


在学习之前:
- ✅ 具备基础Python编程能力、对大模型有一定概念
- ✅ 安装 Python 编程环境(Jupyter / PyCharm / VS Code){本文将使用Jupyter 作为基础环境}
- ✅ 具备基础MarkDown语法基础,完成每次学习笔记
特别感谢本教程各位开源贡献者及文睿的支持
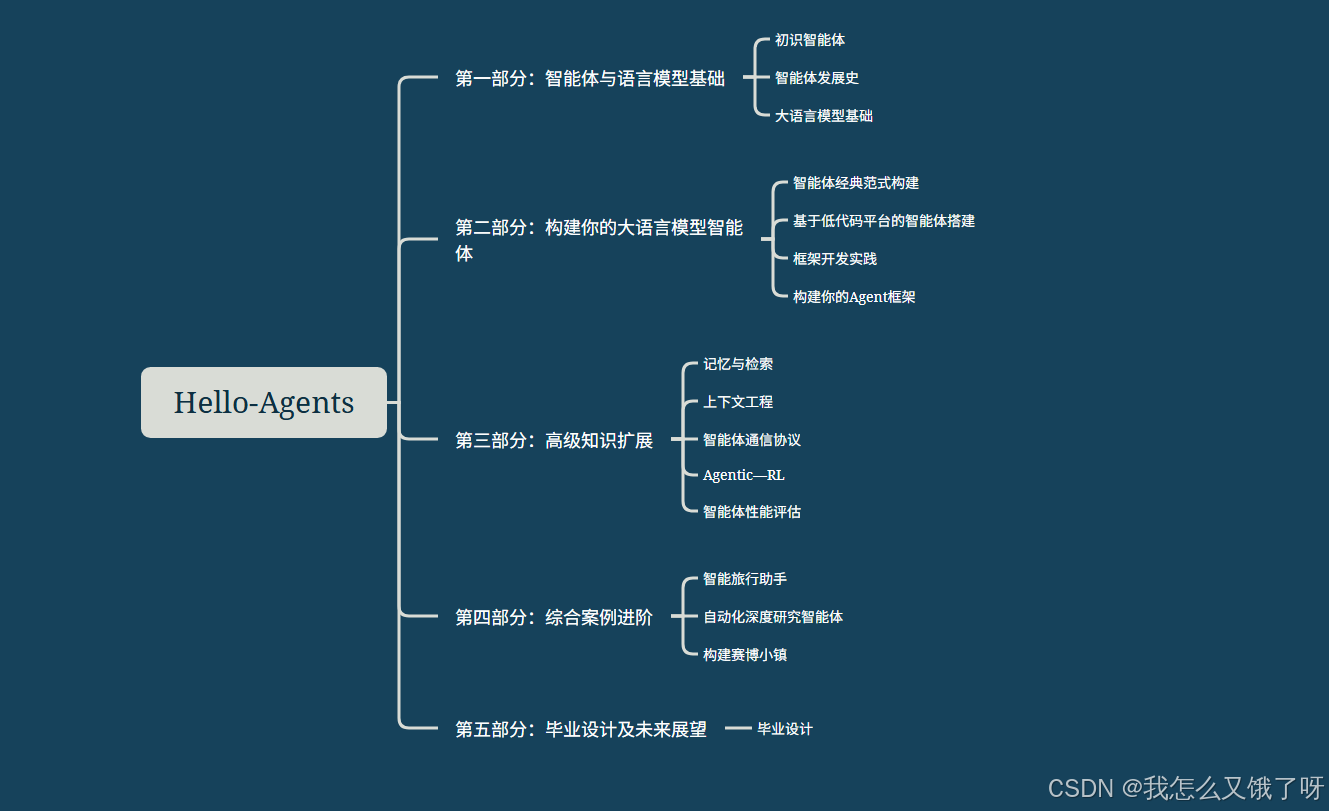
2025 年被视为“Agent 元年”,多智能体协同(MAS)成为释放大模型潜能、解决真实复杂问题的关键。然而,网上我们可见的框架纷飞,能够进行系统学习的材料却非常稀缺,此次Hello-Agents 就可以作为链接初学者入门的桥梁,用第一性原理+实战,把开发者从“调 API 的用户”可自行模拟场景的创造者,带大家从零搭出属于自己的多智能体应用。简单来说,会聊天的大模型像装满知识的“大脑”,而 Agent 就是给大脑装上“手脚”和“团队”,让它能自己接单、查资料、写代码、互相讨论,把活干完。学 Agent 别急着追新框架,先弄懂“大脑怎么想、手脚怎么动、队员怎么配合”这三件事,再结合本教程中的一些小项目练手,一点点把流程跑通,即可食用(*╹▽╹*)。。。
什么是智能体?
智能体不是更会聊天的 GPT,而是一套“大模型驱动、具备自主经济学结构且没有感情的数字工人”
它最核心的专业组件有三件:
- 规划模块,通常用 ReAct、Chain-of-Thought 或树搜索算法把用户的一句话拆成可验证的子目标;
- 工具调用接口,通过 JSON Schema 或 OpenAI 的 parallel function call 把外部 API、数据库、Python 解释器封装成可执行动作空间(Action Space);
- 记忆与反思机制,利用向量数据库做语义检索,再用 Reflexion、Self-Critique 等提示策略让模型对自己的轨迹进行梯度无关的“元学习”。
这三件套结束后,Agent 就不再只是“生成答案”,而是“生成动作序列”,在环境中观测(Observation)→ 推理(Reasoning)→ 行动(Action)→ 获得奖励(Reward),形成完整的 POMDP(部分可观察马尔可夫决策过程)回路(这里使用课件的图做以解释,简单来说就是
感知——思考——行动)
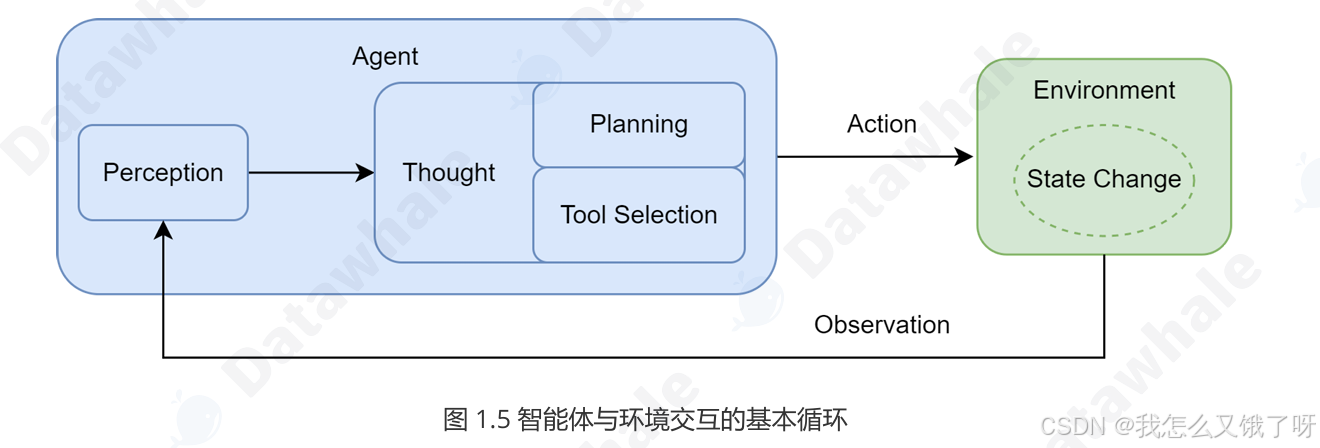
多智能体系统进一步把单点智能体升级为“数字组织”。每个 Agent 拥有角色画像(Persona)、私有记忆池(Private Memory)和通信协议(如 ACL、KQL、自然语言信道),通过共识算法(ReAct-Deliberation、LLM-Debate)或博弈策略(Shapley 分配、拍卖机制)完成分工、谈判、甚至互相审计。这就把 LLM 的“涌现”从 token 层提升到系统层——群体智能(Swarm Intelligence)出现,算力即产能。 {这里说的可能有点抽象,大家可以先忽略,不影响后续学习}
安装必要的第三方库(包括requests、tavily-python、openai)
以下是教程样例中的代码:

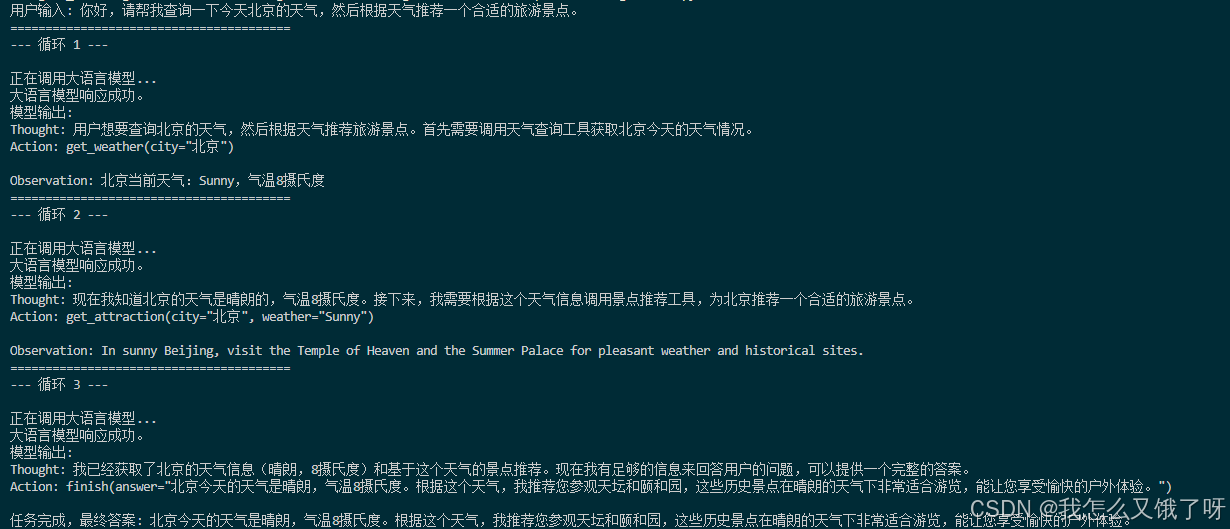
自己第一次把 Agent 跑通时震撼是:
“原来我不是在调接口,而是在雇一个 24h 连轴转的初级算法工程师。”
给它一篇 arXiv 链接,它能自动拆 related work、跑实验、画曲线、写 README,还把 bug 清单发我邮箱。那一刻我深刻体会到,Agent 的真正杀伤力不在于“更像人”,而在于“把人最值钱的认知流水线封装成可复制的服务”。
当然,幻觉(Hallucination)、工具误调用(Tool Misuse)、目标漂移(Goal Drift)仍是技术壁垒0,根据以往的项目工程经验:
- 用“双塔”验证——让 Planner 与 Checker 两个独立模型互相对齐,降低级联错误;
- 把奖励函数拆成“硬规则 + 软语义”两层,硬规则用 Python assert 不可妥协,软语义用 cosine 相似度给 GPT-4 打分;
- 记忆分三级:热上下文(2k token)、温向量(24h 内)、冷归档(对象存储),既省成本又防上下文被“记忆淹没”。
Agent 是大模型从“概率生成器”走向“目标驱动的因果执行器”的桥梁,谁先能把这套“认知-动作”闭环低成本地跑通,谁就拥有下一个十年的自动化红利。
总结材料原文中写的很好,这里直接写入笔记:
- 智能体如何工作? 从基础上学习了智能体与环境交互的运行机制,这个持续的闭环是智能体处理 信息、做出决策、影响环境并根据反馈调整自身行为的基础。
- 如何构建智能体?以一个“智能旅行助手”为例,构建了一个完整的、由真实 LLM 驱 动的智能体。
:
一台符合冯
·
诺依曼结构的超级计算机
,拥有高达每秒
2EFlop
的峰值算力
:
特斯拉自动驾驶系统
在高速公路上行驶时,突然检测到前方有障碍物,需要在毫秒级做出刹车或变道决策
:
AlphaGo
在与人类棋手对弈时,需要评估当前局面并规划未来数十步的最优策略
:
ChatGPT
扮演的智能客服
在处理用户投诉时,需要查询订单信息、分析问题原因、提供解决方案并安抚用户情绪
Agent 智能体
- A:纯硬件,无感知无目标 → 非智能体
- B:车端感知-决策-控制闭环 → 物理实时智能体
- C:自对弈深度规划 → 软件强化学习智能体
- D:LLM+插件主动调用 → 工具增强对话智能体
Case A:2 EFlop 超级计算机
- 自主程度:零,机器只是被动执行人类编好的指令流,没有内置目标
- 环境交互:零,不接传感器,也不输出物理动作
- 目标导向:无,没有效用函数或奖励
- 不是智能体,只是一台“算力引擎”,属于通用计算 substrate,可为智能体提供推理加速
Case B:Tesla 自动驾驶高速避障
- 自主程度:高,毫米波+视觉+激光雷达实时感知,100 ms 内完成决策→转向/制动,无需人类接管
- 环境交互:强,输入连续交通场景,输出横纵向控制信号,直接影响车辆位姿
- 目标导向:明确——最小化碰撞概率+遵守交规+保持乘坐舒适
- 记忆与推理:短时记忆,但无长期策略学习
- 是智能体,类型:
- 按环境→物理智能体
- 按任务→实时反应型+ 部分规划型
- 按数量→单智能体
Case C:AlphaGo 对弈
- 自主程度:高,人类仅落子一次,AlphaGo 自主完成局面评估、蒙特卡洛树搜索
- 环境交互:数字环境(棋盘),输出动作是合法落子坐标
- 目标导向:最大化最终胜率
- 记忆与推理:长期策略规划,并记录完整博弈树
- 是智能体,类型:
- 按环境→软件/游戏智能体
- 按推理深度→强规划型
- 按学习方法→强化学习智能体
- 按对抗性→对抗型智能体
Case D:ChatGPT 智能客服
- 自主程度:高,给出投诉目标后,它能自主决定调用订单 API、生成回复、多次对话,无需人工逐句审核
- 环境交互:数字环境——通过插件读取订单数据库、知识库,再返回文本动作
- 目标导向:隐性——降低用户负面情感+提供可行方案,可用满意度作为奖励 proxy
- 记忆与推理:支持多轮上下文,可外挂向量记忆实现跨会话追溯
- 工具调用:显式调用 REST 函数,符合 ReAct 范式
- 是智能体,类型:
- 按环境→数字/信息智能体
- 按能力组合→工具增强语言智能体
- 按架构→单智能体,可扩展为多智能体
- 按交互方式→对话式智能体
环境特性分析
- 部分可观察,无法直接观测“真实疲劳度”“潜在关节损伤”“当日工作压力”,只能以 HR、HRV、表情、语音为带噪线索
- 随机性,同一训练强度下,次日 HR 恢复、肌肉酸痛、情绪状态均存在随机波动;传感器本身带白噪声
- 动态性,环境状态随时间持续变化:用户心率实时升降、血糖下降、地面突然湿滑、电话打断,Agent 必须持续重规划
- 连续性,心率、角度、力量曲线都是连续值;动作空间(阻力增减、语音速度)也是连续区间
- 序列性,当前动作是否标准会影响下一组能否执行、甚至影响数天后的受伤风险;奖励需考虑长期累积
- 多目标,需在“效果 vs 安全 vs 愉悦”之间做权衡,属于多目标决策
- 人机协作,一次训练约 60 min,可视为一段 episode;但整个健身周期 8-12 周,人可随时口头喊降低强度,Agent 必须在线响应
- 时空异构,用户体能随训练提升,同一强度刺激产生的效果递减,策略需定期微调
方案A:固定流程人工审核确定性高、可解释、合规友好、上线快但维护成本高
方案B:智能体的优点是端到端学习、千人千面、持续进化、人工节省,缺点也很明显,需要的数据或算力门槛高。
适用边界
- 单量<1万/日、监管强、规则稳定 → Workflow。
- 单量>5万/日、交易复杂、数据底座成熟 → Agent。
方案C:分层决策架构
规则层兜底硬约束 → Agent层输出“动作+置信度+可解释特征” → 置信度≥98%自动执行,80–98%人机协同,<80%强制人工;反馈闭环持续RLHF。实现自动率↑、成本↓、风险小,所以我选C
提示:思考如何修改 Thought-Action-Observation 循环来实现这些功能。 添加一个”记忆”功能,让智能体记住用户的偏好(如喜欢历史文化景点、预算范围等) 当推荐的景点门票已售罄时,智能体能够自动推荐备选方案 如果用户连续拒绝了 3 个推荐,智能体能够反思并调整推荐策略
不改动 LLM 调用方式,仅通过“记忆槽位 + 新 Action + 反射计数器”即可实现
在 Thought 前追加 System Prompt 片段:
计数器
- 记忆:Profile 持久化 + System Prompt 注入,零侵入 LLM。
- 备选:新增 Action,以 Observation 状态驱动二次搜索。
- 反射:拒绝计数器 ≥3 时,在 Thought 前插入强制提示,引导 LLM 主动调整策略。
整个 TAO 循环依旧保持“黑盒 Thought → 可观测 Action → Observation”节奏,仅通过“外部状态 + 提示工程”可实现
Hello-Agents-V1.0.0-
发布者:Ai探索者,转载请注明出处:https://javaforall.net/238699.html原文链接:https://javaforall.net


