
DeepSeek-OCR 2 是 DeepSeek 团队于 2026 年 1 月 26 日正式开源的新一代光学字符识别(OCR)模型,代表了文档智能理解领域的重大突破。该模型的核心创新是 视觉因果流(Visual Causal Flow) 技术,这是一种全新的文档解析范式,彻底改变了机器”阅读”文档的方式。
与传统 OCR 系统按像素顺序从左上到右下机械扫描的方式不同,DeepSeek-OCR 2 通过视觉因果流模拟人类的阅读方式——它不会按固定的栅格顺序遍历文档,而是根据语义意义而非空间坐标来识别重要信息。模型首先对整个文档建立全局理解,然后智能地决定逻辑阅读顺序,例如遵循列的布局、将标签与其值关联、以及连贯地解析表格。
在技术架构上,DeepSeek-OCR 2 采用了 DeepEncoder V2 视觉编码器,这是一个将视觉编码器转变为推理模型的创新架构。它通过可学习的查询 token 逐步处理信息,每个步骤都依赖于前一个步骤,从而在源头修复阅读顺序,并将视觉与语言自然对齐。该模型具备高效的视觉-文本压缩能力,可以将 1,000 个文本 token 压缩成仅 100 个视觉 token,同时保持超过 97% 的解码准确率。在生产环境中,模型能够在一张 A100-40G GPU 上每天生成或解析超过 200,000 页的文档。
目前相关内容已经在官网中可以直接安装使用了NVIDIA Alpamayo自动生成项目中了。

2.1 系统要求
在开始部署 DeepSeek-OCR 2 之前,请确保您的系统满足以下硬件和软件要求。由于模型采用了大规模的视觉-语言架构,对计算资源有一定要求:
注意事项:如果您的显存低于 16GB,可以通过调整 参数(如设为 0.6)和减小 (如设为 4096)来降低显存占用,但这可能会影响处理长文档的能力。
2.2 安装步骤
以下是完整的环境安装流程。建议使用 Conda 创建独立的虚拟环境,以避免与系统中其他 Python 项目产生依赖冲突。整个安装过程需要下载约 10GB 的依赖包和模型文件,请确保网络连接稳定。
常见问题:如果在安装 flash-attn 时遇到编译错误,请确保已安装 CUDA Toolkit 和对应版本的 GCC 编译器。
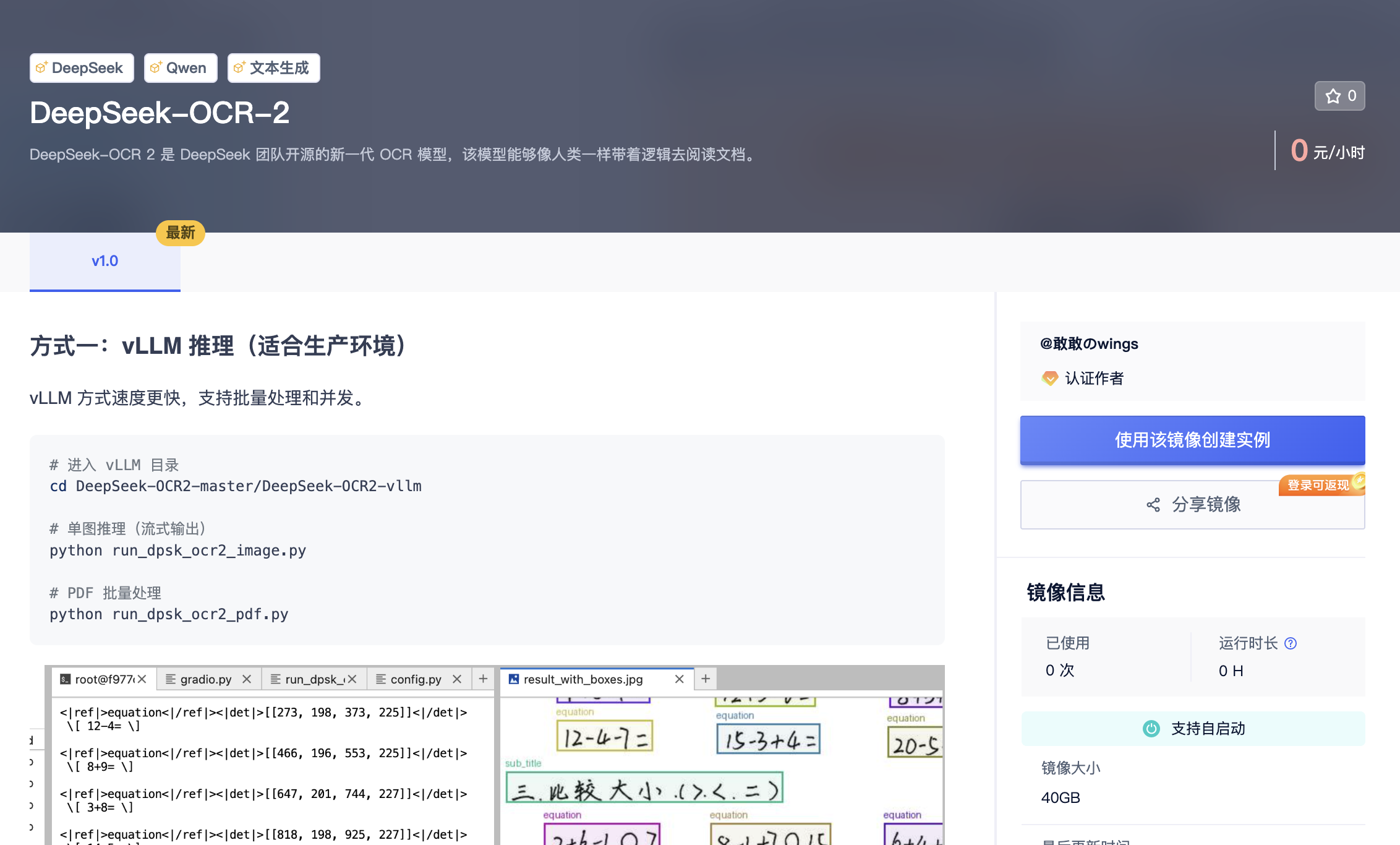
3.1 方式一:vLLM 推理(适合生产环境)
vLLM 是一个高性能的大语言模型推理引擎,专为生产环境设计。相比原生 Transformers 推理,vLLM 通过 PagedAttention 技术实现了更高效的显存管理,支持连续批处理(Continuous Batching)和并发请求处理。在实际测试中,vLLM 的推理速度可达原生实现的 3-5 倍,特别适合需要处理大量文档的批量 OCR 场景。
DeepSeek-OCR 2 官方提供了基于 vLLM 的推理脚本,支持单图推理和 PDF 批量处理两种模式。单图推理采用流式输出,可以实时查看识别进度;PDF 处理则会自动将文档拆分为单页图像,逐页进行识别后合并结果。
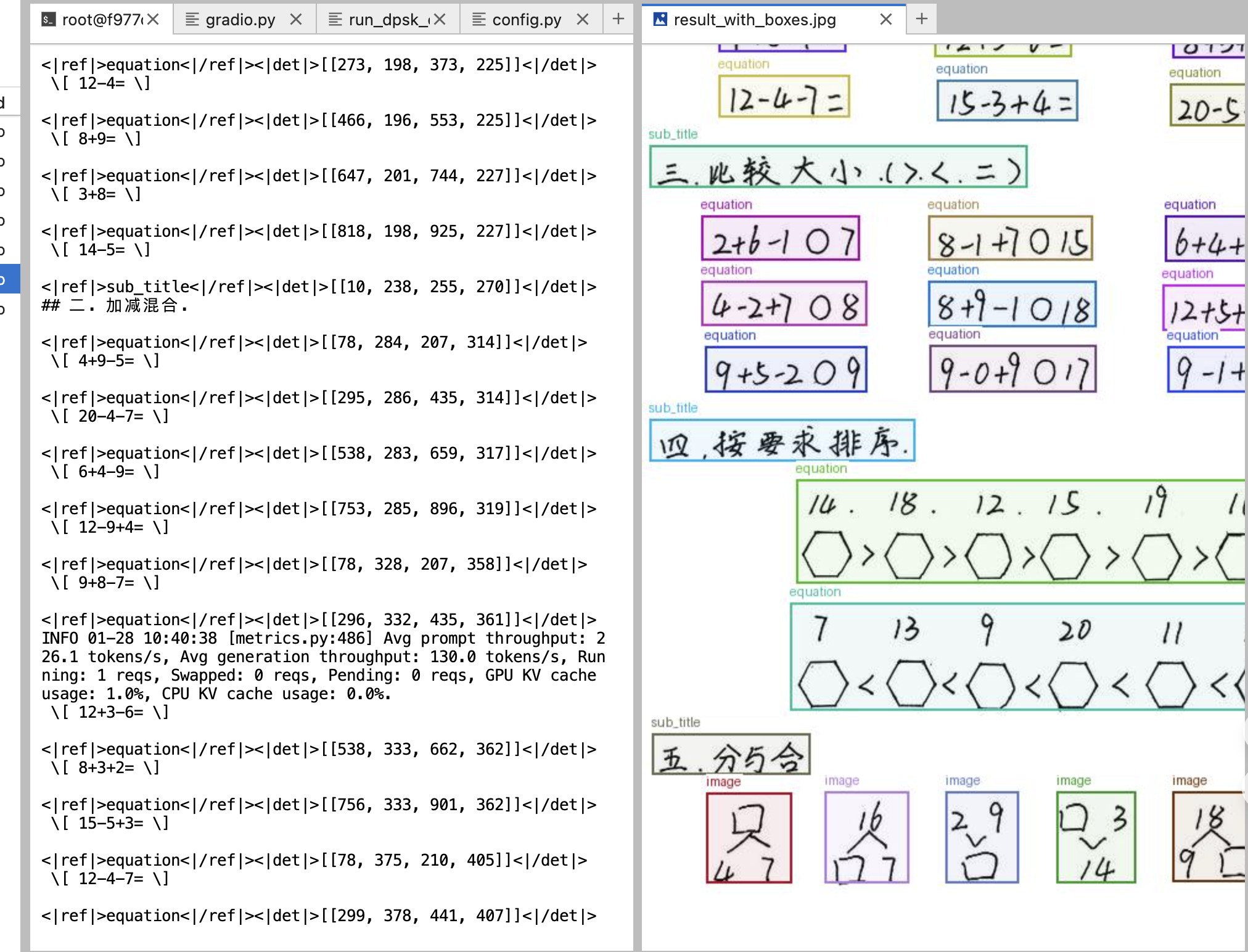
3.2 方式二:Gradio 可视化界面(推荐新手)
对于不熟悉命令行操作的用户,我们提供了基于 Gradio 框架的 Web 可视化界面。Gradio 是 Hugging Face 推出的机器学习演示工具,能够快速将 AI 模型封装为交互式 Web 应用。通过这个界面,您可以直接在浏览器中上传图片、选择识别模式、查看 OCR 结果和边界框可视化效果,无需编写任何代码。
该界面支持四种识别模式:文档转 Markdown(保留文档结构)、纯文字识别(仅提取文本)、表格识别(专门处理表格内容)以及自定义提示词(高级用户可自行编写指令)。识别完成后,界面会同时显示清理后的文本结果和带有边界框标注的可视化图像,方便您直观地了解模型对文档各区域的识别情况。
3.2.1 安装 Gradio
首先需要安装 Gradio 库。Gradio 的安装非常简单,只需一条 pip 命令即可完成。建议安装最新版本以获得最佳的界面体验和功能支持。
3.2.2 启动界面
将以下代码保存为 ,放入 目录。这段代码实现了完整的 Web 界面功能,包括图像加载、模型推理、边界框绘制和结果展示。代码采用异步架构设计,能够高效处理用户请求,同时通过全局引擎变量避免模型重复加载,提升响应速度。
3.2.3 运行
完成代码保存后,在终端中执行以下命令启动 Gradio 服务。首次运行时,程序会自动从 Hugging Face 下载 DeepSeek-OCR-2 模型权重(约 8GB),请确保网络连接稳定。模型加载完成后,您将在终端看到服务启动成功的提示信息。
启动成功后,打开浏览器访问 即可使用 Web 界面。如果您需要从其他设备访问,可以将代码中的 参数设为 ,这样局域网内的其他设备也能通过您的 IP 地址访问该服务。界面加载完成后,您将看到左侧的图片上传区域和参数设置面板,右侧则是识别结果展示区域。

DeepSeek-OCR 2 通过不同的提示词(Prompt)来控制输出格式和识别行为。提示词中的 标记表示图像输入位置, 标记则启用边界框检测功能,使模型在输出文本的同时标注各元素在图像DeepSeek 教程中的位置坐标。以下是三种最常用的提示词模板:
提示:您也可以编写自定义提示词来实现特定需求,例如 可以专门提取文档中的数学公式。
在使用 DeepSeek-OCR 2 时,有几个关键参数会影响识别效果和性能表现。合理调整这些参数可以在不同场景下获得最佳的识别结果。以下是各参数的详细说明:
裁剪模式说明:当处理大尺寸图像或长文档时,启用裁剪模式(crop_mode=True)可以将图像智能分割为多个子区域分别处理,然后合并结果。这种方式能够有效避免显存溢出,同时保持识别精度。
6.1 Q1: 出现 错误
原因:vLLM 版本不兼容。DeepSeek-OCR 2 依赖特定版本的 vLLM API,而较新或较旧版本的 vLLM 可能已经修改了相关接口。
解决方案:卸载当前 vLLM 版本,安装官方指定的 v0.8.5 版本:
6.2. Q2: 显存不足(CUDA Out of Memory)
原因:模型加载和推理过程中显存占用超过了 GPU 可用显存。
解决方案:调整以下参数降低显存占用:
6.3 Q3: 模型下载速度慢或失败
原因:Hugging Face 服务器在国内访问可能不稳定。
解决方案:使用国内镜像源或手动下载模型后指定本地路径:
DeepSeek-OCR 2 作为新一代智能文档识别模型,通过视觉因果流技术实现了从”像素扫描”到”语义理解”的范式跃迁。本教程介绍了从环境配置、模型部署到实际使用的完整流程,涵盖了命令行推理和可视化界面两种使用方式。无论您是需要批量处理企业文档的开发者,还是希望快速体验 OCR 能力的研究人员,都可以根据自身需求选择合适的部署方案。
随着 DeepSeek 团队持续迭代优化,未来模型在多语言支持、手写识别、复杂版式解析等方面还将带来更多惊喜。建议关注官方 GitHub 仓库获取最新更新,也欢迎在社区中分享您的使用经验和改进建议。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/241900.html原文链接:https://javaforall.net


