
使用gpt_academic + searxng搜索,进行网页或者学术论文的快速检索。实验下来使用超级便宜的也能有相当好的效果。不过由于要处理的文本量偏多,原版的处理这种任务就有点力不从心了,可能需要使用上下文更大的本地模型才能有更好的效果。
由于最近在研究RAG方面,先让它帮我搜下RAG方面文件处理的论文吧:
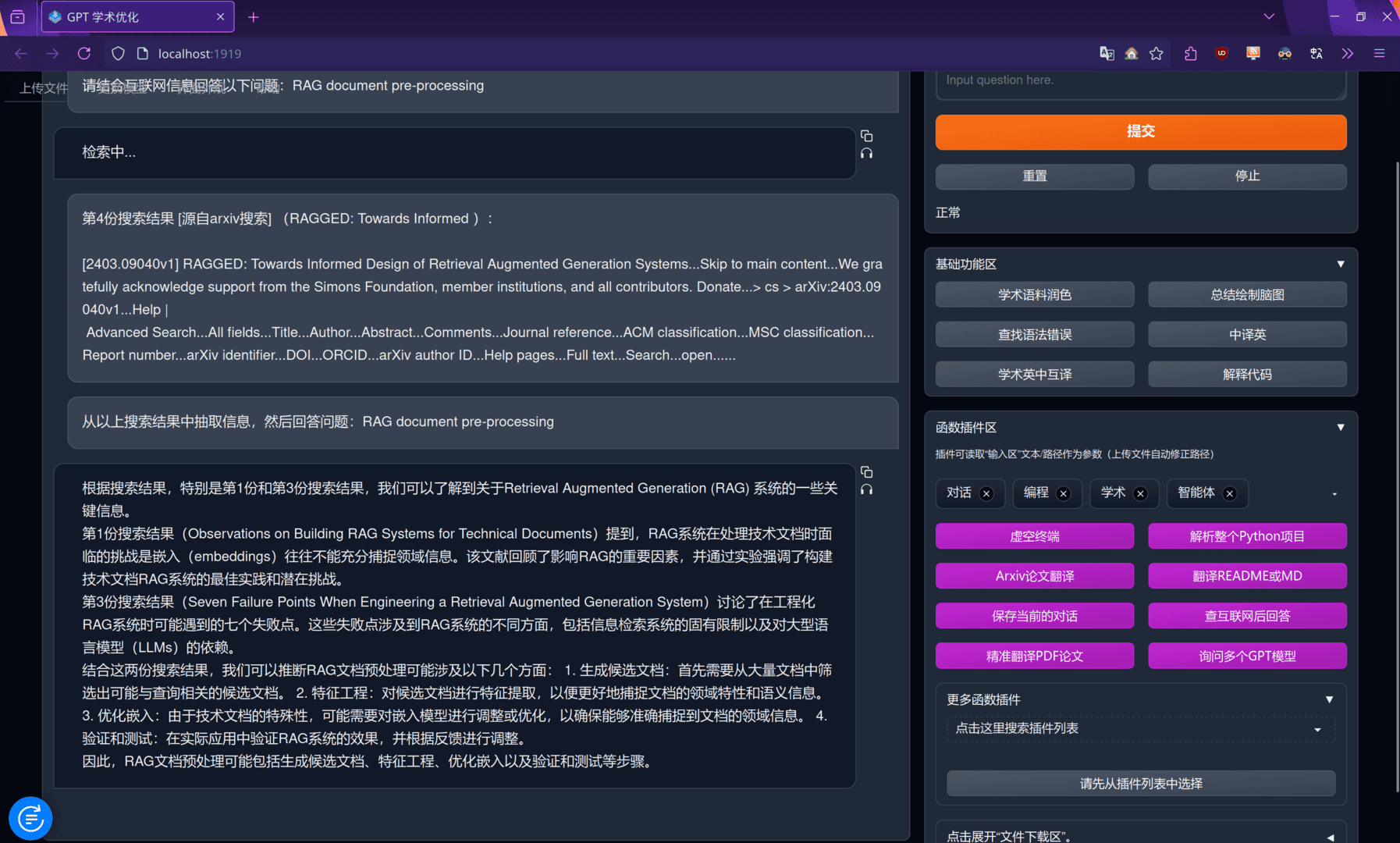

或者尝试下网页搜索:
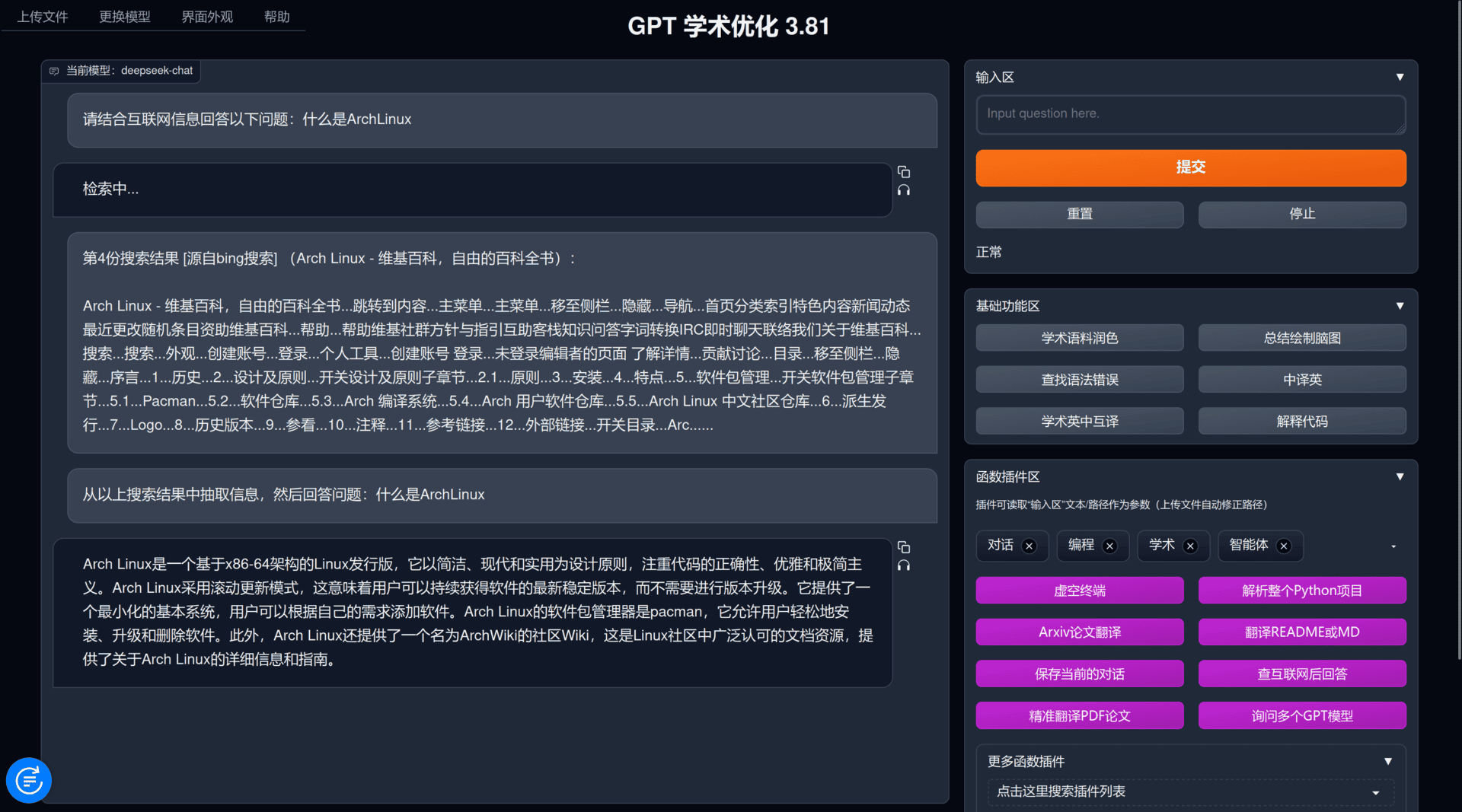
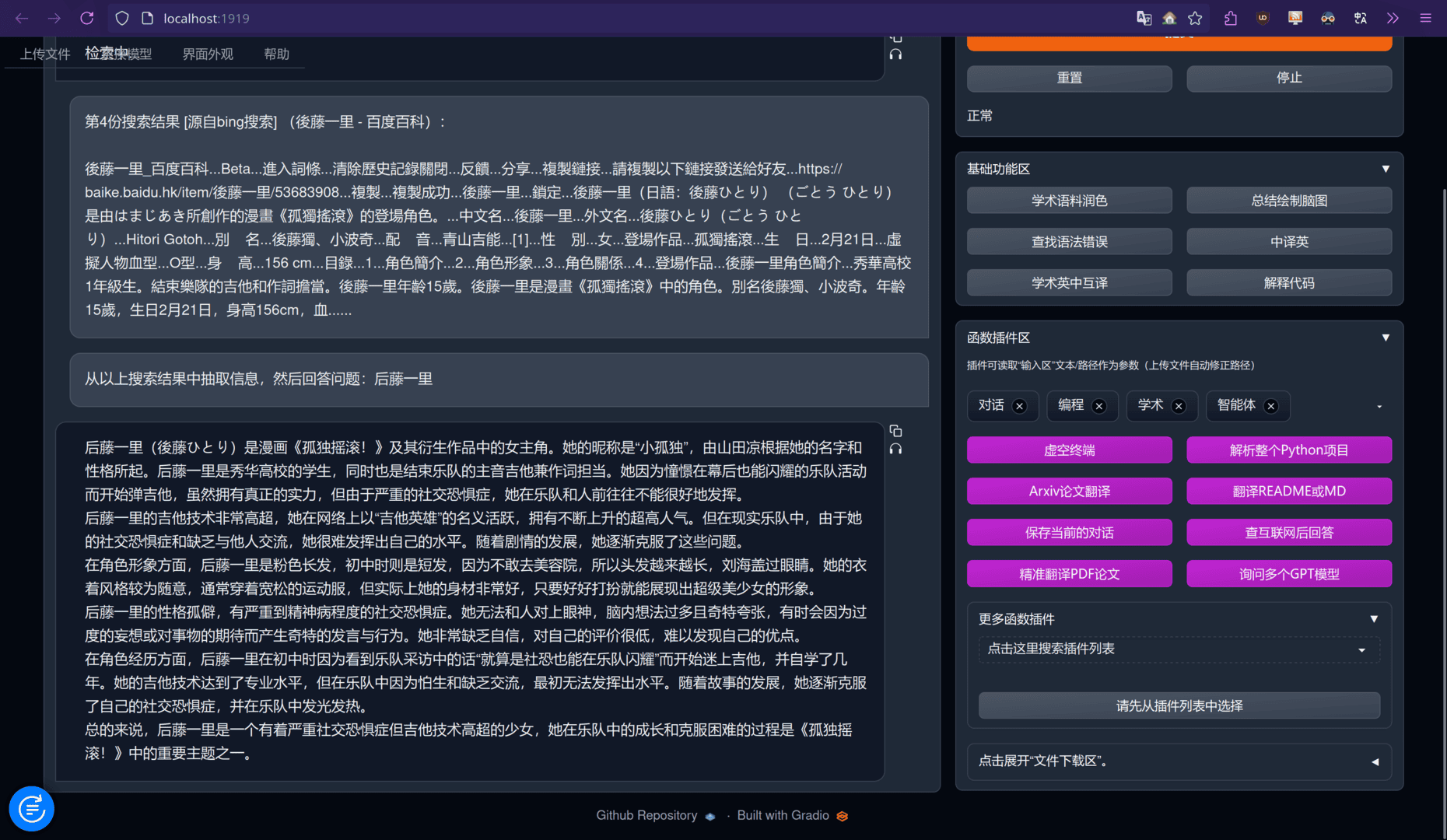
首先假设你已经有你自己的服务器以及域名了,例如此处我将其部署在上。当然你要是打算仅本地使用,只需要有电脑就行了(废话)。
随后遵从searxng官方docker教程走:
随后编辑下你的文件,其是给docker镜像中进行反代使用的。
如果你仅会在本地访问,不需要编辑文件中的,其默认就是
随后就好了,这时候你就可以访问之前设置的测试了。
或者是,取决于你的docker-compose版本
此时虽然searxng已经配置好了,但是为了能在gpt_academic中使用API调用还需要一些额外的操作。
默认情况下searxng并不会启用bing搜索,以及搜索的入参形式也不支持json形式,编辑:
随后在gpt_academic的配置文件(即config_private.py)中添加一行即可。本地访问的话填写即可。
以下是一些额外的配置

searxng默认开启了按照IP的速率限制器,为了防止自己被限制了,最gpt 教程好将自己加到白名单中。编辑:
可以配置很多个ip段
如果你部署的服务器和我一样,其宿主机上已经运行有一个Caddy反代服务了,那么在启动这个docker-compose时会提示你端口已经占用。你需要将中所有和Caddy相关的部分删掉(或者注释掉),随后编辑宿主机的:
如果你也开了CF的小黄云,需要自定义转发下发起方IP,否则searxng会一直将CF的服务器IP认为是请求方IP。
编辑:
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/242594.html原文链接:https://javaforall.net


