
近年来,“生成式人工智能(GenAI)”火遍全网,但很多人对它和 AIGC、多模态、AI Agent 的关系依然混淆。本文将从概念出发,结合工程实践,帮你厘清这四者的边界与联系。
GenAI(Generative AI)是生成式人工智能的简称,本质是指:
利用大模型对输入内容进行上下文建模,并生成新内容的人工智能系统。
它涵盖了:
- 文本生成(如 ChatGPT、Claude)
- 图像生成(如 DALL·E、SD)
- 音频生成(如 MusicGen)
- 代码生成(如 Copilot)
- 多模态生成(如 GPT-4V、Gemini)
AIGC(AI Generated Content)是 GenAI 的主要应用场景。
特点是生成高质量内容,包括:
- 写文案、摘要、翻译
- 生成图片、头像、插画
- 生成语音、音乐、视频
你可以简单理解为:
GenAI = 能力框架
AIGC = 内容输出的结果应用
多模态(Multimodal)是指模型能同时处理多种模态的数据输入与输出:
- 输入可以是图像 + 文本 + 音频
- 输出可以是文字回答 Agent 智能体 / 图像描述 / 结构标签
代表模型有:
- CLIP:图文匹配
- LLaVA:图像问答
- GPT-4V / Gemini:全模态问答生成
所以:多模态是 GenAI 的一种感知扩展方式,不是独立方向。
AI Agent(智能体)基于大模型能力,结合指令跟踪、上下文记忆、函数调用,实现生成+执行。
常见特征:
- 自主规划任务(如 LangChain Planner)
- 调用 API 或工具执行指令(如 ReAct)
- 多轮交互、流程跟踪(如 AutoGPT)
它是将 GenAI 从“内容生成”拓展为“行为执行”的进阶形态。
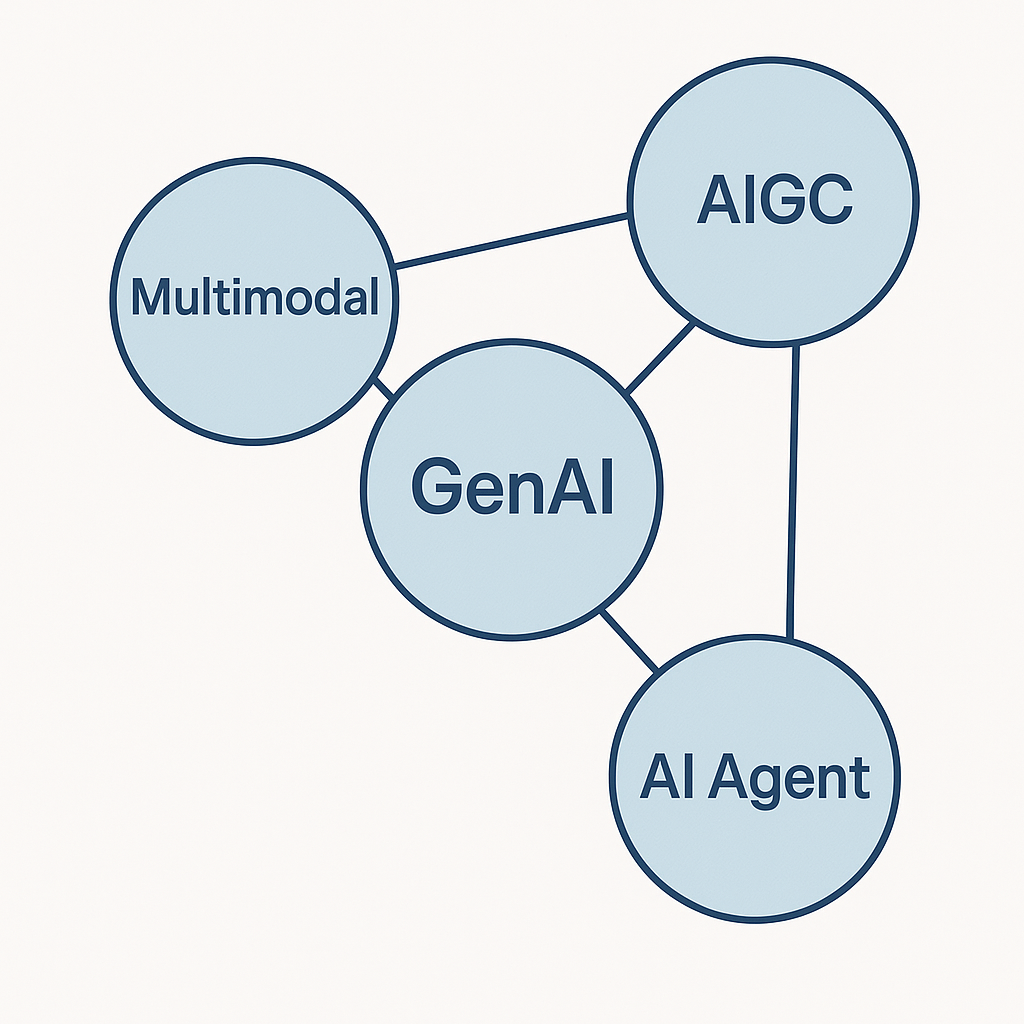

注:GenAI 是总集合,多模态是感知扩展,AIGC 是输出内容,Agent 是行为执行
- 如果你想做“产品内容生成” → 学 AIGC 应用 + 模型调用
- 如果你想做“能力封装 / 工程部署” → 研究 GenAI 工程栈(如推理优化、服务化部署)
- 如果你关注“系统执行 / 智能体架构” → 研究 Agent + 工具链框架(如 LangChain、AutoGPT)
- 如果你是做底层算法 / 感知融合 → 深入图文多模态模型(如 BLIP、LLaVA)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/245489.html原文链接:https://javaforall.net


