
- 集中、转换和存储数据
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。 - 输入、过滤器和输出
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。 - 采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择,可以同时从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
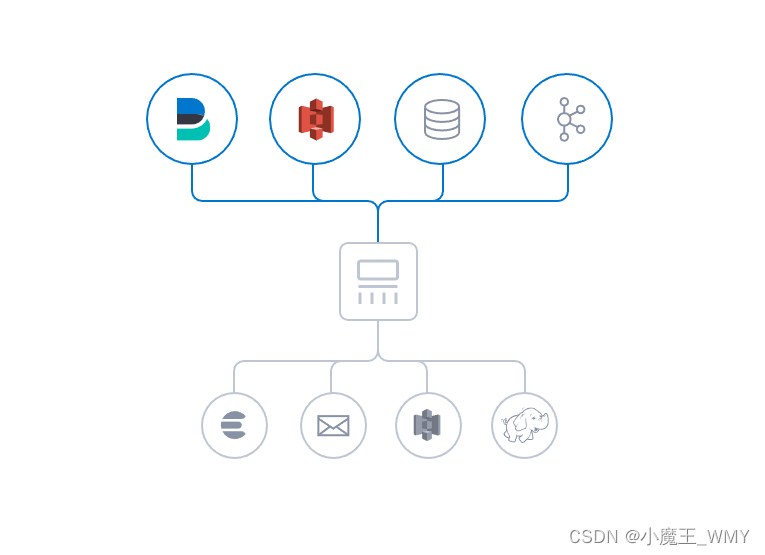

- 实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便进行更强大的分析和实现商业价值。
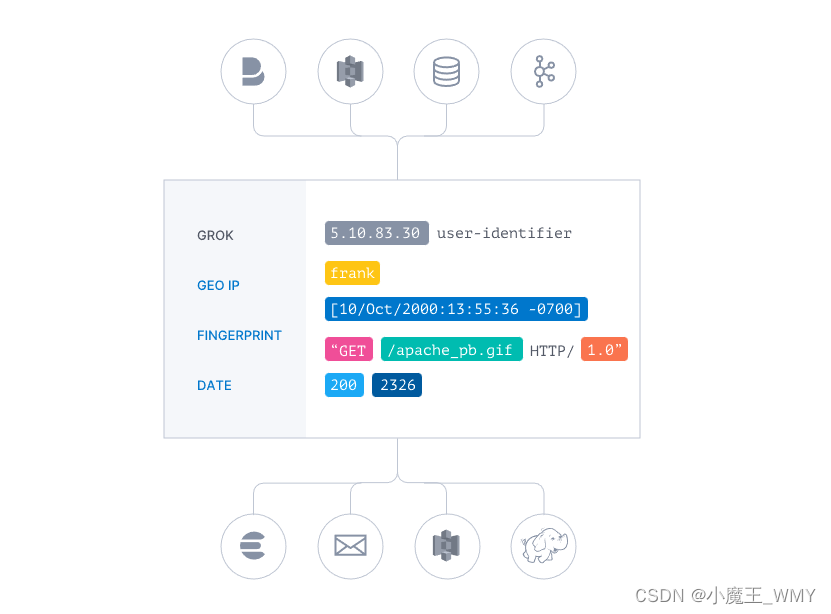
- 可以选择自己的存储库,导出需要的数据
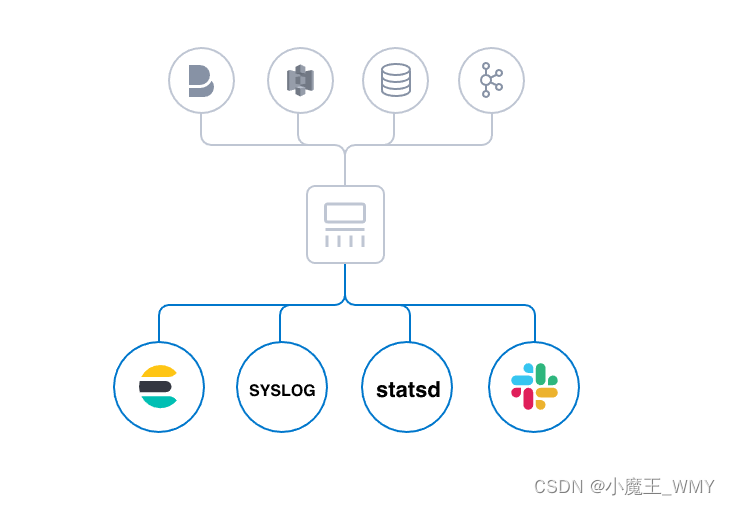
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。 - 以自己的方式创建和配置管道
Logstash 采用可插拔框架,拥有 200 多个插件。您可以将不同的输入选择、过滤器和输出选择混合搭配、精心安排,让它们在管道中和谐地运行。
首先从官网下载对应的版本,然后解压即可。以Linux版本为例,使用tar -zvxf命令解压过后的logstash文件夹如下图所示。

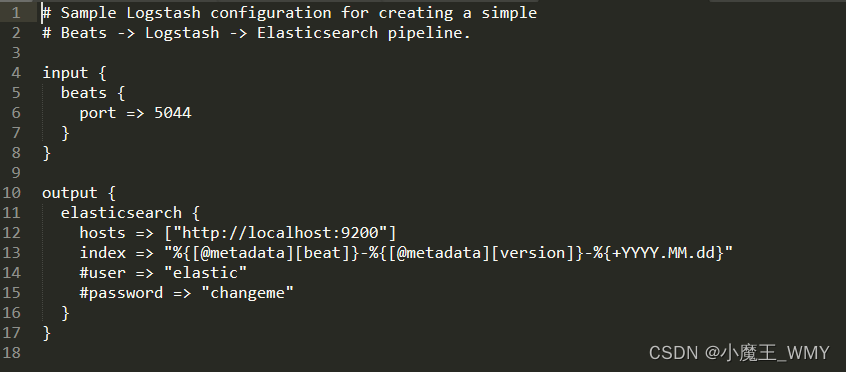
Logstash的使用主要是对config文件下的logstash.conf文件进行操作,在其中完成数据的收集、解析和输出的操作。Logstash最主要的文件是logstash-*.confg文件,该文件主要分为三个部分:input、filter、output,这三个部分管理的就是logstash收集数据、处理数据和输出数据,在三个模块中可以设置获取数据的方式、处理数据成对应的数据结构、输出到对应的存储环境。在解压过后会在config文件夹默认生成一个logstash-sample.conf,里面默认配置的input和output部分。
因为默认的配置不符合自己的环境,所以把conf文件修改成最简单的控制台输入输出。

配置好conf文件后就是要启动Logstash,Logstash的启动文件是在bin目录下的logstash脚本文件,具体的命令是
-f是为了指定对应的conf文件进行执行,因为在Logstash中可以配置多个conf文件,其中conf文件的路径建议使用绝对路径,相对路径本人在使用过程出现过错误,可以在服务器上使用pwd命令快速查到绝对路径。 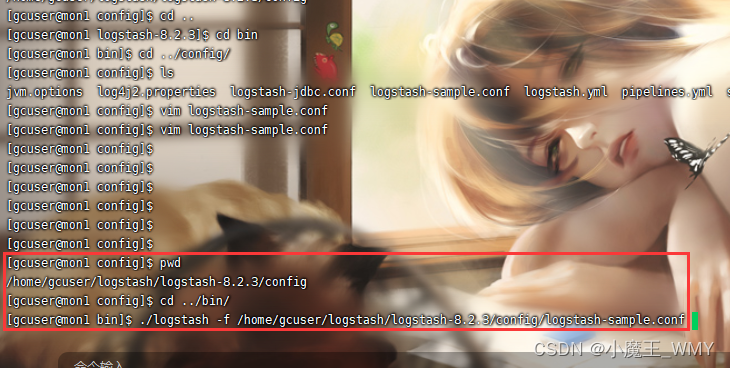
启动logstash后需要有一个地方需要注意,这也是自己在启动过程中发现的小问题吧。在下图第一处标红处的程序会停留一段之间,大概十几秒或者更长,你们可以根据提示作出对应的修改,本人还没有尝试过。当出现第二处标红的信息,说明Logstash启动成功!

Logstash启动成功就可以在控制进行简单的输入,如“helle,world”,Logtash会在控制进行输出。“message”保存的就是我们的输入信息。

这份配置文件是本人百度了很多的文章才根据自己的需求整合出的感觉,感谢感谢。下面就根据input、filter和output这三个部分说明为啥要这样配置。
- input
因为我的需要是从数据库获取数据,所以直接选择jdbc的来源,如果需要查看更多的数据来源,可以参考官方input说明,英文不好的要生嚼哈。关于jdbc的一些配置说明都已经写过备注,这里说明一些主要的字段配置。如果使用jdbc的mysql数据库,就需要配置Logstash配置一个mysql驱动,这里填写的就是mysql驱动的路径;
谈论其他参数之前首先需要讲解一下这个参数,既然要获取数据库的数据那就必须要使用sql来查询数据,jdbc模块提供了两种方式给我们选择。一种是在首先在sql文件中写好一个sql,然后在中配置sql文件的路径,这里都建议使用绝对路径。另一种是在参数中直接填写sql。两种方式都可以选择,可以根据实际进行使用。这里需要注意一下:last_sql_value这个参数,这个无论是直接写sql还是在sql文件中写sql,只要需要条件查询那就会需要使用它,这个参数后面使用到会继续说明;
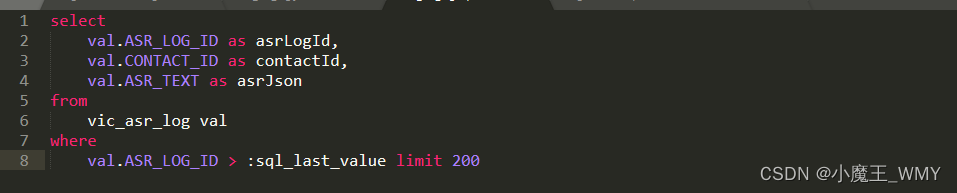
既然刚刚说道了使用条件查询,那必然涉及到数据库中的一个字段,这个参数是确定是否使用其他字段名,而非默认的字段名;
这个参数就是确定需要进行条件查询的字段名,同时sql中也需要查出该字段信息,如果sql中使用了别名,那这里也需要使用别名,保存的参数和sql中:last_sql_value参数对应的是同一个信息,只是一个是对数据库,一个是对应Logstash自己,如果sql中涉及到多个参数条件该如何保存,这个本人还没有研究过;
如果需要进行条件查询,那就需要我们提前提供一个条件的默认值,这样才方便进行增量查询,避免查询重复的数据,这个参数就是确定是否使用保存的条件值;
既然需要保存条件值,那怎么保存,保存在哪里。我们需要把条件值保存在一个txt文档中,再在这个参数里配置txt文件的路径,那文件里面具体如何写值呢?
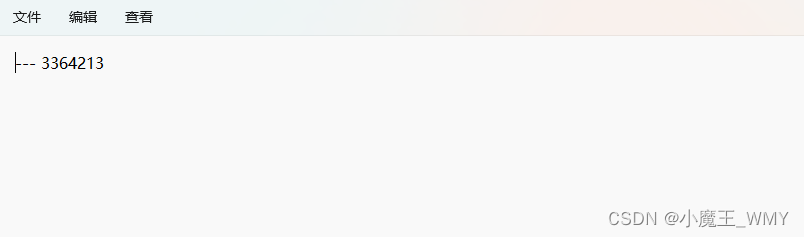
就是这么简单,就是保存一个值,也不用说明字段名,英文Logstash会根据之前配置的参数进行字段和值的匹配,如果配置好这个四个参数就可以进行增量查询,每次查询过后就会更新最新的条件值到txt文档中;
cron表达式,配置好时间表达式后Logstash就会当做定时任务一样,定时执行。需要注意的是Logstash的cron和一般的cron表达式还是有点差别,可以看看这篇文章,再到在线cron表达式生成网站生成个cron表达式比较一下;
这个参数就是说明是否区分查询出的sql字段信息是否区分大小写; - filter
filter模块是我在使用过程最难受的部分,简单的真简单,难的是真难。具体可以参考官方文档,我之前竟然没有找到这个文档。
先看一下我们从sql中查询的出数据字段,查询就三个字段,一个字段是条件值,第二个字段是后面存储到ES中作为条件,主要就是对第三个字段进行数据解析。
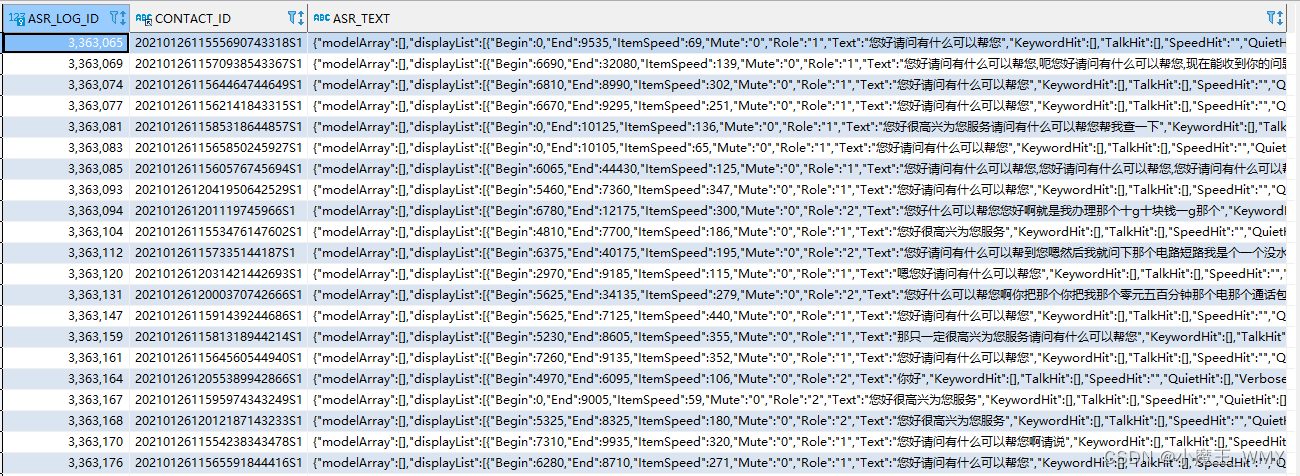
先来简单看一下asr_text字段的数据格式

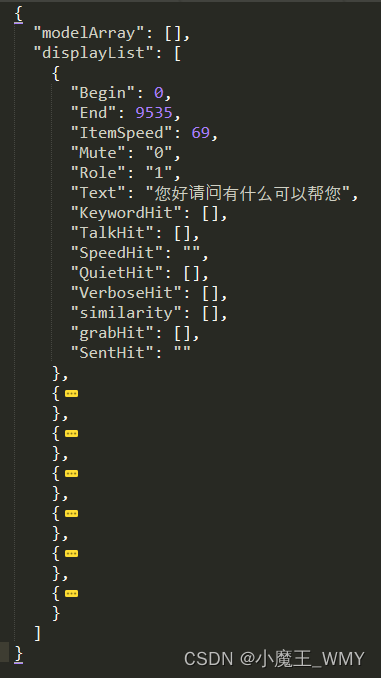
格式化后的数据清晰很多, 我需要就是吧displayList字段中的Text字段信息拿到,并需要根据Role字段先进行判断,然后把所有的Text内容进行拼接。这里涉及的结构就有判断和循环,如果使用java写,那简单的不要不要的,但logstash要怎么写。首先就需要拿到displayList,然后再循环里面进行判断,再进行拼接。但在实际情况中,asr_text输出的是JSON字符串,并不是JSON对象,那就还得需要JSON格式化。

在filter中使用json模块对数据进行格式化然后数据就变成了这样,可以看到displayList和modelArray都被单独格式化一个新的字段进行显示。


数据有了,然后就是进行循环和选择判断,使用ruby,不要问用为啥,因为好用,具体语法参考这里ruby插件有两个属性,⼀个init 还有⼀个code。init属性是⽤来初始化字段的,你可以在这⾥初始化⼀个字段,⽆论是什么类型的都可以,这个字段只是在ruby{}作⽤域⾥⾯⽣效。code属性使⽤两个冒号进⾏标识,你的所有ruby语法都可以在⾥⾯进⾏。是在ruby中初始化一个全局变量,需要使用关键字,保存的就是之解析过的json数据,通过方法获取对应的属性数据,通过上面的步骤已经把需要解析的集合数据存放到array,下一步就是循环解析判断。是ruby的迭代器语法结构,可以类比于for循环结构,在迭代中或获取对象的属性需要使用的方式来获取。至此,弄清楚如何在ruby中写循环结构和获取具体的属性,就可以得到我们想要的数据,最后再把获取到的数据通过方法赋值到一个新的属性中。通过Logstash的shuju 解析给我们最后的数据结构新增了很多的我们不需要的数据,所以我们需要删减,使用模块进行删减。
就是剔除我们不需要的属性数据。通过filter的解析处理把数据处理成我们想要的数据结构,下面就是output到ES。
- output Grok 教程
既然要把数据输出到ES,那就肯定要在es中配置好es相关信息,output的参数就是用来保存ES地址信息;用来匹配es中的索引,有则插入,无则新建;保存文档类型,最新的ES已经是默认_doc类型,我们这里写_doc类型;保存索引的ID,要保持唯一性,刚好数据中存在唯一性字段信息,就使用了对应的字段保存,格式是;
这里需要主要注意的是如果我们已经在ES中建立好索引,那么使用以上的参数就已经足够,但如果要考虑到如果一直把增量数据存在一个索引中,最后造成的结果就是此索引数据量特别大,十分不方便后续使用。所以这里做了一个操作,按月建立索引,通过这种方式,如果Logstash根据索引名检测到ES中已存在该索引,就直接添加数据,如果不存在就先新建一条索引,然后再存储数据。但是在ES中建过索引的知道我们需要映射字段,那在Logstash中是怎么映射字段了呢?通过参数,我们首先需要在一个JSON文件中写好映射信息,然后保存到参数中
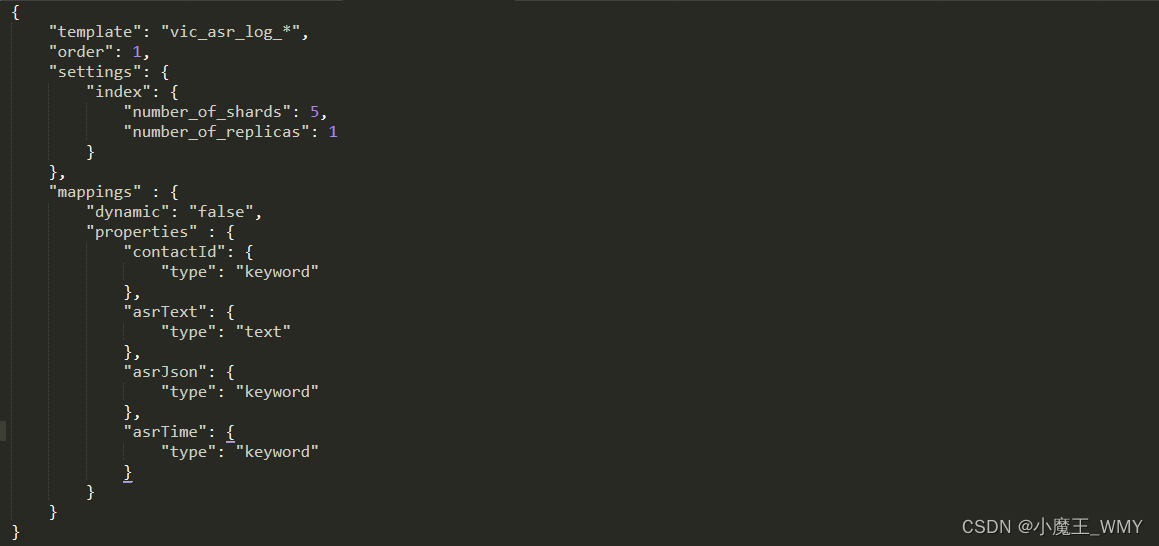
上面就是我写映射文件,很简单,网上说的很复杂,而且各种参数五花八门,所以我直接参考了ES里面自带的参数模板http://localhost:9200/_template。

直接拎出来一个进行模仿,因为这样已经满足了我的功能需求。保存的是模板名称,保存的是否覆盖模板,我们因为在ES中可能存在一个已有模板名与这个模板名称相同,所以我们需要进行覆盖,是是否进行模板管理。还需要说明的是,这里的索引才用的是拼接的形式,前部是固定的索引名,后面拼接的是时间参数字段,那这个参数字段是从哪里来的?
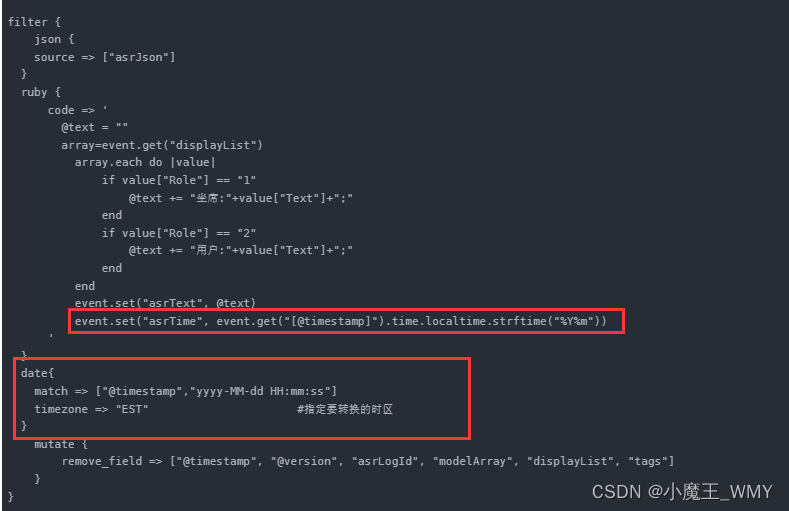
在最初的完整的配置文件中其实在ruby中还添加了一个字段信息,这个是字段是通过Logstash解析自带返回的进行处理的,具体为什么用这种方式而不才用网上说的的方式,可以参考这篇文章。还需要注意的是JSON映射文件中的字段名称需要与索引名相对应,但这里的索引名是会根据月份进行改变的,索引在JSON文件中采取这种通配符的方式。
通过input的数据获取、filter的数据解析、output的数据输出,我们最终完成了我们想要的功能。

发布者:Ai探索者,转载请注明出处:https://javaforall.net/245463.html原文链接:https://javaforall.net


