
ChatGPT的发布给大家带来了不少的震撼,而随后发布的GPT-4更是展现了非凡的多模态能力。但是,ChatGPT和GPT4官方公布的细节很少,OpenAI俨然走上了闭源之路,让广大AI从业者又爱又恨。
最近,来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队开源了GPT-4的平民版 MiniGPT-4。他们认为,GPT-4 具有先进的多模态生成能力的主要原因在于利用了更先进的大型语言模型(LLM)。为了研究这一现象,他们提出了 MiniGPT-4。
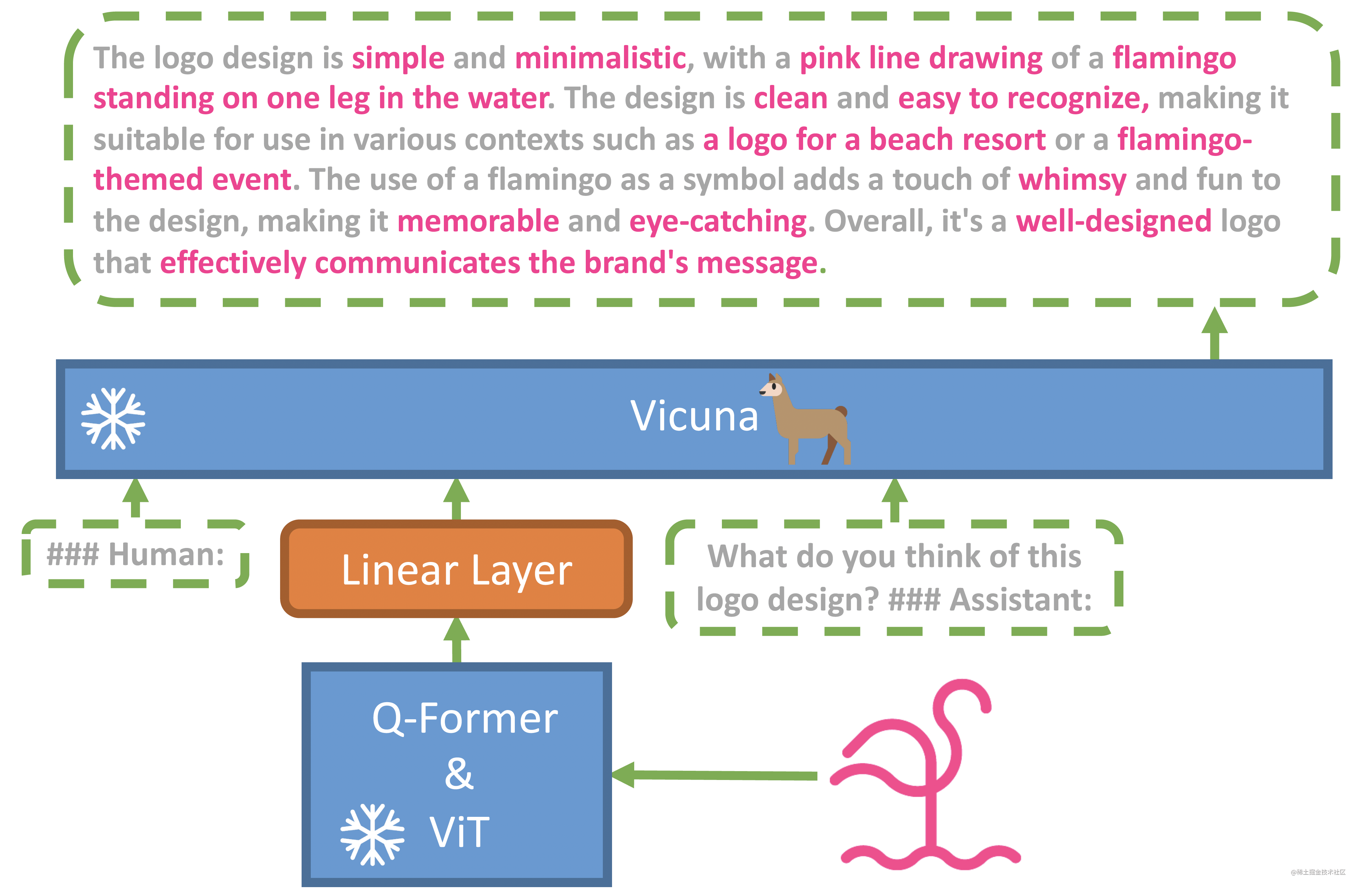
MiniGPT-4 仅使用一个投影层将一个冻结的视觉编码器(BLIP-2)与一个冻结的 LLM(Vicuna)对齐。

MiniGPT-4 产生了许多类似于 GPT-4 中新兴的视觉语言能力。比如:根据给定的图像创作故事和诗歌,为图像中显示的问题提供解决方案,教用户如何根据食物照片烹饪,给个手绘草图直接写出网站的代码等。
除此之外,此方法计算效率很高,因为它仅使用大约 500 万个对齐的图像-文本对和额外的 3,500 个经过精心策划的高质量图像-文本对来训练一个投影层。
BLIP-2 简介 BLIP-2是一种通用且高效的视觉-语言预训练方法,它可以从现成的冻结预训练图像编码器和冻结大型语言模型中引导视觉-语言预训练。BLIP-2通过一个轻量级的Querying Transformer来弥合模态差距,并在两个阶段进行预训练。第一个阶段从冻结图像编码器引导视觉-语言表示学习。第二个阶段从冻结语言模型中引导视觉-语言生成学习。尽管比现有方法具有显著较少的可训练参数,但BLIP-2在各种视觉-语言任务上实现了最先进的性能。在零样本 VQAv2 上,BLIP-2 相较于 80 亿参数的 Flamingo 模型,使用的可训练参数数量少了 54 倍,性能却提升了 8.7 %。
MiniGPT-4 的模型架构遵循 BLIP-2,因此,训练 MiniGPT-4 分两个阶段。
第一个传统预训练阶段使用 4 张 A100 卡在 10 小时内使用大约 500 万个对齐的图像-文本对进行训练。 在第一阶段之后,Vicuna 虽然能够理解图像。 但是Vicuna的生成能力受到了很大的影响。
为了解决这个问题并提高可用性,MiniGPT-4 提出了一种通过模型本身和 ChatGPT 一起创建高质量图像文本对的新方法。 基于此,MiniGPT-4 随后创建了一个小规模(总共 3500 对)但高质量的数据集。
第二个微调阶段在对话模板中对该数据集进行训练,以显著提高其生成的可靠性和整体的可用性。 令人惊讶的是,这个阶段的计算效率很高,使用单个 A100 只需大约 7 分钟即可完成。
随着ChatGPT的爆火,大语言模型(LLM)得到了空前的关注。模型需要哪些核心技术,有没有代码实践教程?针对这些问题,推荐大家学习深蓝学院的《》课程,课程注重理论思想与代码实践相结合,最终带你从0到1制作自己的mini-ChatGPT。
基础环境配置如下:
- 操作系统: Ubuntu 18.04
- CPUs: 单个节点具有 384GB 内存的 Intel CPU,物理CPU个数为2,每颗CPU核数为20
- GPUs: 4 卡 A800 80GB GPUs
- Python: 3.10 (需要先升级OpenSSL到1.1.1t版本(),然后再编译安装Python),
- NVIDIA驱动程序版本: 525.105.17,根据不同型号选择不同的驱动程序,。
- CUDA工具包: 11.6,
- cuDNN: 8.8.1.3_cuda11,
本文选择使用Doker镜像进行环境搭建。
首先,下载对应版本的Pytorch镜像。
镜像下载完成之后,创建容器。
进入容器。
安装 cv2 的依赖项。
安装其他依赖包。
其中,requirements.txt文件内容如下:
接下来,安装img2dataset库,用于后续下载数据集使用。
预先准备好 Vicuna 权重,详情请查看。
在之前的文章大模型也内卷,Vicuna训练及推理指南,效果碾压斯坦福羊驼中,有讲解过如何合并Vicuna模型权重,在这里我直接使用之前合并好的Vicuna权重文件。
准备好 Vicuna 权重之后,在模型配置文件 minigpt4.yaml 中的第 16 行设置 Vicuna 权重的路径。
然后,下载预训练的 MiniGPT-4 检查点(checkpoint),用于模型推理。下载地址: 或
如果服务器无法访问外网,需要预先下载好 VIT()、Q-Former ()的权重以及Bert()的Tokenizer。如果服务器可以访问外网且网络状况良好,可以直接忽略以下步骤。
eva_vit_g.pth和blip2_pretrained_flant5xxl.pth下载好之后,格式如下:
同时需要设置环境变量:
bert-base-uncased下载好之后,格式如下:
同时,需要修改/workspace/code/MiniGPT-4/minigpt4/models/blip2.py文件,改为本地加载Tokenizer:
下面准备数据集,MiniGPT-4 的训练包含两个阶段,每个阶段使用的数据集不一样。
首先,准备第一阶段数据集。
下载ccs_synthetic_filtered_large.json和laion_synthetic_filtered_large.json文件,并移动到对应的目录。
进入MiniGPT-4项目的dataset目录,并拷贝转换数据格式和下载数据集的脚本。
由于数据集太大,进入${MINIGPT4_DATASET}/cc_sbu和${MINIGPT4_DATASET}/laion文件夹,修改convert_cc_sbu.py和convert_laion.py脚本,改为仅下载一部分数据。
然后,将laion和cc_sbu标注文件格式转换为img2dataset格式。
进入${MINIGPT4_DATASET}/cc_sbu和${MINIGPT4_DATASET}/laion文件夹,修改下载数据集脚本download_cc_sbu.sh和download_laion.sh,将–enable_wandb配置项改为False。
然后,执行脚本,使用img2dataset下载数据集。
下载完成之后的最终数据集结构如下所示:
之后,修改数据集配置文件。
修改配置文件minigpt4/configs/datasets/laion/defaults.yaml的第五行设置LAION数据集加载路径,具体如下所示:
修改配置文件minigpt4/configs/datasets/cc_sbu/defaults.yaml的第五行设置 Conceptual Captoin 和 SBU 数据集加载路径,具体如下所示:
接下来,准备第二阶段数据集,具体在下载,数据集文件夹结构如下所示。
下载完成之后,在数据集配置文件minigpt4/configs/datasets/cc_sbu/align.yaml中的第 5 行设置数据集路径。
MiniGPT-4 项目基于 、 和 进行构建,使用 OmegaConf 基于 YAML 进行分层系统配置,整个代码结构如下所示:
首先,在评估配置文件eval_configs/minigpt4_eval.yaml中的第 11 行设置预训练checkpoint的路径(即刚刚下载的预训练的 MiniGPT-4 检查点)。
执行如下命令启动模型推理服务:
为了节省 GPU 内存,Vicuna 默认以 8 bit 进行加载,beam search 宽度为 1。此配置对于 Vicuna-13B 需要大约 23G GPU 内存、对于 Vicuna-7B 需要大约 11.5G GPU 内存。 如果你有更强大的 GPU,您可以通过在配置文件 minigpt4_eval.yaml 中将 low_resource 设置为 False 以 16 bit运行模型并使用更大的beam search宽度。
运行过程:
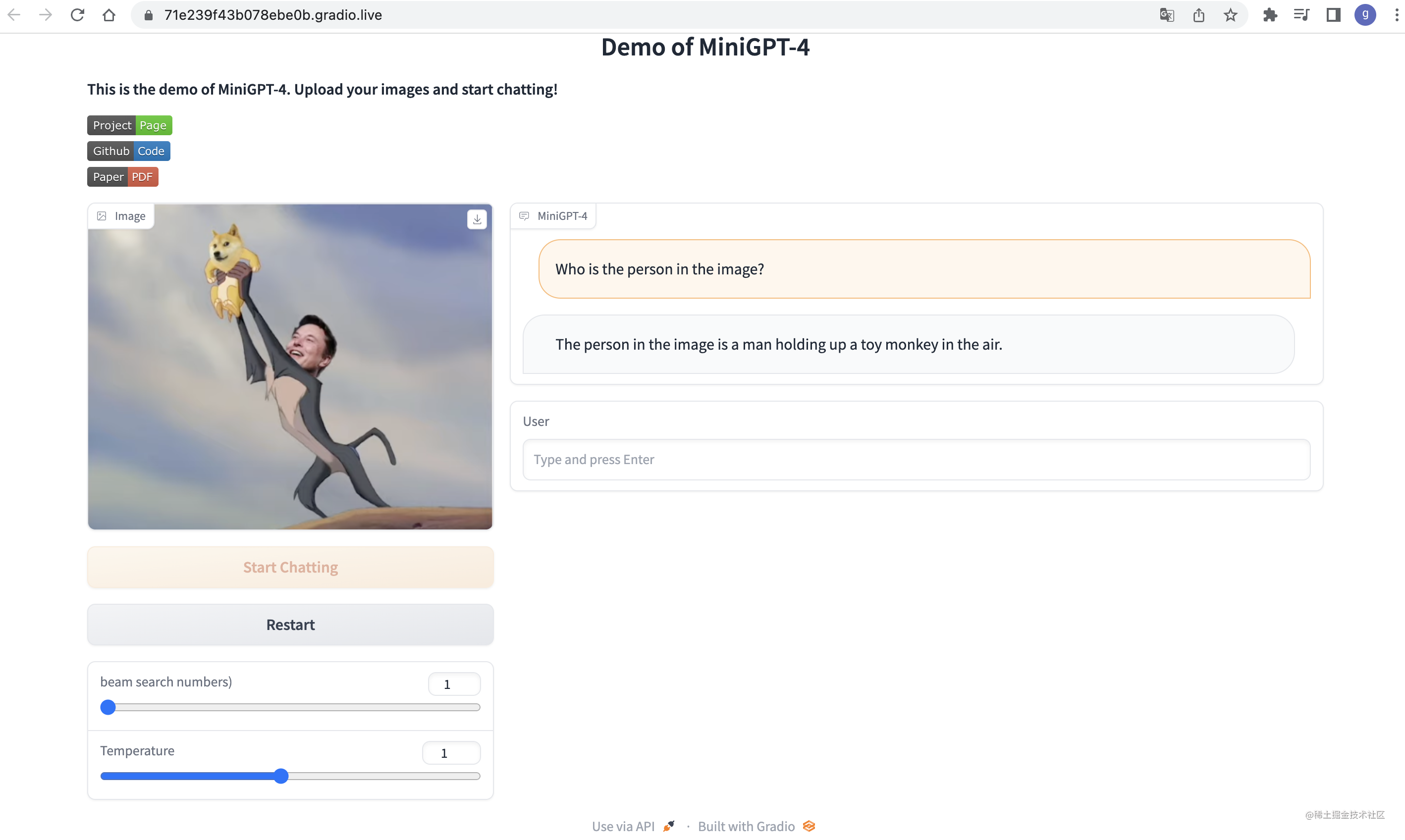
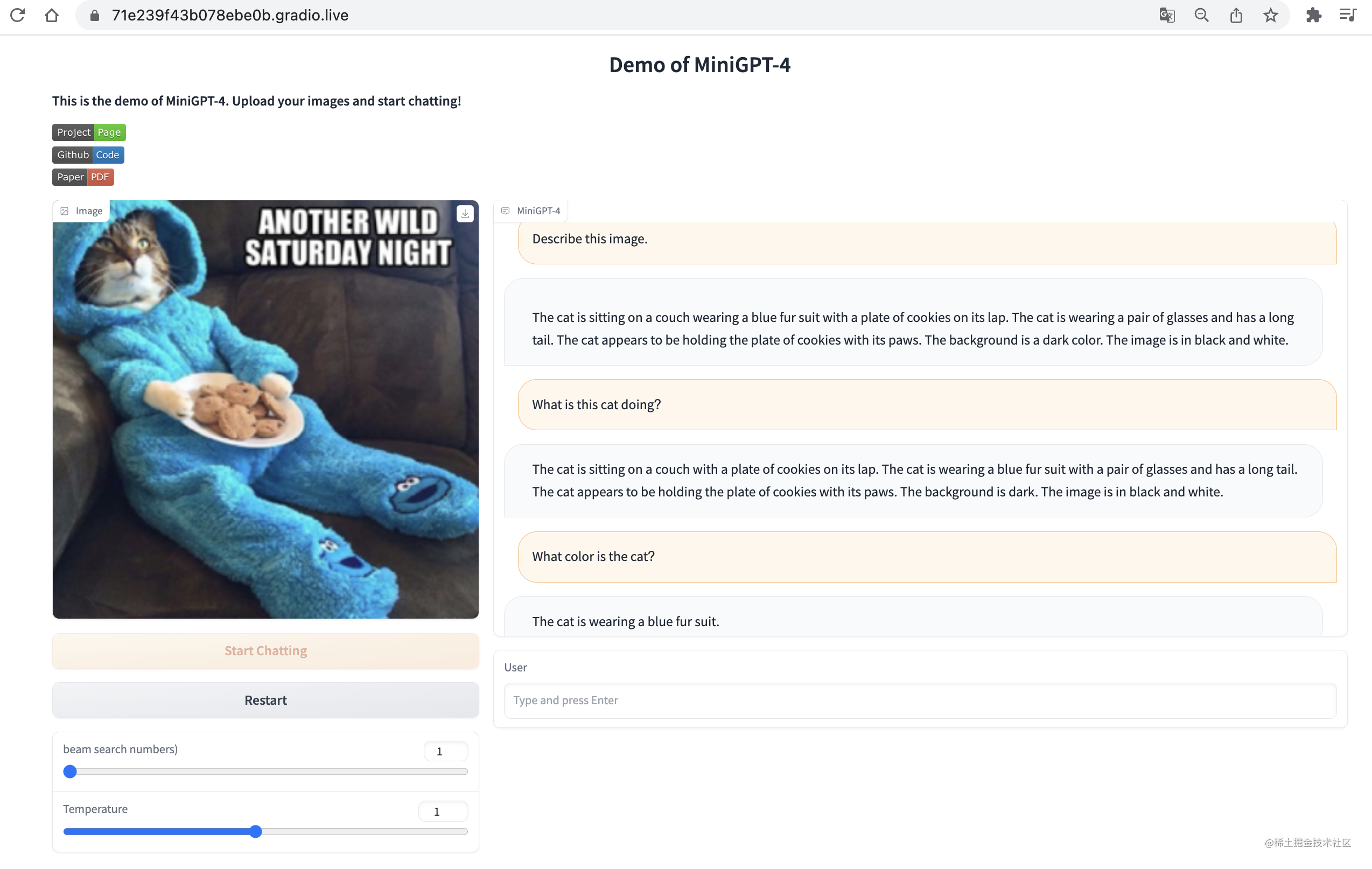
模型推理测试:
MiniGPT-4 的训练包含两个对齐阶段。
在预训练阶段,模型使用来自 Laion 和 CC 数据集的图像文本对进行训练,以对齐视觉和语言模型。
第一阶段之后,视觉特征被映射,可以被语言模型理解。 MiniGPT-4 官方在实验时使用了 4 个 A100。 除此之外,您还可以在配置文件 train_configs/minigpt4_stage1_pretrain.yaml 中更改保存路径,具体内容如下:
接下来,通过以下命令启动第一阶段训练。
运行过程:
显存占用:
模型权重输出:
你也可以直接下载只有第一阶段训练的 MiniGPT-4 的 checkpoint,具体下载地址: 或 。
与第二阶段之后的模型相比,第一阶段的checkpoint经常生成不完整和重复的句子。
在第二阶段,我们使用自己创建的小型高质量图文对数据集并将其转换为对话格式以进一步对齐 MiniGPT-4。
要启动第二阶段对齐,需先在train_configs/minigpt4_stage2_finetune.yaml 中指定第一阶段训练的checkpoint文件的路径。 当然,您还可以自定义输出权重路径,具体文件如下所示。
然后,第二阶段微调的运行命令如下所示。 MiniGPT-4官方在实验中,仅使用了 1 卡 A100。
运行过程:
显存占用:
模型权重输出:
经过第二阶段对齐之后,MiniGPT-4 能够连贯地和用户友好地讨论图像。
至此,整个模型训练过程结束。接下来进行对训练的模型进行评估。
首先,在评估配置文件eval_configs/minigpt4_eval.yaml中的第 11 行设置待评估模型的checkpoint路径,同模型推理。
执行如下命令启动模型推理服务进行评估:
如果出现Could not create share link. Please check your internet connection or our status page: 这个问题,通常是由于网络环境不稳定造成的。可修改demo.py文件如下的代码,使用IP:端口访问即可。
运行过程:
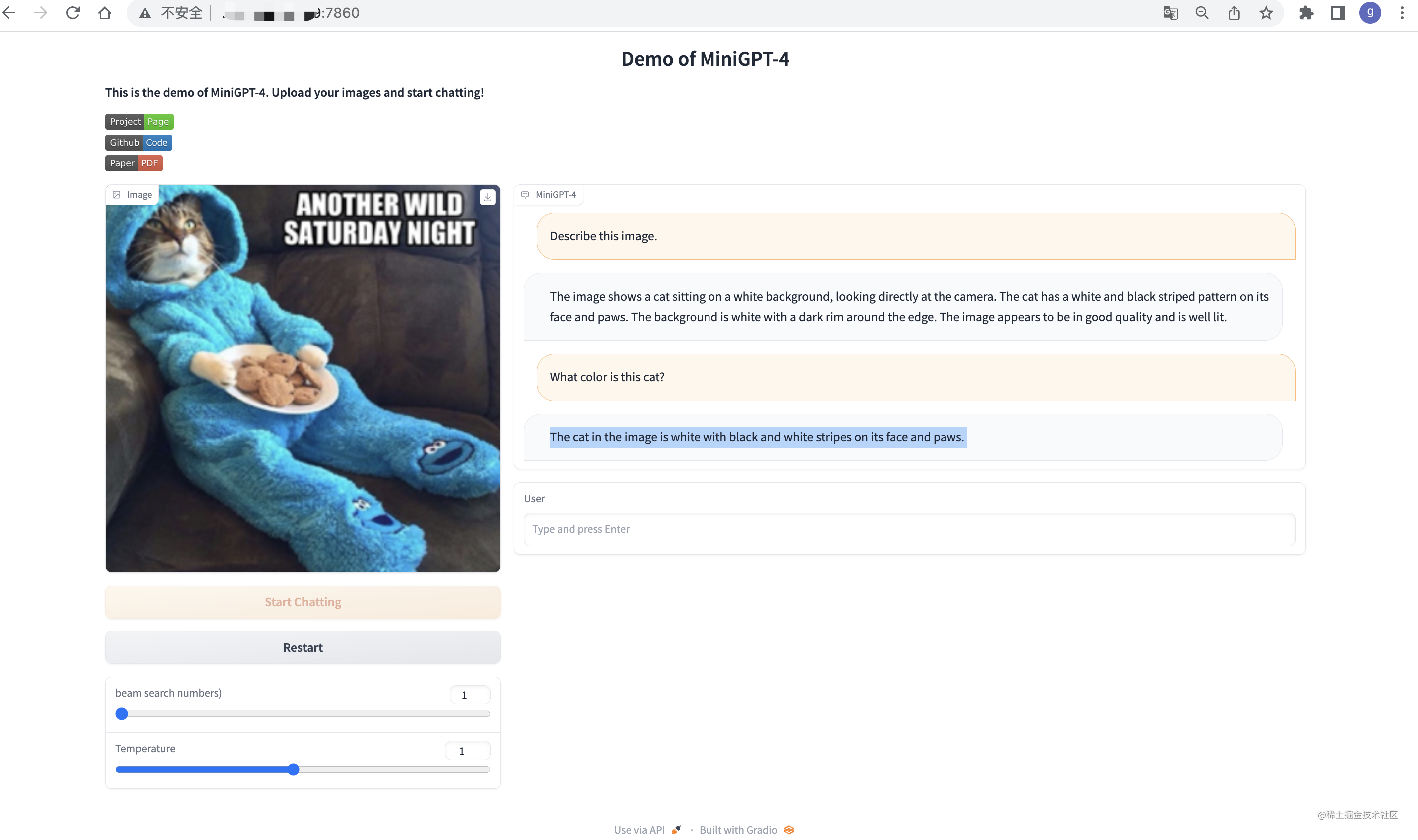
模型评估测试:
本文给大家分享了多模态大模型MiniGPT-4的基本原理及模型训练推理方法,希望能够给大家带来帮助。
参考文档:
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/242015.html原文链接:https://javaforall.net


