
记录在n8n过程中遇到的一些坑,引人思考的那种,持续补充中….
1️⃣ 问题背景
常规场景http request节点使用比较简单,一般不会有问题,但是一旦上个节点的输出结果格式比较多,比如包含换行符、特殊字符等,http request节点很容易报错:
典型输入示例(Git / 终端日志):
即使在前面已经加了 参数清洗 / Code 节点处理逻辑 ,在 HTTP Request 节点中,某些场景下依然会报错。
2️⃣第一反应:不是已经”清洗过”了吗?
一开始的直觉判断是:
“是不是哪里有非法字符?”
“是不是有换行符?”
“是不是 、、中文导致的?”
n8n 工作流 教程
于是常见的处理手段都上了:
- 去掉多余换行
- trim
- replace 特殊字符
- 拼接成一整段字符串
甚至在 Code 节点里已经确认:typeof result === ‘string’
逻辑上看,一切都没问题。 但只要在 HTTP Request 节点里这样用👇,依然可能直接炸。
3️⃣ 关键认知:不是”内容问题”,而是”JSON 解析阶段的问题”
真正的坑点在于这一层:
HTTP Request 节点不是在”发送前”才处理 JSON,而是在”解析参数阶段”就已经开始校验 JSON 了。
换句话说,即使你在 Code 节点里已经把内容处理得”很干净”:
- 逻辑正确 ✅
- 变量存在 ✅
- 内容是字符串 ✅
但只要 HTTP Request 节点被配置为「JSON Parameters / JSON Body」:
n8n 在内部会做一件事:
先把整段内容当成 JSON 模板解析
👉 再做表达式替换
👉 再发送请求
而问题就出在 “解析 JSON 模板”这一步。
4️⃣ 为什么这类”长日志 / 终端噪声”必然高风险?
这类输入天然具备几个特征:
- 大量 (JSON 的关键分隔符)
- 、、、 等 shell / git 符号
- 多行换行
- 中英文混合
- 极长字符串
⚠️ 哪怕其中只有一处在模板解析阶段被”误判为结构字符” ,
整个 HTTP Request 节点就会在表达式替换之前直接失败。
这也是为什么:
👉 “已经清洗过,但还是偶现报错”
因为你清洗的是”业务层内容”,而炸的是”n8n 的 JSON 模板解析层”。
5️⃣ 核心结论(非常重要)
日志 ≠ JSON
日志只能作为 JSON 中的「字符串值」存在,
而不能直接参与 JSON 结构的解析过程。
一旦 HTTP Request 节点被设置为 JSON 参数:
- 你就必须为 JSON 解析阶段 负责
- 而不是只为 业务逻辑正确性 负责
6️⃣ 实战层面的正确姿势(简述)
在这类场景下,结论非常明确:
✅ 更稳妥的方式只有两类
- HTTP Request 使用 RAW / Text Body
- 完全绕开 JSON 解析
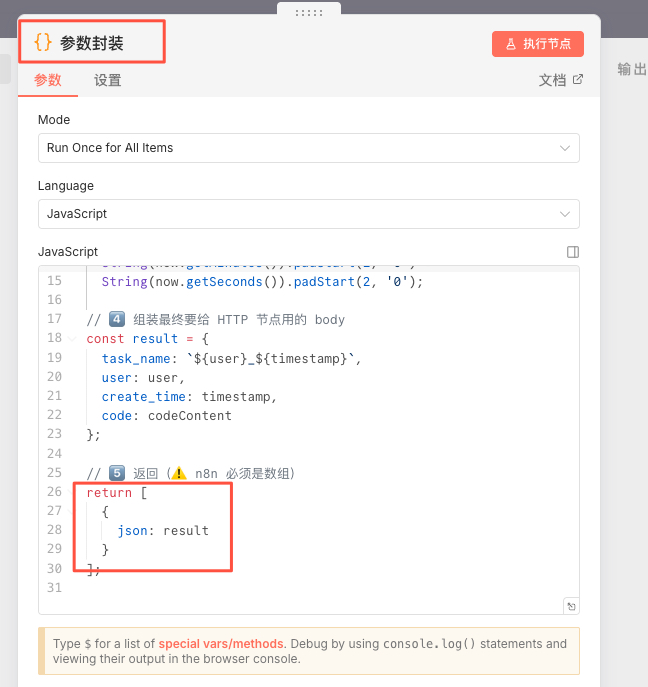
- 先包一层 JSON,再传字符串,我现在一般在前面加个code节点,处理好所有需要的参数,然后在下一个节点中直接使用{{ $json }}传递所有参数即可
- 日志只作为字段值存在
- 永远不要直接”裸插”进 JSON 模板

发布者:Ai探索者,转载请注明出处:https://javaforall.net/246718.html原文链接:https://javaforall.net


