_train(i) - y_etm;
% 权值更新
Wt = W; %当前时刻W
for j = 1:s1
DW(j) = eta*Error(i)*H(j);
W(j) = Wt(j) + DW(j) + alpha.*(Wt1(j)-Wt2(j)); %W update
end
Wt2 = Wt1;
Wt1 = Wt;
end
% 检测是否达到误差要求
e(cnt) = (norm(Error))^2/2/len;
if e(cnt) < e_tol
break;
end
end
检验训练结果
%% 检验训练结果
idx_vad = (1:20:1000);
u_test = u(idx_vad);
for i = 1:length(idx_vad)
x = u_test(i);
for j = 1:s1
H(j) = exp(-(x-c(j))^2/(2*b(j)^2)); %隐含层计算
end
y_test(i) = W*H; %神经网络预测值
end
figure(1)
plot(u,y,'b--','LineWidth',1);
hold on
plot(u_test,y_test,'r-*');
legend('reference','estimation')
grid on
figure(2)
plot(e(1:cnt));
grid on
legend('error')
%% 检验2
for i = 1:1000
u_test2(i) = i*ts*5;
y_test2(i) = sin(u_test2(i));
x = u_test2(i);
for j = 1:s1
H(j) = exp(-(x-c(j))^2/(2*b(j)^2)); %隐含层计算
end
y_vad2(i) = W*H;
end
figure(3)
plot(u_test2,y_vad2,'r','LineWidth',0.75);
hold on
plot(u_test2,y_test2,'b--','LineWidth',1)
grid on
legend('estimation','reference')
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/234530.html原文链接:https://javaforall.net


