
今天刷到一篇文章,vLLM直接支持华为的昇腾910B,刚好近期autoDL上线了一批华为昇腾专区910B,那咱们直接看看利用vLLM在大模型部署上和英伟达的GPU有什么区别不?
先放下项目repo地址:https://github.com/vllm-project/vllm-ascend
(1)项目概述
vLLM Ascend(vllm-ascend)是一个社区维护的硬件插件,用于在 Ascend NPU 上无缝运行 vLLM。
这是 vLLM 社区中支持 Ascend 后端的推荐方法。它遵循 [RFC] 中概述的原则:硬件可插拔,提供硬件可插拔接口,将 Ascend NPU 与 vLLM 的集成分离。
通过使用 vLLM Ascend 插件,流行的开源模型,包括 Transformer-like、Mixture-of-Expert、Embedding、Multi-modal LLM 可以在 Ascend NPU 上无缝运行。
简单的理解,相当于增加了1个插头转换器,使得大模型部署可以用vllm在Ascend NPU上推理运行。
(2)项目安装
目前项目还处于较早期,所以有一些环境要求:
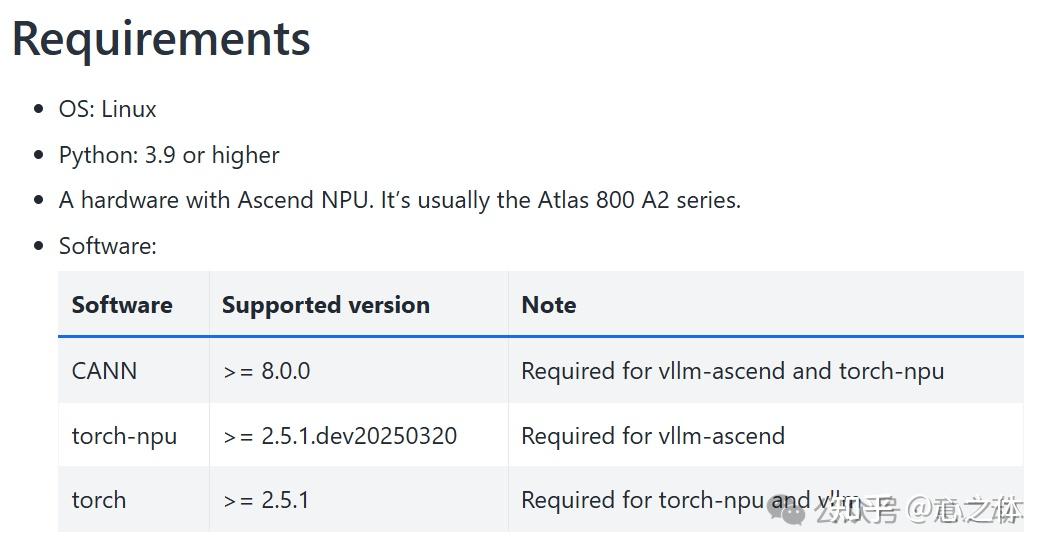

翻了一下autoDL的昇腾专区,刚好匹配,就可以直接开始了。
1、创建镜像,在autoDL上目前910B是单卡64GB显存:
DeepSeek 教程
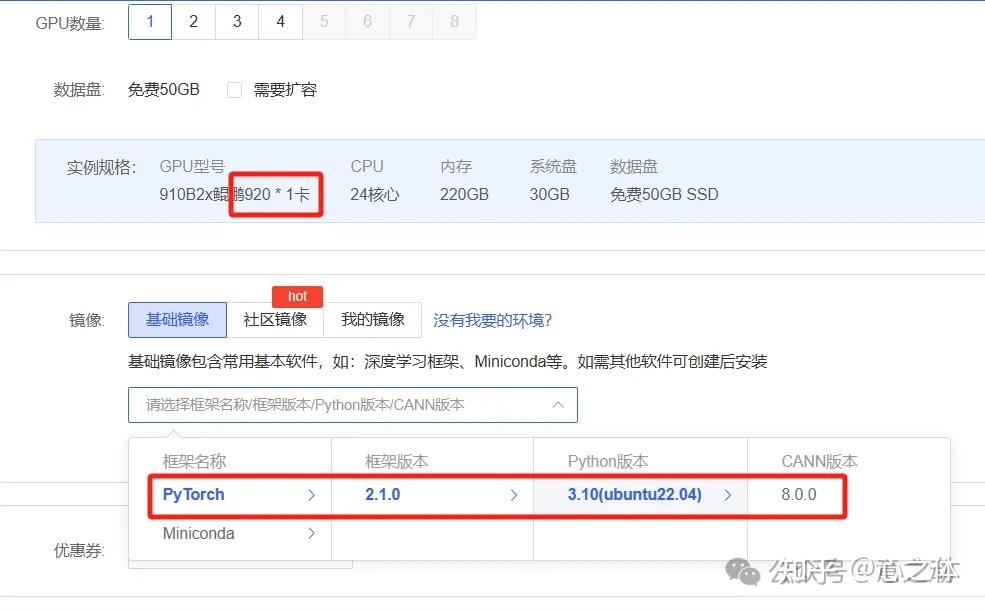
2、项目安装,目前支持两种安装方式,Pip或Docker方式,因为autoDL已经进行容器化,所以只能采用pip,可惜pip方式安装失败,经过查阅,其实目前还有第三种安装方式是源码安装,最后是采用源码安装方式成功的。
正常情况下,在安装vLLM与vLLM-Ascend之前,需要安装CANN,因为目前的容器中,已经提前安装好了,所以就跳过这个手动安装CANN的环节,直接从源代码安装。
# Install vLLM git clone --depth 1 --branch v0.7.3 https://github.com/vllm-project/vllm cd vllm VLLM_TARGET_DEVICE=empty pip install . --extra-index https://download.pytorch.org/whl/cpu/ # Install vLLM Ascend git clone --depth 1 --branch v0.7.3rc1 https://github.com/vllm-project/vllm-ascend.git cd vllm-ascend pip install -e . --extra-index https://download.pytorch.org/whl/cpu/当前版本依赖于未发布的版本torch-npu,还需要手动安装:
mkdir pta cd pta wget https://pytorch-package.obs.cn-north-4.myhuaweicloud.com/pta/Daily/v2.5.1/.3/pytorch_v2.5.1_py310.tar.gz tar -xvf pytorch_v2.5.1_py310.tar.gz pip install ./torch_npu-2.5.1.dev-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl我在安装过程中遭遇到1个torchvision的版本问题,

解决方法就是手动安装一下,torch的2.5.1版本对应torchvision是0.20.1,因为这个torch-npu是必须torch的2.5.1版本。
pip install torchvision==0.20.1torchvision安装好之后,为避免安装包冲突,最好把vLLM与vLLM-Ascend也再重新安装一下,执行最后一条命令即可。
3、项目测试
为确保vLLM与vLLM-Ascend安装成功,根据官方建议,进行1个测试:
from vllm import LLM, SamplingParams prompts = [ "Hello, my name is", "The president of the United States is", "The capital of France is", "The future of AI is", ] # Create a sampling params object. sampling_params = SamplingParams(temperature=0.8, top_p=0.95) # Create an LLM. llm = LLM(model="Qwen/Qwen2.5-0.5B-Instruct") # Generate texts from the prompts. outputs = llm.generate(prompts, sampling_params) for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")然后设置环境变量VLLM_USE_MODELSCOPE(注意是单窗口生效),安装modelscope(程序中会用到),并运行python程序,因为目前autoDL的华为昇腾专区不支持学士资源加速,所以只能从modelscope上下载,不过这样下载速度很快。
export VLLM_USE_MODELSCOPE=true pip install modelscope==1.22.0 python example.py这里有个小坑,目前官方目前对modelscope有版本要求,如果你不指定版本,安装了最新的modelscope,会提示载入出错。
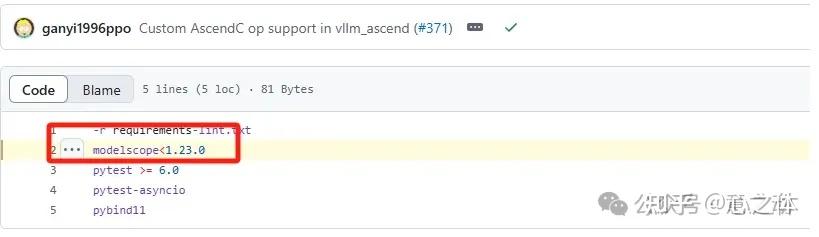

我第一次安装时,没注意版本控制,就查了20分钟的问题,还好issue上有别人的提问。
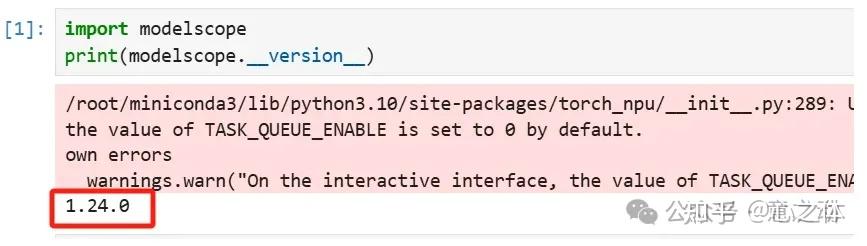
第一次程序运行时,会从modelscope上自动下载一个“Qwen2.5-0.5B-Instruct”模型,大概950MB,运行输出如下:

看到这里,说明vLLM与vLLM-Ascend安装成功。
4、模型下载
正常要部署Deepseek模型的话,也可以提前下载好,或者直接运行vLLM命令方式去下载,我比较习惯先下载好,再指定进行载入。
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --local_dir /root/autodl-tmp/DeepSeek-R1-Distill-Qwen-14B/官方建议对内存分片也进行一些限制,这样可以更好的节约内存:
export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256接下来就可以利用vLLM的命令直接载入模型啦:
vllm serve /root/autodl-tmp/DeepSeek-R1-Distill-Qwen-14B \ --max_model 4096 \ --port 8000 \ --tensor-parallel-size 1 \ --trust-remote-code \ --served-model-name "DeepSeek-R1-Distill-Qwen-14B" \ --api-key 看见这个界面就是载入成功了:

(3)项目测试
接下来,为便于测试,我利用chatBox来连接这个模型的API(需要用autoDL的ssh工具把8000端口映射到本地),chatBox的配置示意如下,输入API域名和前面设置的密钥(正式使用时,千万要设置复杂密钥):

连接成功后,可以尝试对话一下(老问题答错):

看一下速率,还是非常快的,平均20tokens/s。
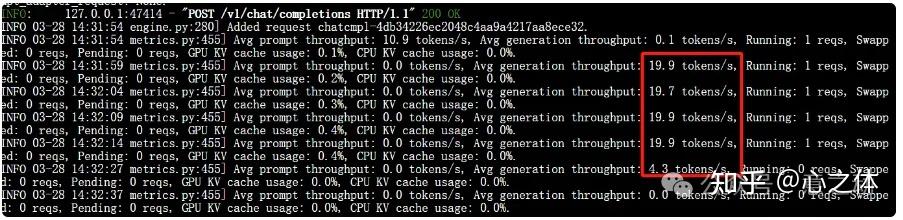
写个小说,也没问题

速率还是持续稳定在平均20tokens/s。
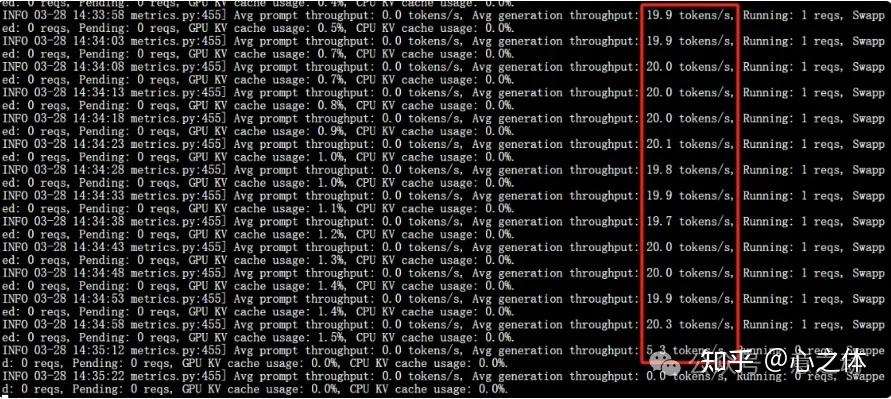
总结一下,整个安装过程还是比较丝滑的,和vLLM工具正常使用基本一致,基本上顺利的话,半小时就可以安装完。
满血Deepseek-v3-0324是660B,比原来671B略微小一些,根据华为的官方推荐是需要4台8卡910B的服务器进行加载,官方教程上也有部署满血Deepseek的方式(docker容器),有兴趣的童靴可以去试一下。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/240359.html原文链接:https://javaforall.net


