
rStar2-Agent:智能体推理技术报告(详细解读)
- 论文标题:rStar2-Agent: Agentic Reasoning Technical Report
- 研发机构:Microsoft Research(微软研究院)
- 论文地址:https://www.arxiv.org/pdf/2508.20722


- 小模型突破性能极限:14B参数的rStar2-Agent通过智能体强化学习(Agentic RL) ,在数学推理任务上达到前沿水平,超越671B参数的DeepSeek-R1,且生成的响应长度更短(效率更高)。
- 三大核心创新支撑:
- 高效RL基础设施:支持45K并发Python代码调用,平均延迟0.3秒,仅用64块MI300X GPU即可完成训练;
- GRPO-RoC算法:结合“正确时重采样(Resample-on-Correct)”策略,解决编码工具带来的环境噪声问题,提升推理稳定性;
- 高效训练流程:从“非推理SFT”起步,经三阶段RL训练,仅需510步(1周内)即可将预训练模型提升至SOTA。
3.标杆性实验结果:
- 在AIME24(美国数学邀请赛2024)中pass@1达80.6%;在AIME25中达69.8%。
- 泛化能力突出:仅经数学任务训练,却在科学推理(GPQA-Diamond)、工具使用(BFCL v3)、通用对齐(IFEval/Arena-Hard)任务上表现优异,甚至超DeepSeek-V3。
4.认知能力升级:模型展现“更聪明的思考”而非“更长的思考”——能自主判断何时使用Python工具、反思代码执行反馈、修正中间步骤,而非依赖冗长的思维链(CoT)。
当前大模型推理的核心进展依赖更长的思维链(Long CoT)和带可验证奖励的大规模RL(RLVR),代表性模型如OpenAI o系列、DeepSeek-R1、Gemini-2.5。但这类方法存在根本性缺陷:
- 中间错误难察觉:对于需精细步骤的难题,长CoT易出现“一步错、步步错”,且模型内部自反思(Self-Reflection)难以检测细微错误;
- 初始思路固化:若初始推理方向错误,长CoT会“一条路走到黑”,无法通过工具辅助切换思路;
- 奖励信号粗糙:现有RL多依赖“结果导向奖励”(仅看最终答案是否正确),若中间步骤存在工具错误(如代码语法错、逻辑错)但最终答案巧合正确,模型会误将“错误步骤”视为有效,导致轨迹质量低下。
为解决上述问题,研究者提出“智能体RL”——让模型在工具环境(如Python编码) 中交互,通过工具反馈调整推理。但规模化落地面临三大挑战:
- 环境噪声干扰:Python工具引入不可控噪声——模型生成的代码可能存在语法错误、逻辑错误或超时,环境返回的错误信息会占用 tokens 修正错误,而非推进推理;
- 基础设施压力:大规模RL训练中,单批次可能触发数万次并发工具调用,需构建“高可靠、低延迟”的代码执行环境,否则会导致GPU空闲(等待工具反馈)、训练停滞;
- 训练效率低下:传统RL需超大规模rollout(如16K→48K tokens),且多阶段训练依赖“推理SFT预热”,计算成本极高(需上千块GPU)。
让模型从“更长地思考(Think Longer)”升级为“更聪明地思考(Think Smarter)”:
- 工具自主使用:模型能判断“何时用工具”“用工具做什么”(如用Python验证中间结果、求解复杂计算);
- 反馈自适应调整:基于代码执行结果(正确/错误/超时)反思推理步骤,修正错误或优化思路;
- 低成本规模化:在有限GPU资源(64块MI300X)下,通过算法优化和基础设施设计,实现高效训练。
核心设计:让模型在Python环境中进行多轮交互推理,通过结构化工具调用和prompt模板,规范“推理-工具-反馈”的流程。

Rollout指“模型生成的完整推理轨迹”,传统RL是“单轮生成至EOS token”,而本文采用“多轮交互rollout”,流程如下:
- 初始轮(Turn 1):模型接收“系统prompt+问题”,生成推理步骤(标签)和工具调用(
标签),直至EOS;
- 工具执行:若存在
,环境提取代码并执行,将结果用
标签包装,以“用户角色”反馈给模型;
- 后续轮(Turn 2~T):模型基于“历史推理+工具反馈”,继续生成新的推理和工具调用,直至输出最终答案(标签)或达到最大轮数T(默认10~15轮)。
示例流程(以质数问题为例):
- Turn 1:模型生成推理(“需找最小质数p使n⁴+1能被p²整除”)+ Python代码(定义find_least_prime_and_m函数),环境返回结果(17, 110);
- Turn 2:模型反思(“基于结果,p=17,需验证110⁴+1是否能被289整除”)+ 验证代码,环境返回True;
- Turn 3:模型确认结果,输出最终答案\boxed{110}。
为避免解析歧义,采用结构化JSON格式封装工具调用,而非传统markdown或自定义token,示例如下:
{ "name": "execute_python_code_with_standard_io", # 工具名(带标准输入输出的Python执行) "arguments": { "code": "import sympy\n\ndef verify_divisibility(m,p):\n return (m4 +1) % (p2) == 0", # 代码块 "input": "110 17" # 标准输入(传给code的参数) } }
- 环境响应类型:代码执行后,环境返回4类结果,均用
包装:
- 成功有输出:返回程序stdout(如“True”);
- 成功无输出:返回IPython风格的空输出提示;
- 执行错误:返回错误信息+堆栈跟踪(如“SyntaxError: invalid syntax”);
- 超时:返回超时提示(如“TimeoutError: code ran for >5s”)。
优势:与LLM API的函数调用协议对齐,可扩展性强(后续可添加Matlab、R等工具),且解析无歧义。
Prompt是规范模型行为的核心,本文设计的模板包含3个关键部分:
- 角色与格式约束:明确“用户-助手”对话,要求推理步骤放标签,最终答案放标签,且答案需用\boxed{}包裹(便于自动提取);
- 工具说明:详细描述工具功能(如execute_python_code_with_standard_io的输入输出、参数要求),避免模型误用;
- 问题占位符:{Question}替换为具体任务,确保训练/推理的一致性。
模板示例(简化版):
<|im_start|>system A conversation between User and Assistant. Assistant must: - Put reasoning in
...
- Put answer in
...
(final result in \boxed{}) - Use tools via
...
(tool: execute_python_code_with_standard_io, params: code, input) <|im_end|> <|im_start|>user Problem: {Question} <|im_end|> <|im_start|>assistant 这是本文的算法核心,分为“GRPO基础”“核心挑战”“GRPO-RoC创新”三部分。
GRPO是为“群体轨迹(Group of Rollouts)”设计的RL算法,核心思想是“通过同一问题的多个轨迹对比,优化策略”,避免传统PPO中“单轨迹重要性采样偏差”的问题。
1. GRPO的目标函数
对于数据集D中的问题q和真实答案a,从旧策略π_old采样G个轨迹{o₁, o₂, …, o_G},新策略π_θ的优化目标为:

- 符号解释
- :第 个轨迹的第 个 token;
- :优势函数(衡量“当前轨迹 步”比“群体平均”好多少);
- :重要性采样裁剪阈值(默认 0.2,控制策略更新幅度);
- :KL 散度权重(约束新策略与参考策略 的偏差);
- :第 个轨迹的 token 长度。
2. 优势函数计算(A_{i,t})
GRPO的优势函数基于“群体奖励的统计量”计算,而非传统PPO的时序差分(TD),避免长轨迹的奖励偏差:
- r_i:第i个轨迹的奖励(0/1二元奖励,仅看最终答案是否与a一致);
- mean/std:G个轨迹奖励的均值和标准差,确保优势值标准化,稳定训练。
3. GRPO的关键修改(适配智能体RL)
为提升探索能力,本文对原始GRPO做了3处调整:
- 移除KL散度项(β=0):避免限制模型探索“工具辅助的新推理模式”;
- 采用Clip-Higher策略:将ε_high(上裁剪阈值)从0.2提升至0.28,鼓励模型探索“低概率但关键的token”(如工具调用触发词);
- 移除熵损失项:避免熵增长失控导致训练崩溃(传统熵损失为鼓励探索,但若过大,模型会生成无意义文本)。
GRPO虽为基础,但在“编码工具环境”中面临两大问题,导致训练效果差:
1. 环境噪声导致轨迹质量低
编码工具会引入“非推理相关噪声”——模型生成的代码可能语法错误、逻辑错误,环境返回的错误信息会让模型浪费tokens修正错误,而非推进推理。例如:
- 模型想计算“110⁴+1”,但代码写错为“110^4+”(语法错误),环境返回SyntaxError,模型需重新生成代码,占用额外tokens;
- 这类“带噪声的轨迹”若最终答案巧合正确(如重新生成代码后计算正确),会被奖励r_i=1,但中间步骤是低效的,模型会误学“错误步骤”。
2. 结果导向奖励无法惩罚中间错误
现有奖励仅看“最终答案”,无法区分“高质量正确轨迹”(无工具错误、步骤简洁)和“低质量正确轨迹”(多工具错误、步骤冗长)。传统GRPO训练中,“正确轨迹中的工具错误率”会快速下降后趋于稳定(Qwen3-14B约10%,Qwen2.5-32B约15%),模型持续生成低质量轨迹。
为解决上述问题,本文提出“正确时重采样(Resample-on-Correct, RoC)”策略,核心思想是:在GRPO的群体轨迹中,筛选“高质量正确轨迹”和“多样性错误轨迹”,提升策略更新的信号质量。
1. GRPO-RoC的核心设计原则
- 保留“结果导向奖励”(公式3):避免引入复杂的“步骤级奖励”或“工具错误惩罚”(这类设计需人工调参,易导致奖励 hacking);
- 通过“采样策略”过滤噪声:不直接惩罚中间错误,而是通过“重采样”将低质量正确轨迹排除在训练样本外,让模型只学“高质量正确模式”。
2. RoC的具体流程(分3步)
RoC分三步实现“过采样-筛选-下采样”,最终得到G个用于策略更新的轨迹
GRPO-RoC在“轨迹采样阶段”做了调整:传统GRPO采样G个轨迹,GRPO-RoC先过采样2G个轨迹,再通过RoC筛选回G个轨迹,流程如下:
- 过采样(Oversampling):对每个问题q,从旧策略中采样个轨迹(而非GRPO的G个),分为正样本集()和负样本集(),满足。
- 筛选与下采样(Filtering & Downsampling):
- 负样本筛选:均匀下采样,数量为。目的是保留多样化的失败模式(如推理错误、工具调用时机错误),为模型提供全面的“避错信号”。
- 正样本筛选:按“质量评分”优先选择高质量轨迹,下采样得到,数量为。质量评分由“工具错误率()”和“格式错误率()”加权求和(),采样概率与成反比(即越小,越容易被选中)。
,满足。3. 正样本质量评分(p_total)
正样本的质量由“工具错误率(p_err)”和“格式错误率(p_format)”共同决定,总评分p_total = p_err + p_format,评分越低,轨迹质量越高。
- 工具错误率(p_err):衡量轨迹中工具调用的错误比例,公式如下:
示例:某轨迹有3次工具调用,1次超时错误,则p_err=1/3≈0.33。 - 格式错误率(p_format):衡量轨迹是否违反结构化格式要求(如多标签、在之后),公式如下:
示例:某轨迹有3轮推理,2个标签,则p_format=(2-1)/3≈0.33。
4. GRPO-RoC的目标函数
将 GRPO 的目标函数中的“原始轨迹 ”替换为“筛选后轨迹 ”,优势函数基于 的奖励计算,公式如下:

- 其中
- (延续 Clip-Higher 策略)。
5. GRPO-RoC的效果
相比传统GRPO,GRPO-RoC能持续降低“正确轨迹中的工具错误率”:
- Qwen3-14B:训练500步后,工具错误率从10%降至5%以下;
- Qwen2.5-32B:从15%降至8%以下;
同时,轨迹长度显著缩短,推理精度提升,证明其能高效筛选高质量轨迹。
基础设施是“智能体RL规模化”的关键,本文设计了“高吞吐量代码环境”和“负载均衡rollout调度器”,解决“并发工具调用”和“GPU idle”问题。
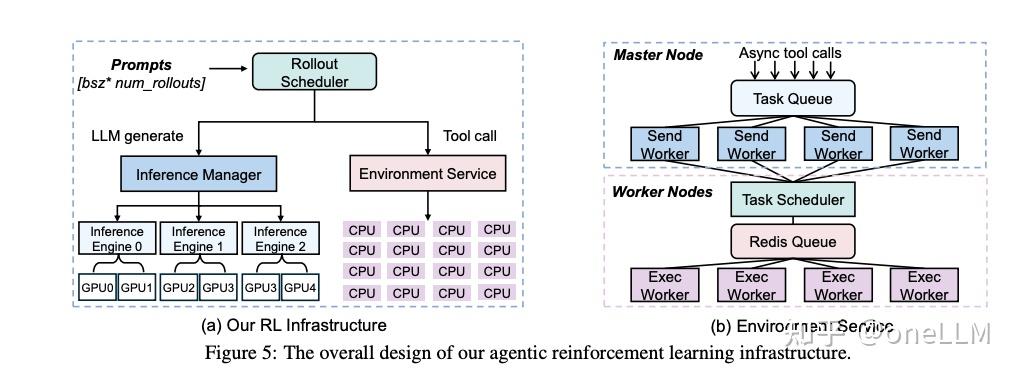
核心目标:支持45K并发工具调用,平均延迟≤0.3秒,且与主训练流程隔离(避免代码风险影响训练)。
环境基于“主从节点架构”构建,部署在64块MI300X GPU集群的CPU核心上,分为3层:
| 层级 | 组件 | 功能 |
|---|---|---|
| 主节点(Master Node) | 1. 任务队列(Redis);2. 32个发送Worker(Send Worker) | 1. 接收RL rollout的工具调用请求,统一入队;2. 批量调度请求至从节点 |
| 从节点(Worker Node) | 1. 任务调度器(Task Scheduler);2. 1024个执行Worker(Exec Worker) | 1. 动态分配请求至空闲执行Worker;2. 执行Python代码,返回结果 |
| 结果反馈层 | 发送Worker → RL Rollout流程 | 将执行结果包装为 ,返回给模型用于下一轮推理 |
- 批量调度:发送Worker从任务队列中批量取请求(每批最多64个),要么满批调度,要么超时(固定阈值)调度,减少网络往返次数;
- 动态负载均衡:从节点的任务调度器实时监控执行Worker的负载,将新请求分配给空闲Worker,避免单Worker过载;
- 隔离执行:每个执行Worker是独立进程,代码在沙箱中运行(限制CPU/内存使用),避免无限循环、恶意代码占用资源;
- 异步验证:将“答案正确性验证”(如Math-Verifier)也offload到该环境,与工具调用并行执行,避免验证耗时导致GPU idle。
- 吞吐量:每训练步可处理45K工具调用(远超传统环境的10K);
- 延迟:从请求发出到结果返回,平均0.3秒(包括队列等待、代码执行、结果封装);
- 稳定性:连续7天训练无崩溃,错误率(如代码执行失败)≤2%。
传统RL的rollout采用“静态分配”(将rollout请求均匀分配给GPU),但智能体RL的“多轮rollout”存在“长度不均”,导致GPU idle和KV缓存溢出。

- GPU idle严重:若GPU A分配的轨迹均为短轨迹(如5轮),GPU B分配的轨迹为长轨迹(如15轮),GPU A会提前完成,等待GPU B,导致 idle 时间占比超30%;
- KV缓存溢出:推理引擎(如SGLang)需用KV缓存存储中间计算结果,若GPU分配的轨迹过多,KV缓存会溢出,需evict(驱逐)一半未完成轨迹,重新计算,浪费30%~50%算力。
核心思想:基于GPU的“剩余KV缓存容量”动态分配rollout请求,而非均匀分配,步骤如下:
- 实时监控:调度器实时查询每个GPU的剩余KV缓存容量(根据最大rollout长度L估算可容纳的轨迹数K);
- 动态分配:将rollout请求分配给剩余KV缓存充足的GPU(如GPU 0剩余容量可容纳K₁个轨迹,分配K₁个;GPU 1可容纳K₂个,分配K₂个);
- 异步工具调用:工具调用请求不等待当前GPU的所有轨迹完成,而是生成后立即发送至代码环境,避免GPU等待工具反馈。
- GPU利用率:从静态分配的60%提升至90%以上;
- 重算率:KV缓存溢出导致的重算率从35%降至5%以下;
- 训练速度:单步训练时间从120秒缩短至45秒,整体训练效率提升2.6倍。
本文设计了“非推理SFT→三阶段RL”的流程,避免传统“推理SFT预热”的高成本,仅用510步(1周)完成训练。
传统SFT会加入“推理数据”(如数学CoT样本),但本文的SFT仅目标:教会模型“指令跟随”和“工具使用格式”,不提升推理能力,避免:
- 推理SFT过拟合:若SFT引入特定推理模式,RL难以探索新模式;
- 初始轨迹过长:推理SFT会让模型生成冗长CoT,增加RL训练成本。
| 数据集类型 | 来源 | 规模 | 目标 |
|---|---|---|---|
| 函数调用数据 | 1. ToolACE11K;2. APIGen-MT-5K;3. Glaive-function-calling-v2-101k;4. Magicoder-48K(重格式为JSON) | 165K | 教会模型生成结构化工具调用(如 标签、JSON参数) |
| 指令跟随数据 | Tulu3 post-training数据集(用o4-mini重写响应) | 30K | 提升模型对“用户问题→助手推理”的指令理解 |
| 聊天数据 | LLaMA-Nemontron post-training数据集(用o4-mini重写prompt) | 27K | 保持模型的通用对话能力,避免SFT后对齐退化 |
SFT后,模型在“工具使用”“指令跟随”“聊天”能力上显著提升,而“数学推理”能力与基模型(Qwen3-14B-Base)相当:
- 工具使用(BFCL v3):从0→63.1%;
- 指令跟随(IFEval):从0→83.7%;
- 数学推理(MATH-500):基模型62.0%→SFT后57.4%(略有下降,证明未引入推理能力)。
基于SFT模型,本文设计三阶段RL训练,逐步提升“轨迹长度”和“任务难度”,仅需510步完成,
| 阶段 | 训练数据 | 最大轨迹长度 | 训练步数 | 目标 | 关键结果 |
|---|---|---|---|---|---|
| Stage 1 | 42K高质量数学题(整数答案) | 8K tokens | 300步 | 让模型适应“工具辅助推理”,形成基础策略 | AIME24:3.3%(SFT后)→72.1%;AIME25:0%→64.2% |
| Stage 2 | 同Stage 1 | 12K tokens | 85步 | 突破长度限制,处理更复杂推理(需多轮工具调用) | AIME24:72.1%→77.0%;AIME25:64.2%→64.8% |
| Stage 3 | 17.3K难样本(Stage 2模型8次全对的题移除) | 12K tokens | 125步 | 提升模型对难题的推理能力 | AIME24:77.0%→80.6%;AIME25:64.8%→69.8% |
- RL数据构建:
- 来源:17K DAPO整数题 + 93K AoPS题(OpenMathReasoning) + 937 Project Euler题;
- 筛选:仅保留“整数答案”题(避免代数表达式验证困难),用Qwen3-32B生成16次响应,仅保留“至少2次答案一致”的题,最终得到42K高质量题;
- 难样本筛选:用Stage 2的模型对42K题各生成8次rollout,移除“8次全对”的题,剩余17.3K难样本。
- 训练参数:
- 学习率:1e-6(AdamW优化器,线性warm-up 20步);
- batch size:512 prompts/步,每个prompt采样2G=32个rollout,筛选后保留G=16个;
- 最大轮数T:Stage 1~2为10轮,Stage 3为15轮(难题需更多工具交互)。
- 效率优势:
- 传统RL(如DeepSeek-R1)需≥9K步,轨迹长度16K→48K;
- 本文仅510步,长度8K→12K,64块MI300X 1周完成,计算成本降低90%以上。
本文分享了2次失败尝试,为后续研究提供参考:
- 过长过滤(Overlong Filtering):
- 方案:移除“超过最大长度的截断轨迹”(不分配奖励),避免模型因“长轨迹被惩罚”而困惑;
- 结果:模型生成的过长轨迹比例反而上升(无负反馈,模型不纠正重复行为);
- 教训:需保留“截断轨迹的负奖励”(r_i=0),让模型学习控制轨迹长度。
- n-gram重复检测:
- 方案:降低“含n-gram重复的正确轨迹”的采样概率(如连续2次生成相似工具调用);
- 结果:推理精度下降,因模型“用相似工具调用验证结果”被误判为重复;
- 教训:避免复杂的“中间步骤规则”,仅用“结果奖励+RoC筛选”,更鲁棒。
实验围绕“数学推理性能”“泛化能力”“消融实验”展开,基模型为Qwen3-14B(最终模型rStar2-Agent-14B)和Qwen2.5-32B。
| 模型 | 规模 | 推理SFT | MATH-500 | AIME24 | AIME25 | HMMT25 |
|---|---|---|---|---|---|---|
| OpenAI o3-mini(medium) | – | – | 98.0% | 79.6% | 77.0% | 53.0% |
| DeepSeek-R1 | 671B | ✓ | 97.3% | 79.8% | 70.0% | 44.4% |
| Claude-Opus-4.0(Think) | – | ✓ | 98.2% | 76.0% | 69.2% | – |
| QWQ-32B | 32B | ✓ | 98.0% | 79.5% | 65.8% | 47.5% |
| rStar2-Agent-14B | 14B | ✗ | 97.8% | 80.6% | 69.8% | 52.7% |
关键结论:
- 小模型超大规模模型:14B的rStar2-Agent超越671B的DeepSeek-R1(AIME24 80.6% vs 79.8%),证明智能体RL的效率优势;
- 无推理SFT仍达SOTA:相比需推理SFT的模型(如QWQ-32B、Claude-Opus),rStar2-Agent仅用非推理SFT,仍在AIME24/25/HMMT25上领先;
- 响应长度更短(表4):rStar2-Agent在AIME25的平均响应长度为10943.4 tokens,远短于DeepSeek-R1-Zero(17132.9)、Qwen3-14B(17521.9),证明“更聪明的思考”而非“更长的思考”。
rStar2-Agent仅经“数学任务RL训练”,但在其他领域表现优异:
| 任务类型 | benchmark | DeepSeek-V3 | rStar2-Agent-14B(SFT后) | rStar2-Agent-14B(RL后) |
|---|---|---|---|---|
| 科学推理 | GPQA-Diamond | 59.1% | 42.1% | 60.9% |
| 工具使用 | BFCL v3 | 57.6% | 63.1% | 60.8% |
| 通用对齐 | IFEval(strict) | 86.1% | 83.7% | 83.4% |
| 通用对齐 | Arena-Hard | 85.5% | 86.8% | 86.6% |
关键结论:
- 科学推理迁移:RL后GPQA-Diamond从42.1%升至60.9%,超DeepSeek-V3,证明数学推理模式可迁移至科学领域;
- 不影响其他能力:工具使用、通用对齐任务的性能与SFT后相当,未因数学RL导致能力退化。
在Qwen2.5-32B上,rStar2-Agent(GRPO-RoC)显著优于传统CoT RL和其他工具RL:
| 模型 | 工具使用 | 推理SFT | MATH-500 | AIME24 | AIME25 | RL步数 |
|---|---|---|---|---|---|---|
| DAPO-Qwen-32B(CoT RL) | ✗ | ✗ | 90.3% | 50.0% | 32.1% | >5000 |
| ReTool-32B(工具RL)Agent 智能体 | ✓ | ✓ | 93.4% | 67.0% | 49.3% | 400 |
| rStar2-Agent-Qwen2.5-32B(GRPO-RoC) | ✓ | ✗ | 94.8% | 69.4% | 57.3% | 700 |
结论:GRPO-RoC无需推理SFT,仍在AIME24/25上超ReTool,且步数更少(700 vs 400,因ReTool仅训1阶段)。
对比“GRPO-RoC”“GRPO with Tool(无RoC)”“DAPO(无工具)”:
- 精度:GRPO-RoC在AIME24 500步达70%,超GRPO with Tool(62%)和DAPO(50%);
- 轨迹长度:GRPO-RoC的平均轨迹长度比GRPO with Tool短20%~30%;
- 工具错误率:GRPO-RoC的错误率持续下降,而GRPO with Tool趋于稳定。
通过“高熵token分析”(高熵代表模型不确定,触发探索/反思),发现rStar2-Agent的两大认知行为:
- 分叉token(Forking Tokens):如“But before”“double-check”“rerun”,触发模型自反思,验证中间步骤(类似人类“回头看”);
- 工具反馈反思token:如“The error occurred because”“I can simply check”,模型基于工具错误反馈调整代码,或基于正确反馈验证结果,体现“环境自适应能力”——这是传统CoT模型不具备的。
当训练超过510步(Stage 3结束)后,模型会出现“性能崩溃”:
- 现象:推理精度下降,奖励信号震荡,轨迹长度骤增;
- 原因:推测为“模型容量限制”——14B模型的预训练推理能力已达上限,RL无法进一步突破;
- 启示:智能体RL的核心价值是“高效触达基模型的性能上限”,而非无限制提升,本文510步已实现这一目标。
- 算法创新:提出GRPO-RoC,解决编码工具的环境噪声问题,高效筛选高质量轨迹;
- 基础设施创新:设计支持45K并发的代码环境和负载均衡调度器,降低训练成本;
- 训练流程创新:“非推理SFT+三阶段RL”,仅用510步(64 MI300X 1周)让14B模型达SOTA;
- 认知能力升级:模型展现“工具自主使用+反馈自适应”的智能体行为,超越传统长CoT。
- 扩展工具类型:将Python工具扩展到Matlab(科学计算)、SQL(数据查询)等,支持更广泛推理任务;
- 多智能体协作:让多个rStar2-Agent分工协作(如一个负责推理,一个负责工具调用),解决更复杂问题;
- 更大模型适配:在70B/175B模型上验证GRPO-RoC,探索是否能突破当前性能上限。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/245243.html原文链接:https://javaforall.net


