


©PaperWeekly 原创 · 作者 | 李鹏翼
单位 | 天津大学郝建业课题组
研究方向 | 演化强化学习
本次介绍的是由天津大学强化学习实验室(http://icdai.org/)提出多智能体进化强化学习混合框架 RACE。该框架充分融合了进化算法与多智能体强化学习用于多智能体协作,并首次在复杂控制任务上证明了进化算法可以进一步提升 MARL 的性能。目前代码已经开源。

论文题目:
RACE: Improve Multi-Agent Reinforcement Learning with Representation Asymmetry and Collaborative Evolution
论文链接:
https://proceedings.mlr.press/v202/li23i.html
代码链接:
https://github.com/yeshenpy/RACE

1.1 Multi-Agent Reinforcement Learning
在多智能体强化学习(MARL)中,各个智能体与环境以及彼此进行交互,收集样本并接收奖励信号来评估它们的决策。通过利用价值函数逼近,MARL 通过梯度更新来优化策略。然而,MARL 经常面临以下挑战:
➢(Low-quality reward signals,低质量的奖励信号)奖励信号通常质量较低(例如,具有欺骗性、稀疏性、延迟性和只有 team level 的奖励信号),这使得获得准确的价值估计变得非常困难。
➢(Low exploration for collaboration,合作的探索性差)由于多智能体策略空间巨大,基于梯度的优化方法很容易陷入次优点,难以高效地探索多智能体策略空间,使得协作困难。
➢(Non-stationarity,非稳态性)由于智能体同时学习并不断地相互影响,打破了大多数单智能体强化学习算法所基于的马尔可夫假设,使得优化与学习过程过程不稳定。
➢(Partial observations,部分观测)大部分多智能体场景下都是部分可观测的,智能体无法得知其它智能体的状态以及相关信息,使得策略优化变得更加具有挑战性。
1.2 Evolutionary Algorithm
进化算法(Evolutionary Algorithm,EA)模拟了自然的遗传进化过程,不依赖于梯度信息进行策略优化,并已被证明在与强化学习(RL)竞争中表现出色。与通常仅维护一种策略的强化学习不同,EA 维护一个个体的群体,并根据策略适应度进行迭代演化。适应度通常被定义为一些回合的平均蒙特卡洛(Monte Carlo,MC)回报。
进化算法(EA)具有几个关键优势:
➢(对奖励质量不敏感)EA 不需要强化学习价值函数逼近,而是根据适应度,即累积奖励,直接对群体中的个体进行进化。这使得 EA 对奖励信号质量相对不敏感。
➢(避免非稳态问题)EA 在问题的形式化中不依赖于马尔可夫性质,并从团队的角度演化策略,从而避免了 MARL 中遇到的非稳态性问题。
➢(探索能力,鲁棒性,收敛性强)EA 具有强大的探索能力、良好的鲁棒性和稳定的收敛性。
下图是一个简化过的 EA 优化流程。
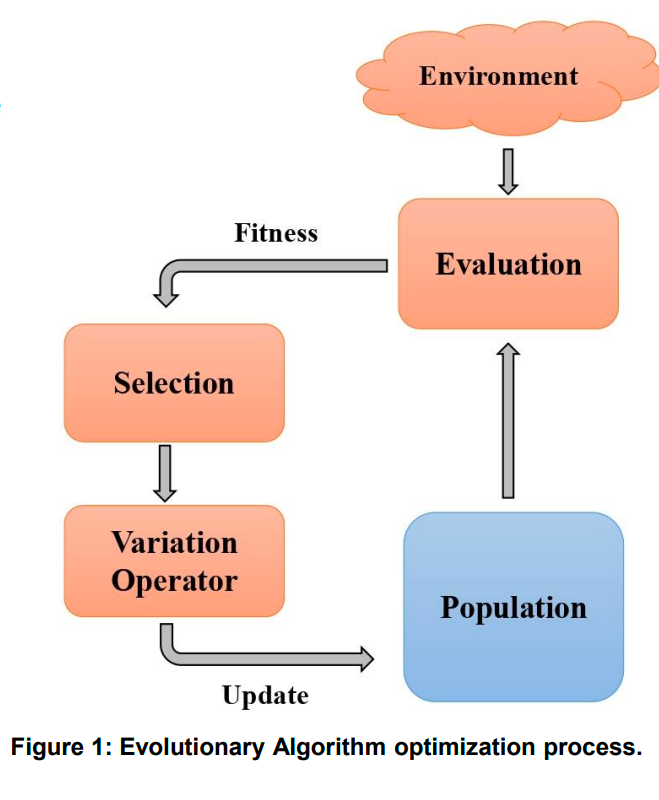

Motivation
➢(Complementarity,互补性)正如上面所提到的,进化算法(EA)提供了许多优点,可以弥补多智能体强化学习(MARL)的缺点。
➢(Research Gap,研究空白)然而,在复杂的多智能体协作任务中,如何有效地将这两种方法进行整合尚未得到深入研究。当前已有的一些工作主要都在简单的任务中进行验证,而在复杂协作场景没有高效方案的支撑。
因此,我们提出了一个新的混合框架,称为 “Representation Asymmetry and Collaborative Evolution”(RACE),将 EA 与 MARL 结合起来实现高效的协作,并将表征学习引入到了 MARL 领域中。

3.1 Representation-Asymmetry Team Construction (MARL+EA的Team架构)

RACE 是 MARL 与 EA 算法的结合体,因此相较于常规的 MARL 算法如 QMIX,MADDPG 等,RACE 额外引入了一个 team 的 population(种群)。通常情况下,每个 team 为决策和优化维护相互独立的策略。然而,这种独立的策略构建限制了团队之间的知识共享,并使得在大规模策略空间中进行探索变得低效。
为了实现高效的知识共享和策略探索,我们沿用了 ERL-Re^2(ERL-Re2, ICLR 2023)的分层架构并提出了 Representation-Asymmetry Team Construction(RATC),具体来说,我们会维护 个 team,不同 team 中用于控制相同 agent 的策略由共享的观测编码器与独立的策略表征组成:(参照上图更容易理解)

该表达式代表第 个 team 中的第 个策略。其中 是激活函数, 是状态表征编码器, 是线性策略表征。
形式上,我们总结了 RACE 中个体、团队和群体的构建如下:

3.2 Shared Observation Representation Learning(表征学习)
3.2.1 Value Function Maximization(VFM,解决知识迁移与共享问题,压缩策略空间)
通过上述 Team Construction,所有策略在线性策略空间中学习协作,这提出了两个要求:
(1):共享的观测表征编码器 Z 应该提供有关协作和任务的有用知识;
(2):这些知识需要对所有 team 的学习都有推动作用,而不仅仅是对特定team有益。
为了实现这一点,我们提出通过对所有 team 中相应策略的价值函数进行最大化(Value Function Maximization)来学习共享的观测表征编码器 。
具体而言,我们需要为种群中的每一个 team 都学习一个价值函数用于最大化,但是为了节省训练资源。我们额外学习一个 Policy-extended Value Function Approximator(简称 PeVFA)θ ,通过将 team 的策略表征作为额外输入达到只需要维护一个 value function 就能达到价值泛化,估计团队策略表征 价值的目的;对于多智能体强化学习(MARL)团队,保留传统的集中式评论家 ψ。以下是 θ 和 ψ 的损失函数的形式化表达式:

因此,对于共享的观测表征编码器,Value Function Maximization(VFM)的损失函数可以被定义为:

3.2.2 Value-Aware Mutual Information Maximization(VMM,解决PO以及非稳态问题)
然而,仅仅使用价值信息是不够的,因为在 MAS 中,大多数任务都是部分可观测的,智能体无法访问全局信息,因此在执行和学习阶段出现了非稳态的现象。因此,我们首先提出通过最大化共享的观测表征 ϕ 和全局状态 之间的互信息(MI)来使 反映全局信息,从而减轻部分观测带来的问题。
然而,使用低质量状态最大化 MI 已经被证明可能会导致共享的观测表征受到来自较差协作全局信息的负面影响,从而导致次优性(PMIC, ICML 2022)。为此,我们提出了 Value-Aware MI Maximization 方法,将优质的全局信息提取到 中。具体来说,我们首先使用互信息神经估计(Mutual Information Neural Estimation,MINE)来近似表征 和状态 之间的互信息下界,如下所示:

其中, 是智能体 在时间 的共享的观测表征, 是联合概率分布, 和 是边缘分布。ω 是一个具有参数 ω 的神经网络, 。我们可以使用公式 3 中的互信息下界 来近似互信息,并将其最大化,以将全局信息提取到 中。
值得注意的是, 等于 的期望值,其中 ωω。因此 可以看作是互信息的每步(t)信号,然后可以选择性地最大化它们,以将优质状态提取到 中。
为了实现最终目标,我们使用一个值函数 ζ 来估计所有团队在状态 上的最佳回报。我们通过最小化以下损失来实现它:

应该被定义为在状态 下由所有团队采取的行动的最大目标值。为了减少计算开销,我们通过仅考虑由 MARL 团队和从群体中随机选择的团队采取的行动获得的最大目标值来近似它。
因此, 可以定义为 ψπθπ,其中 ψπ 和 θπ 可以直接利用在优化公式 1 时获得的中间结果。随后,我们使用 ζ 的归一化值作为 的权重。Value-Aware MI Maximization 的损失可以定义如下:

直观地说,通过最小化上述公式(5),共享的观测表征将捕获更多具有高值的全局信息,而不是具有低值的信息。
最终,ϕ 的损失函数定义为:

其中 是一个超参数,用于平衡 Value-Aware MI Maximization 损失的影响。
3.3 Improving MARL with Collaborative Evolution (演化提升,提升探索能力,鲁棒性,收敛性)
由于 Value Function 和 Value-Aware MI 最大化的作用,共享的观测表征不仅提供与协作和任务相关的知识,构建了有利于高效探索的策略空间,还捕获了高质量的全局信息,从而缓解了部分观测带来的挑战。
基于共享的观测表征编码器 ϕ,控制相同智能体的不同团队的策略在线性策略空间 ϕ 中优化其策略表征比在原始非线性策略空间中更高效。接下来,我们详细介绍如何在线性策略空间中实现协作演化。
在演化过程中,RACE 首先对种群中的 n 个团队进行评估,并选择表现最好的团队作为精英团队。然后进行交叉和变异。对于交叉,应该选择两个团队。精英团队作为一个父代产生子代。另一个父代通过锦标赛机制(3 选 1,存储最优的个体)选择(从 3 个随机选择的团队中选择表现最好的团队)来确定。没有被选为父代的团队将由子代替换。此外,所有非精英团队都有一定的变异概率。
为了实现更高效的演化,我们为 Team 和 Individual 探索设计了新的交叉和变异方式。对于 Team Exploration,我们随机交换在两个选择的团队中控制相同智能体的个体策略表征,促进更好的 Team Composition 的探索。对于 Individual Exploration,我们对所选 Team 的一些策略表征引入随机参数扰动,推动发现更好的智能体控制策略。这些操作的形式化表征如下:

其中 和 是两个选择的 team, 和 是从智能体索引集合 ,, 中随机采样得到的子集, 是添加高斯噪声(或重置)特定参数的扰动函数。我们用 来表征带有索引 的团队的策略表征子集。由于智能体级别的操作,种群可以实现更高效和稳定的演化,并且在团队和个体上具有更直观的语义含义。
在演化过程中,种群高效地探索策略空间以发展协作策略。此外,整个种群演化过程中产生的样本可以用于训练多智能体强化学习(MARL)团队。MARL 团队的学习过程,表示为 ,遵循 MARL 的标准策略优化方法,但有两个显著的区别:
- 策略优化发生在线性策略空间中;
- 优化过程利用了所有团队收集的样本。
以 MADDPG(Lowe 等人,2017)为代表, 的损失函数如下所示,基于集中式 Critic ψ (使用公式 1 学习):

其中, 存储了由 MARL 团队和 EA 团队收集的离策略(off-policy)经验。此外,在每次迭代的结束时,种群将 MARL 的策略表征 纳入进化。这种相互作用使得种群能够为 MARL 提供高质量的样本来进行优化,而 MARL 反过来则为种群演化提供潜在优秀的策略,从而实现了合作演化。这种互惠互利的交互机制有助于两种方法的共同进步。
3.3 The Algorithm Framework of RACE


Experiments
4.1 Setup
为了进行全面的比较研究,我们在具有连续和离散动作空间的任务上评估 RACE。对于连续任务,我们将 RACE 与 MATD3(Ackermann 等人,2019)结合,并在 Multi-Agent MuJoCo(Peng 等人,2021)的八个连续的协作控制任务上进行评估。这些任务涉及控制具有不同形态的机器人的不同关节,以完成站立或行走等任务。最难的设定:每个智能体只能观察自己的关节信息。
对于离散任务,我们将 RACE 与 FACMAC 结合,并在 StarCraft II 微观管理环境(Samvelyan 等人,2019)(SMAC)中进行评估。这些任务具有较高的控制复杂性,并需要在大的离散动作空间中学习策略。我们将 RACE 与以下基线进行比较:MATD3(Ackermann 等人,2019),MERL(Majumdar 等人,2020),EA(Khadka 和 Tumer,2018),以及 FACMAC(Peng 等人,2021)。
我们使用官方实现的这些算法进行比较。MATD3 是官方 TD3(Fujimoto等人,2018)实现在 CTDE 框架中的扩展。我们在官方 EA 和基本 MARL 算法的代码上实现了 RACE,同时保持其他超参数和过程的一致性。我们对所有基线进行微调以提供其最佳性能。
4.2 Performance
16 个 task 上的实验结果如下图所示,可以看到 RACE 在所有任务中对基准算法都有显著的性能增益。



为了研究 EA 和 MARL 对协作的影响,我们分析了种群中 MARL 团队的精英率和被舍弃率,如图 4 所示。我们观察到,在大多数环境中,精英率和被舍弃率都在 40% 左右。
值得注意的是,由 EA 维护的团队与仅由强化学习(RL)指导的团队相比,更有可能被选为精英团队。这一发现强调了 EA 在探索高效协作中的重要作用。然而,在 4 个智能体的 Ant 任务中,MARL 实现了更高的精英率和较低的被舍弃率,这表明在这种情况下,MARL 扮演主导角色,而 EA 则扮演支持角色。
4.3. Analysis of Components and Hyperparameter
关于 VFM,VMM,以及提出的演化算子的分析,具体可以阅读原文查看更多的细节。



Conclusion
RACE 主要是将进化算法,表征学习引入到了 MARL 中,用于解决 MARL 中面临的四个问题:探索弱,非稳态,局部观测,奖励信号敏感。我们在 16 个具有挑战性的任务上评估了 RACE,包括复杂的连续控制和离散微操作场景。实验结果表明,RACE 可以显著提高基本 MARL 方法的性能,并在各种具有挑战性的任务中优于其他基线算法。值得注意的是,我们的工作首次证明了 EA 在复杂的协作任务中具有显著提升 MARL 性能的能力。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
Agent 智能体
• 投稿邮箱:
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/239058.html原文链接:https://javaforall.net


