



- 文本感知:最基础的感知形式,通过用户输入的文本获取信息。
- 多模态感知:如果我们想将图片或PDF传给AI,或者与AI进行语音交流,早期的解决方案是利用OCR等工具将非文本内容转换为文本再输入给大模型。但这种方法会丢失大量信息,如图片的颜色布局、声音的语气语调等。
- 视觉理解:2023年GPT-4V(Vision)开启了多模态模型的初阶状态,使模型能够直接理解图片上的所有信息,包括颜色、图形等。
- 综合感知:到2023年底,GPT-4o等模型进一步整合图片、声音等多模态数据,能够理解和识别声音中的语气语调和图片细节信息。
- 视频感知:后来还出现了能够识别视频时序的多模态模型。

- 直接回答:早期大模型回答问题时”张口就来”,面对需要推理的问题(如数学题)经常出错。
- 思维链方法(CoT):研究人员发现,让模型在给出最终答案前先主动拆解问题(例如第一步考虑做什么,第二步做什么,最后综合得出结论)能够提高准确性。正如中国谚语所说:”无谋不成事”。
- 多思路规划:在思维链的基础上,有人提出了让大模型考虑多种不同思路,选择最佳方案的方法。
- 多智能体协作(MOTIENT):当单个模型规划能力有限时,研究者提出了让多个AI各司其职协作完成任务的方案。例如,一个负责规划,一个负责推敲检查,循环迭代完成任务。
- 内化推理模型:为了让大模型真正具备自主规划能力,OpenAI研发并发布了o1o系列模型,让大模型内化学会在每次回答问题前进行自主推理。虽然当时有不少人对o1o模型持批评态度(认为其速度慢、写作质量不佳),但这为后续发展奠定了基础。
- 端到端训练:2024年2月,OpenAI推出了DeepResearch(售价200美元),背后使用的是端到端训练过的o3模型。这意味着模型可以自主决定何时搜索信息、何时整理现有信息、何时进行深度搜索并分析总结,整个过程完全由其自己控制,不依赖预设工作流或人为指定步骤。
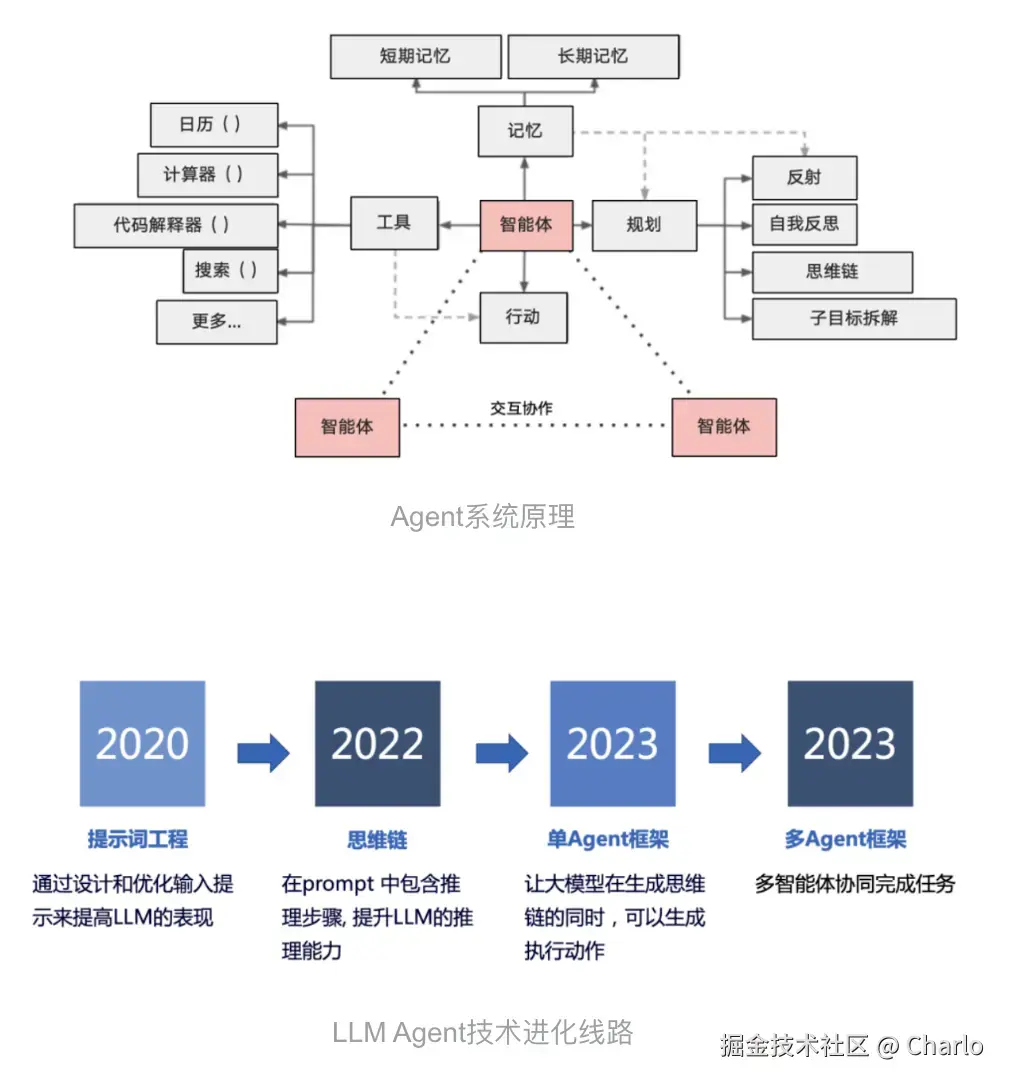
- API调用:大模型最早与外界沟通的基础方式是通过API调用。研究者通过提供示例进行监督微调,让模型学会生成API调用文本。当模型生成特定格式的文本时,系统会调用相应功能函数并将结果返回给模型。这就是Function Calling功能,GPT的插件功能、代码解释器以及大多数agent搭建平台都依赖于此。
- 计算机控制:2023年10月,Anthropic发布了Computer Use功能,训练大模型从视觉上理解电脑屏幕并进行操作。虽然初期成功率仅有10%左右(相比人类的70%),但开创了直接控制电脑的可能性。
- 浏览器控制:如果只让大模型控制浏览器,实现难度会降低。Computer Use发布后,开源社区开发了Browser Use,通过传统的网页自动化工具(如Playwright)间接实现模型控制浏览器的能力。这也是MANOS操作网页的技术来源,类似工具还包括OpenAI的Operator和Computer Use工具。
- 统一接口标准:2023年11月,Anthropic推出了Model Context Protocol (MCP)协议,统一了工具调用接口标准。简单来说,原本每个工具都需要单独开发接口,而MCP则提供了通用的接口规范,大大简化了工具接入过程。OpenAI最近发布的Agent SDK和新的Response API也是从行业标准和基建角度推动工具使用的举措。

- 上下文长度扩展:早期大模型的上下文长度(短期记忆)非常有限,稍微多聊几句就会”忘记”前面的内容。业界一度竞相增加上下文长度,以提升短期记忆能力。
- 检索增强生成(RAG):仅靠上下文长度扩展仍不足以满足长期记忆需求。RAG技术将大模型需要记住的知识存储在外部向量数据库中,需要时再检索相关内容。这相当于给大模型添加了长期记忆外挂,同时也能减少”幻觉”问题。
- 记忆模块:对于智能体执行任务过程中产生的信息,系统会对前面发生的事情进行总结并存储,定期回顾以形成完整的记忆模块。
- 高级记忆机制:相比人类的复杂记忆机制(如遗忘机制、注意力机制等),AI的记忆系统仍有提升空间。研究人员正在尝试新方法,如DeepSeek开发的NSA稀疏注意力机制,以解决模型的记忆问题。
- 编程智能体:如Cursor、Devin等,支持从需求出发自行编写代码、创建文件和部署网页。
- 调查智能体:如DeepResearch、Google的DeepSearch等。
- 设备操控智能体:如AutoGLM、iPhone的辅助功能等,以及谷歌尚未发布的全自动项目(其演示效果甚至比MANOS更为出色)。
- 垂直行业智能体:如医疗智能体、数据分析智能体和风险评估智能体等,在特定行业中发挥重要作用。

- 任务规划:收到任务后,MANUS首先创建文件并写入待办清单,这表明有一个模型在进行规划。
- 终端操作:使用命令行创建文件,类似于Cursor的功能。
- 多智能体协作:MANUS采用多智能体并行执行任务,不同模型按流程分工协作,彼此间信息共享有限。
- 信息搜索:通常第一步是调用搜索工具获取信息。
- 网页浏览:使用Browser Use功能访问网页获取信息,如浏览百度百科。
- 文件创建与管理:创建多个文件并写入信息,完成任务后在待办清单中标记完成项。
- 资源获取:搜索并下载免费图片。
- 代码开发:由专门的开发智能体(如Claude 3.5)编写代码。
- 项目部署:完成后向用户确认部署状态。

- 过程展示窗口:显示执行过程和交付结果,类似Claude的Artifacts
- 搜索工具调用:基础的信息获取能力
- 网页浏览:基于开源的Browser Use项目,但信息错误概率较高
- 命令行操作:在远端虚拟机中执行指令
- 多轮搜索:类似DeepSearch,但可能基于预设工作流
- 代码编写与部署:能编写代码并部署HTML等静态页面,但难以部署复杂项目(如Next.js)
- OpenManos:由MetaGPT团队开发,GitHub星标最高,使用相对简单。
- OWL:在Gaia榜单上得分最高的开源智能体项目。
- OpenManus和OWL:属于初期实验项目,主要适合交流学习。
- MANUS:实验性产品,实际可用程度有限,远不及社交平台上的夸张宣传(如”革命性”、”硅谷无眠”等)。适合制作简单的小游戏、网页等演示项目,但不适合严肃生产环境。
- 垂类智能体:在特定场景下表现更好。例如,相比MANuS,DeepResearch在调研任务中提供的结果更清晰、可溯源、准确度更高、条理更清晰。甚至一些简单的搜索任务,使用DeepSeek配合联网搜索的结果也不会比MANUS差。


- 基础模型能力的提高
- 工具能力的建设
- RAG质量的提升
- 算力成本的降低
- 用户需求的明确
- 开发门槛的降低
- 社区的壮大
- 挑战:可能替代一些冗长繁琐的工作,对不积极适应变化的岗位构成威胁。
- 机遇:大幅提升工作效率,使原本一个月完成的任务可能在一天内完成;让原本因技能限制无法完成的工作变为可能,如不懂编程的人借助编程智能体开发产品。
- 从技能掌握转向更高层次的规划和判断能力
- 提出问题、辨别答案的能力比解答问题更重要
- 跨领域知识广度变得更加关键
- 融会贯通能力可能比专精度更重要
- 学习如何与AI有效交流
- 如何监督AI避免不当行为
- 如何处理AI错误带来的风险和后果
- 如何解决AI使用过程中的隐私问题

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/237015.html原文链接:https://javaforall.net


