
DeepSeek-OCR实战是一个系列文章,包含了从基础运行环境搭建到应用接入全过程。本章介绍DeepSeek-OCR如何本地部署

前面在《DeepSeek-OCR实战(01):基础运行环境搭建》中已经安装好了 conda :
注意:在安装flash-attn==2.7.3时如果出现问题,可以到github的flash-attention官方(https://github.com/Dao-AILab/flash-attention/releases)下载对应版本的.whl官方包。
简单来说,FlashAttention(flash-attn)是一个专门用于DeepSeek 教程优化Transformer模型中注意力机制(Attention)计算的库,它能显著提升计算速度并大幅减少GPU显存消耗。对于像DeepSeek-OCR这样庞大的模型来说,安装它是比较重要的。
如何选择 flash-attn的版本:
- 版本文件名中的第一部分(例如 、)为 CUDA 版本,本地CUDA版本使用 命令查看(本地为:11.8版本)
- 版本文件名中的第二部分(例如 、、)为 pytorch 版本。本地 pytorch 版本可以通过 命令查看(本地为:2.6.0+cu118)
- 版本文件名的第三部分(例如 )为 Python 版本,选择本地 Python 版本即可。本地 Python 版本可以通过 命令查看(本地为:3.12)
所以这里就应该下载:这个版本
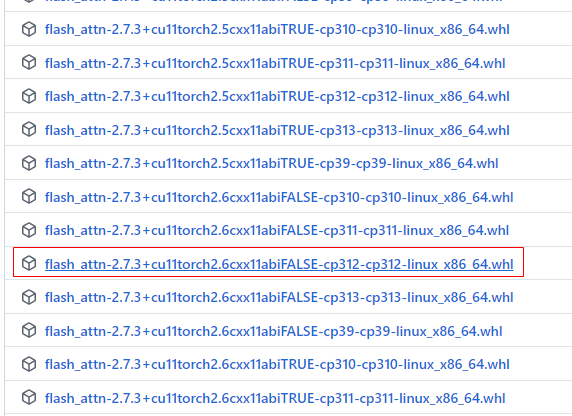
下载后,上传到 ,然后离线安装:
经过测试, 我得 2080 Ti 显卡不支持 flash_attn,如果你的显卡支持,可以安装它
可以到魔搭社区下载模型文件
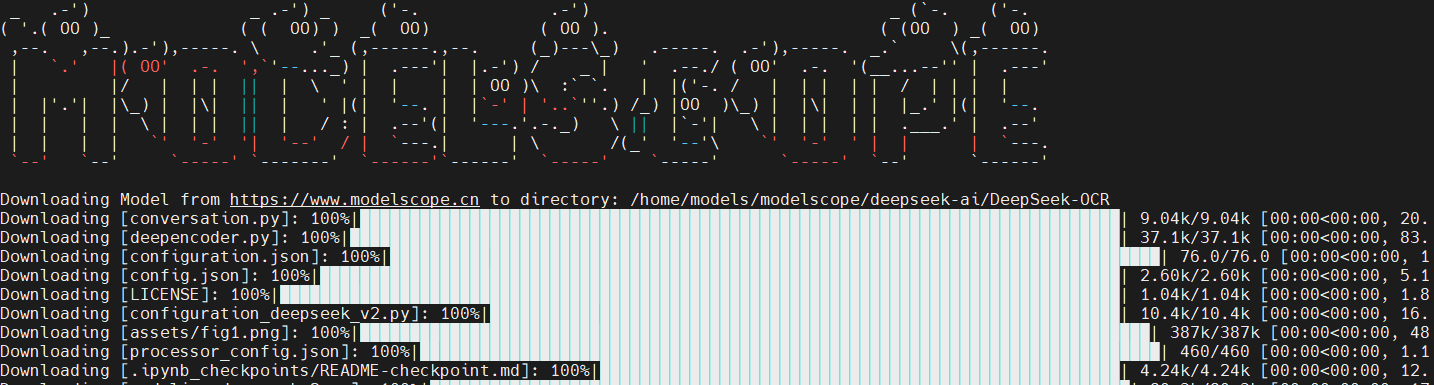
我们大概等待几分钟后就看到下载好的模型文件了:

可以使用huggingface上官方给出的gradio页面模板,它可以快速上手
进入 目录,修改其中的web启动代码app.py:
将模型的加载路径改为本地路径 以及lunch加载函数中设置
启动脚本:
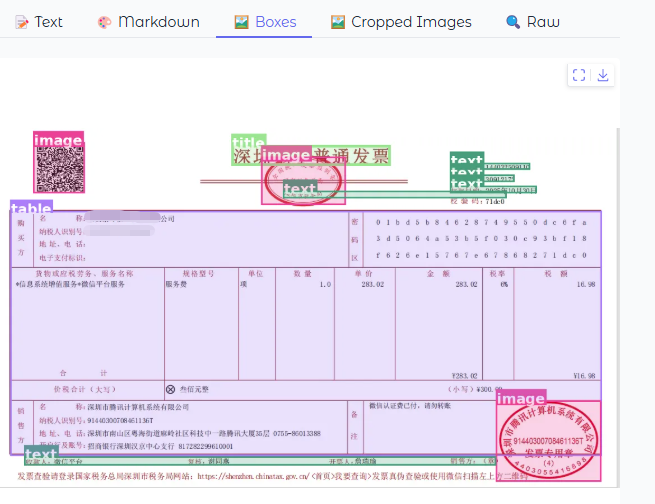
访问页面,上传一个发票图片,此时已经可以正常工作了:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/235903.html原文链接:https://javaforall.net


