

使用cursor辅助代码阅读的具体步骤:
(1)使用cursor生成项目概述
(2)使用cursor生成UML类图
(3)把UML类图转换成svg文件
没有找到在知乎文章中上传svg格式内容的方法,屏幕截图上传的话分辨率太低。
所以把svg文件上传到了百度网盘 。可以下载到本地之后用浏览器打开查看。
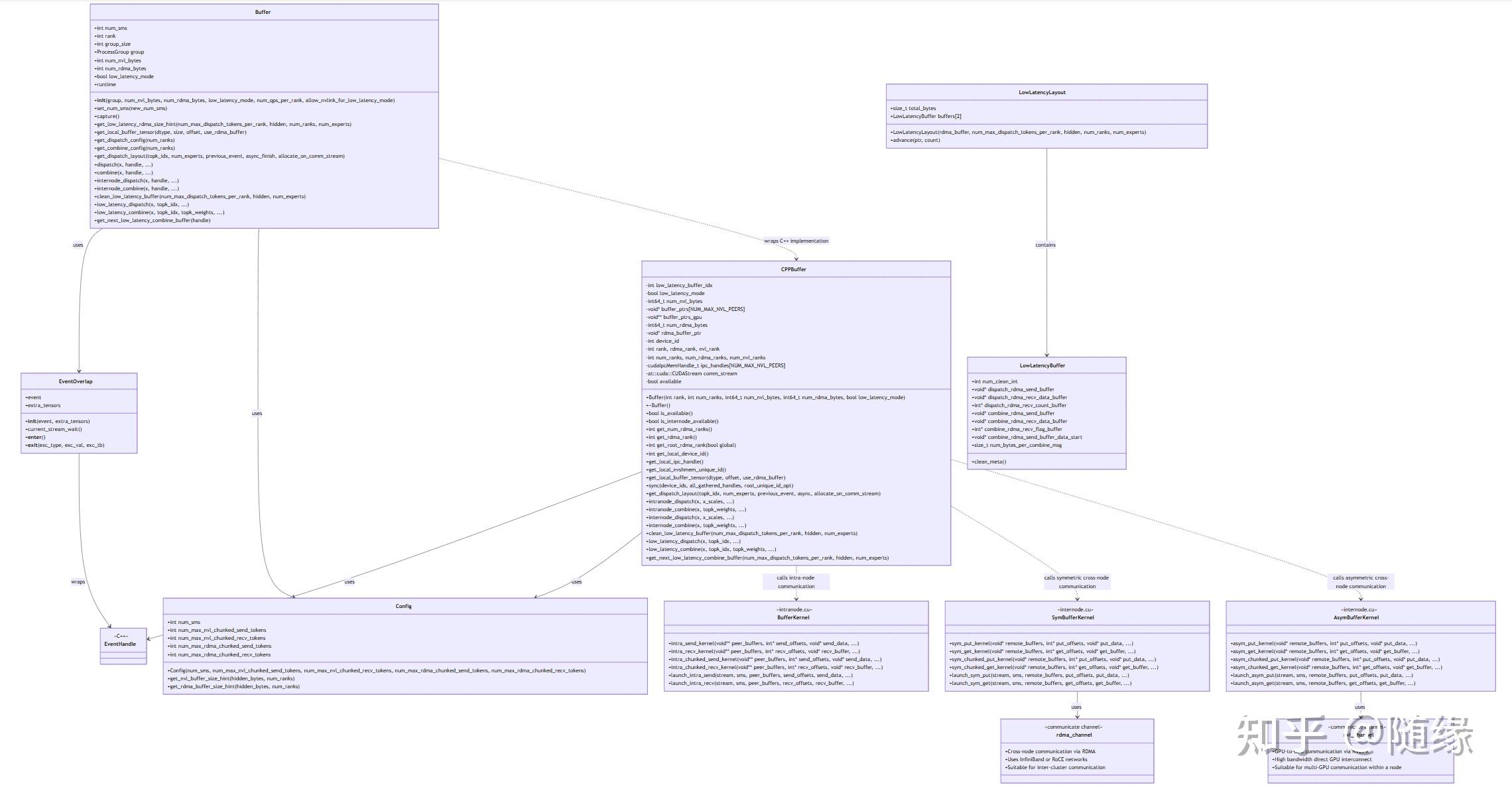
DeepEP(Deep Expert Parallel)是一个专为混合专家模型(Mixture of Experts,MoE)设计的高性能通信库。它提供了高效的专家并行通信缓冲区实现,支持多种通信模式,包括:
- 高吞吐量节点内通信(使用 NVLinkcursor 教程)
- 高吞吐量节点间通信(使用 RDMA 和 NVLink)
- 低延迟的全对全通信(使用 RDMA)
- 核心通信缓冲区管理类
- 负责管理 GPU 间的数据传输和同步
- 提供 dispatch 和 combine 操作,这是 MoE 模型中的关键操作
- 支持多种通信模式(节点内、节点间、低延迟)
- CUDA 事件管理工具类
- 用于实现操作间的重叠,提高性能
- 支持 Python 的 语法,方便用户使用
- Buffer 类的底层实现
- 管理实际的内存缓冲区和通信机制
- 处理 RDMA 和 NVLink 通信
- 配置管理类,用于控制通信参数
- 管理 SM(Streaming Multiprocessor)数量和缓冲区大小
- 提供缓冲区大小计算的辅助函数
- 专门为低延迟通信模式设计
- 管理内存布局和缓冲区分配
- 用于 intranode.cu 中的内存管理
- 提供简单的缓冲区访问接口
- 支持指针偏移和索引操作
- 用于 internode.cu 中的非对称内存管理
- 处理多个 rank 之间的通信
- 支持不同的前进策略
- 用于 internode.cu 中的对称内存管理
- 提供发送和接收缓冲区
- 支持耦合和解耦模式
- 将输入数据分发到不同的专家(GPU)上
- 支持节点内、节点间和低延迟模式
- 处理路由决策,确定每个 token 应该发送到哪个专家
- 收集来自不同专家的输出并组合
- 支持权重组合,用于 MoE 模型中的加权输出
- 使用 NVSHMEM 进行 GPU 间通信
- 支持 IPC 和 RDMA 通信方式
- 优化缓冲区布局,减少通信开销
- 通过 EventOverlap 管理 CUDA 事件
- 支持异步操作,提高并行度
- 利用 NVLink 和 RDMA 实现高带宽通信
- RoCE2″> 支持低延迟模式,减少通信延迟
- 优化的缓冲区布局和管理
- 支持不同数据类型和大小
- 可根据不同规模的集群调整参数
- 提供预设配置和自定义选项
- Python 接口易于使用
- C++ 核心实现提供高性能
以下是 DeepEP 项目的主要类及其关系:
DeepEP 库主要用于大规模混合专家模型训练,通过优化专家并行通信,显著提高训练效率和模型性能。它特别适合需要高效处理大规模分布式专家模型的应用场景。
使用在线绘图工具 或者 把UML描述转化成图
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/239271.html原文链接:https://javaforall.net


