


出品 | CSDN(ID:CSDNnews)
时隔四个月,埃隆·马斯克创立的 xAI 正式带来了 Grok 4 的升级版——Grok 4.1,此次发布共有两款型号的模型,分别为 Grok 4.1 和 Grok 4.1 Thinking。
目前,两者均向所有用户免费开放,可以通过 grok.com、X 以及 iOS 和 Android 应用使用。付费用户则能获得更高的使用额度。

全新升级的 Grok 4.1
根据 xAI 的说法,Grok 4.1 为 Grok 在真实场景中的可用性带来了显著提升。官方称,这一版本在创造力、情绪理解以及协作互动方面表现尤为突出。
与此前的模型相比,Grok 4.1 更善于捕捉细微意图,对话更自然、有吸引力,也展现出更加一致的人格特征。
为了实现这些能力增强,xAI 继续沿用了支撑 Grok 4 的大规模强化学习基础设施,并进一步将其用于优化模型的风格、人格和对齐性。由于这些目标难以通过可验证的方式直接衡量,xAI 开发了新的训练方法,让前沿的智能体推理模型作为奖励模型,能够自动化且大规模地评估与改进模型回复。
在上线方式上,xAI 先是于 2025 年 11 月 1 日至 14 日 进行了为期两周的静默灰度发布,将早期版本的 Grok 4.1 逐步推送到 grok.com、X 以及移动 App 的真实流量中,并在此期间持续进行盲测式的成对比较评估。
评测结果显示,Grok 4.1 相比此前的生产版本优势明显:
在盲测对比中,Grok 4.1 获得了 64.78% 的偏好率。
Grok 教程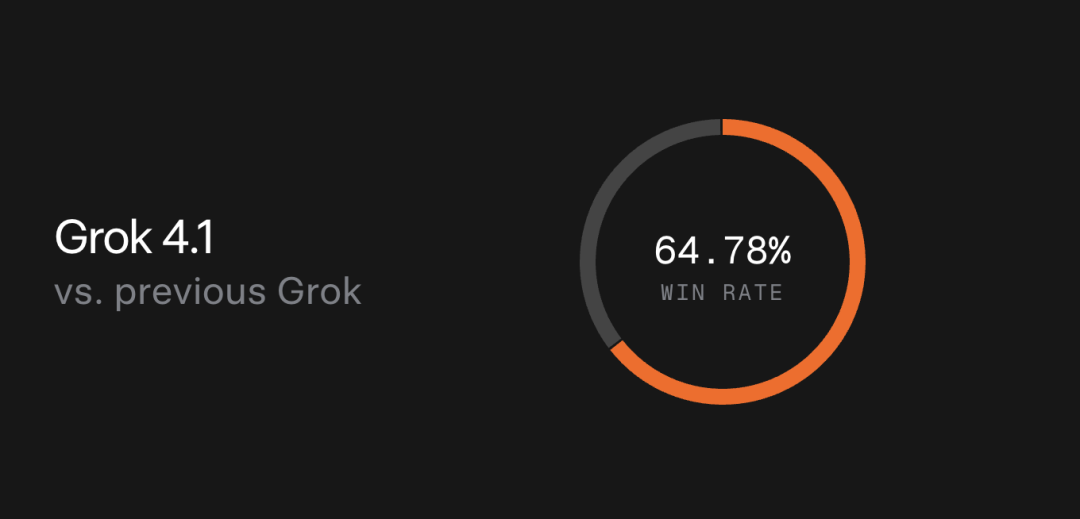

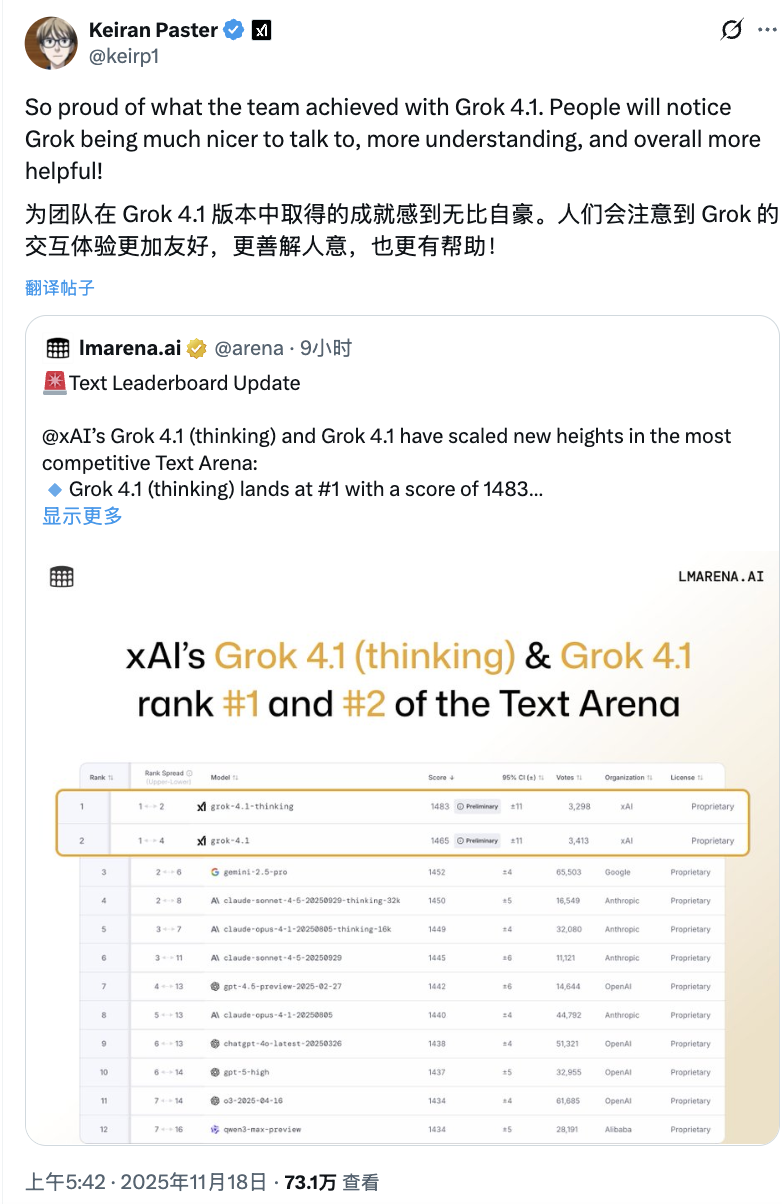
登顶 LMArena、位居各大榜单前列的 Grok 4.1
接下来,从具体的能力上来看。
通用能力
在 LMArena 的 Text Arena 排行榜上,Grok 4.1 Thinking(代号:quasarflux) 以 1483 Elo 的成绩位列总榜第一,比排名最高的非 xAI 模型 Gemini 2.5 Pro 高出 31 分,领先优势十分明显。
LMArena 的 Text Arena 是一个开源工具,允许用户通过并排、盲测和随机测试来比较不同的大型语言模型 (LLM)。
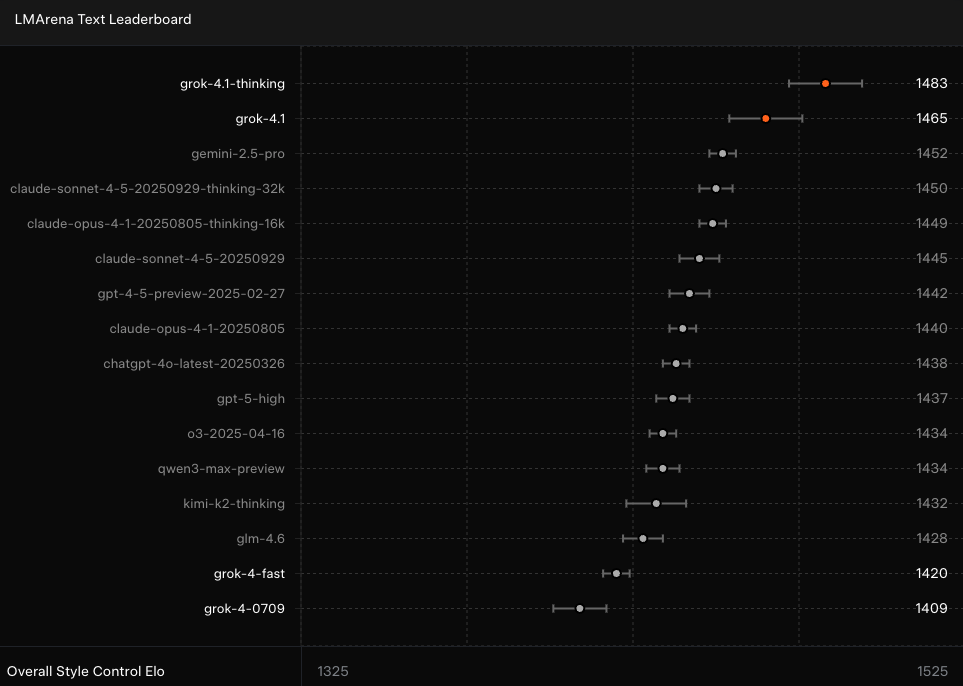
而 Grok 4.1 的非推理模式(代号:tensor) 不使用 thinking tokens,可直接给出即时回复,在排行榜上以 1465 Elo 排名第二。值得注意的是,这个“非推理模式”的 Grok 4.1 的成绩,甚至超过所有其他模型的“完整推理版本”。
相比之下,上一代 Grok 4 的总排名仅为第 33 位,与 4.1 的表现差距明显。
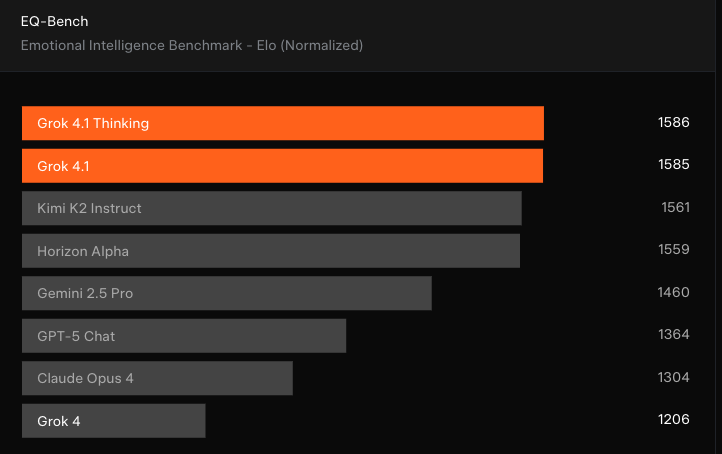
情商
为了评估模型在“人格风格”和“人际互动能力”方面的进步,xAI 使用了 EQ-Bench v3 对 Grok 4.1 进行测试。
EQ-Bench 是一个由大模型担任裁判的测试,主要衡量模型的主动情绪智力,包括理解力、洞察力、共情能力以及人际沟通技巧。测试集包含 45 个高难度角色扮演情景,大多数由三轮预设对话构成。
评测方法一方面通过固定评分标准检查模型回答质量,另一方面也会进行成对对比,最终得出每个模型的归一化 Elo 分数。
xAI 给出的分数来自官方基准测试仓库的运行结果,采用默认的采样参数、指定裁判模型 Claude Sonnet 3.7,且未添加系统提示词,以符合测试规范。
结果显示,Grok 4.1 Thinking 和 Grok 4.1 在 EQ-Bench 测试中名列第一、二名,这意味着该模型能够以更自然、更富同理心、更人性化的方式做出回应。对于用户而言,这意味着对话更容易理解,也更贴近生活。
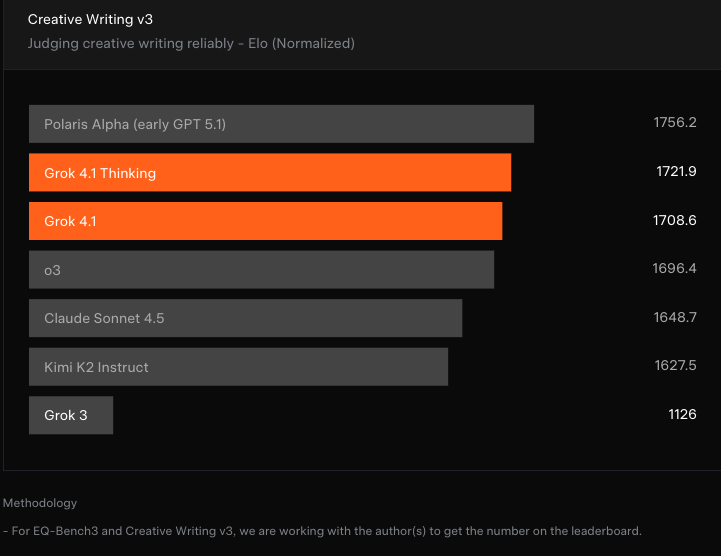
创意写作
xAI 在 Creative Writing v3 基准上测试了 Grok 4.1 系列模型的表现。该基准要求模型针对 32 个不同的写作提示生成回答,并进行 3 轮迭代。
与 EQ-Bench 类似,最终得分由两部分组成:依据评分标准(rubrics)给出的质量分,以及通过模型对战方式计算出的归一化 Elo 分数。
Grok 4.1 Thinking 以 1721.9 的得分排名第二。
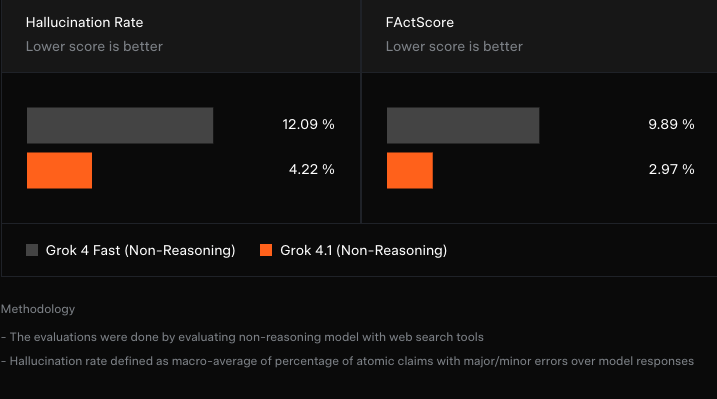
减少幻觉
快速(非推理)模型虽然能利用搜索工具迅速给出答案,但由于推理深度有限、工具调用次数受限,容易出现事实性错误。
在 Grok 4.1 的后训练阶段,xAI 透露他们重点优化了信息查询类提示的事实性幻觉问题。实际观测显示,对于生产环境中抽样的此类提示,幻觉率有了显著下降。
评估方法上,该团队在来自生产流量的分层抽样真实信息查询中测试了幻觉率,同时还使用了 FActScore 公共基准进行验证。FActScore 包含 500 个关于个人传记的问题,用于检验模型的事实准确性。
xAI 表示,与旧版本相比,Grok 4.1 将这个问题减少了近三倍。这使得它在人们询问事实、新闻或解释时更加可靠。

大模型竞争加剧
总体来看,Grok 4.1 是一次稳步升级,幻觉减少、荣登全球 AI 排行榜榜首,竞争力有所提升。

不过,从年度最佳模型的角度来看,不少外媒认为,Grok 4.1 或许还不是今年的巅峰。Google 正准备推出下一代旗舰 Gemini 3.0,外界普遍预计它将成为今年最强大的模型之一。可以预见的是,接下来一段时间,各家旗舰模型或将上演年度巅峰对决。
参考:https://x.ai/news/grok-4-1
推荐阅读:
与C++之父面对面、共庆四十周年!直击AI算力、系统软件、研发智能化:2025全球C++及系统软件技术大会核心专题揭晓
GPT-5.1与文心5.0同日升级!国产原生全模态模型很能打
本次大会共设立现代 C++ 最佳实践、架构与设计演化、软件质量建设、安全与可靠、研发效能、大模型驱动的软件开发、AI 算力与优化、异构计算、高性能与低时延、并发与并行、系统级软件、嵌入式系统十二大主题,共同构建了一个全面而立体的知识体系,确保每一位参会者——无论是语言爱好者、系统架构师、性能优化工程师,还是技术管理者——都能在这里找到自己的坐标,收获深刻的洞见与启发。详情参考官网:https://cpp-summit.org/

发布者:Ai探索者,转载请注明出处:https://javaforall.net/247115.html原文链接:https://javaforall.net


