
前两篇文章已经分别把几个关键环节打通:
- 💻 环境与模型:在 Windows WSL2 里部署好 OpenClaw,把 MiniMax 配置成默认大脑,并通过 Gateway 和飞书通道跑通闭环。(基于 Windows WSL2 + MiniMax 模型的 OpenClaw 安装使用(保姆级教程))
- 🧩 Skills 全景:从 ClawHub 里挑了一批常用技能,按下载量、场景给出优先级推荐,顺带演示了以
github为例的一整套安装与调用流程。(OpenClaw Skills 实战:常用技能推荐与安装示例)
- 为什么在 OpenClaw 里需要 Skills,而不仅仅是“模型 + 网关”;
- Skills 对 OpenClaw 的长期价值,尤其是对稳定性与可维护性的影响;
- AI 智能体怎样借助这样的 Skill,在日常使用中逐步形成“自我完善”的能力。
在这个前提下,先从一个在实际使用中非常常见的问题说起:
怎么让 AI 智能体
真正记住被纠正过的习惯,别总是“一次次重犯同样的错误”?
围绕这一点,本文选取了 ClawHub 上由 Iván Davila 提供的技能 Self-Improving Agent(Proactive Self-Reflection) 作为案例。在 ClawHub 与 LLMBase 的介绍里,这个技能的下载量已经稳定排在前列(可参考 ClawHub 技能页 与 LLMBase 介绍)。


很多人用 AI 智能体时,都会遇到类似体验:
- 明明前几轮已经说明“变量名不要随便重命名”,结果下一次改代码时又给全部变量换了一遍名字。
- 文案风格已经强调“少一点夸张语气”,写着写着又开始加一堆“颠覆”“震撼”之类的词。
- 项目已经统一好目录结构和注释规范,换一个任务又得从头解释一遍。
一两次还好,频繁重复说明之后,很难不怀疑:
这些纠正到底有没有被“学进去”,还是每一轮对话都在重新开始?
Self-Improving Agent 的设计目标,就是让 OpenClaw 里的 AI 智能体具备四类核心能力:
- 🪞 自我反思(Self-Reflection):在完成一段工作后,主动回顾“哪些地方做得不好”“有哪些改进空间”。
- 🧪 自我批评(Self-Criticism):对自己的输出进行有针对性的“挑错”,避免盲目自信。
- 📚 自我学习(Self-Learning):把重复出现的纠正与偏好抽象成“模式”,下次遇到类似问题时提前避坑。
- 🧠 自组织记忆(Self-Organizing Memory):把这些模式整理成多层记忆结构,既有随时可用的“HOT 记忆”,也有按项目 / 域划分的“WARM 记忆”,还有长期归档的“COLD 记忆”。
简单说,这个 Skill 做的是一件“听起来理所应当,但实际上很多模型都没做好”的事情:
在不改动基础大模型的前提下,让 AI 智能体渐渐形成一套
有条理、有选择性的长期习惯。
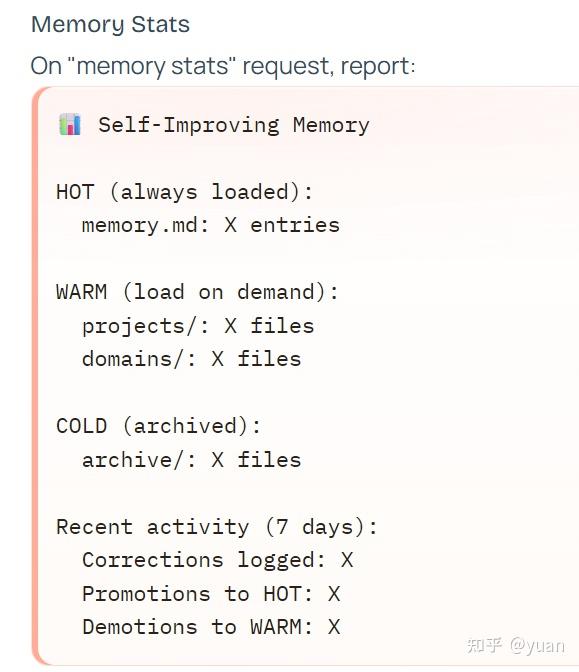
根据 LLMBase 等资料介绍(可参考 Self-Improving Agent 说明),安装好这个 Skill 后,本地会在 ~/self-improving/ 下维护一套分层记忆结构,大致如下:
- 🔥 HOT 记忆(memory.md)
- 文件路径:
~/self-improving/memory.md - 内容限制:不超过约 100 行。
- 特点:每次调用 Self-Improving Agent 时都会被加载,是 AI 智能体“时刻在脑子里”的那部分习惯。
- 🌡 WARM 存储(项目 / 领域记忆)
- 典型目录:
~/self-improving/projects/:按项目维度存放经验(例如某个代码仓库、某个自动化流程)。~/self-improving/domains/:按领域维度存放经验(例如“技术写作”“ToC 产品文案”“Python 脚本”等)。- 特点:不会每一次都全量加载,而是按需要与上下文选取,避免 context 被占满。
- ❄️ COLD 存储(archive/)
- 目录:
~/self-improving/archive/ - 用途:把很久没再触发、或优先级已经降低的模式“降级”到冷存储。
- 好处:既不浪费宝贵的 HOT 记忆空间,又能在必要时回溯历史。
- 📝 纠错日志(corrections.md)
- 文件路径:
~/self-improving/corrections.md - 作用:只保留最近一批“被用户纠正”的场景,一般约 50 条左右。
- 内容:每条包括“触发句子”“原本行为”“用户希望的行为”“是否已经成功应用过几次”等信息。
整体可以理解成一套“多级缓存”:
- HOT 像 CPU L1 Cache,始终保持小而精;
- WARM 像更大的 L2/L3 Cache,按任务类型做分层;
- COLD 则像长期归档的仓库,必要时再从历史中“捞回来”。
在具体实现上,Self-Improving Agent 还约定了一组比较清晰的“Core Rules”,用来规范记忆写入、存储位置与行为边界,可以简单理解为这几个方面:
- 🧠 只从“明确的纠正与自我反思”中学习
- 只有在两类场景下才会记笔记:一是使用者明确指出“哪里不对、以后怎么做”;二是智能体自己在任务结束后做自我反思、发现可以改进的地方。
- 不会从沉默中“脑补偏好”,也不会因为单次偶然行为就当成长期规则;同一类教训至少出现 3 次,才会尝试把它固化为规则,并在必要时向使用者确认。
- 🗂 分层存储与自动升降级
- HOT(memory.md):不超过 100 行,始终加载,放的是最核心、最常用的偏好。
- WARM(projects/、domains/):每个文件不超过约 200 行,按项目和领域拆分,只在上下文匹配时加载。
- COLD(archive/):没有固定大小限制,用来存放长期不再触发但可能需要追溯的历史模式。
- 模式在 7 天内成功应用 3 次,可以从 WARM 提升到 HOT;长期(例如 30 天、90 天)未再触发的模式,会从 HOT 降到 WARM,再归档到 COLD,但不会直接被删除。
- 🧾 按命名空间隔离偏好
- 项目相关的习惯写在
projects/{name}.md里,只在对应项目生效; - 更通用的写作 / 编码风格,放在
domains/下的领域文件里; - 全局偏好则保存在
memory.md中。 - 实际使用时遵循“全局 → 领域 → 项目”的继承顺序,如果不同层级之间出现冲突,优先采用“越具体的越优先”,同一层级里则以后写入的为准;确实无法自动判断时,会选择询问而不是自作主张。
- 🧹 在不丢偏好的前提下做“压缩”
- 当某个文件接近大小上限时,会尝试把语义相近的多条纠正合并成一条更抽象的规则;
- 对明显长期不用的模式,优先归档到 COLD,而不是直接删除;
- 对特别啰嗦的记录,会进行适度摘要,但已经确认的偏好本身不会丢失。
- 🔍 保持可追溯与可解释
- 当根据某条记忆采取行动时,会在内部标明来源,例如“来自 projects/foo.md 的第 N 行”,方便后续排查;
- 支持按周期(例如每周)生成一份“学习摘要”,列出最近新增、降级、归档的模式,也支持在需要时导出整个
~/self-improving/目录作为一份 ZIP 归档。 - 🔐 边界清晰:只管理偏好,不越权访问
- 只会在
~/self-improving/目录下读写自己的记忆文件; - 不访问日历、邮箱、联系人,也不主动发起网络请求;
- 不会擅自修改自己的
SKILL.md文档,更不会把敏感信息(例如账号口令、健康数据、三方平台密钥)写入记忆。
Self-Improving Agent 的一个有趣之处在于:
并不要求使用者手动写一堆规则文件,而是自动监听“被纠正”的场景,再把这些场景抽象成可重用的模式。
在英文世界里,官方示例会重点关注一些典型触发短语,例如:
- “Why do you keep …”
- “Stop doing X”
- “I told you before …”
对应到中文场景,就非常容易联想到日常会说出的几类话:
-
openclaw skills 教程
- “别再帮忙重命名变量了,就按原来的名字来。”
- “以后写文案不要用‘震撼’‘颠覆’这种词。”
- “前面已经说过一遍,这个项目统一用蛇形命名,不要再混着来。”
Skill 的逻辑大致是:
- 🔎 当检测到这些“明显是在纠正行为”的语气时,就会把本次对话片段记录到
corrections.md; - 🧩 经过几次类似纠正后,会尝试提炼出更抽象的“模式”:例如“在技术文章里减少夸张形容词”“变量命名遵守某约定”等;
- 📌 当某个模式被成功应用了 3 次以上,就有机会被“晋升”到 HOT 记忆的
memory.md中,成为长期习惯。
从使用体验角度看,关键不在于记住某一句话,而在于逐渐形成一套能跨任务迁移的偏好体系。
前提条件与前两篇文章保持一致:
- ✅ 已在 WSL2 / Linux 环境中装好 OpenClaw,
openclaw --version正常; - ✅ MiniMax(或其他主力模型)已配置成默认模型;
- ✅ Gateway 可以通过
openclaw gateway启动并保持运行; - ✅
npm可用,最好已配置国内镜像源。
按照 ClawHub 技能页 与相关文档的说明,这个 Skill 在 ClawHub 上的 slug 为 self-improving,可以直接使用 ClawHub 安装。
在 WSL2 的 bash 中执行:
# 可选:提前确保 npm 使用国内镜像 npm config set registry https://registry.npmmirror.com # 使用 npx 安装 self-improving npx clawhub@latest install self-improving 如果平时已经全局安装过 ClawHub,也可以使用更短的命令:
clawhub install self-improving 安装完成后,可以用下面的命令查看是否出现在列表中:
npx clawhub@latest list 在输出中能看到 self-improving,说明已经就绪。
Self-Improving Agent 的一个优点是:
不依赖外部付费 API Key,主要使用本地文件系统与已有的大模型能力。
也就是说,只要 OpenClaw 自己的主模型已经配置好(例如 MiniMax),额外部分基本不需要再去申请新平台的密钥。
安装完成后,OpenClaw 一般会在 ~/.openclaw/openclaw.json 的 skills.entries 下新增一个与 self-improving 相关的配置块,主要是一些开关、路径与阈值(例如 HOT 记忆最大行数、触发次数等),具体字段名称可参考该 Skill 自带的 SKILL.md。
普通使用场景中,即便不手动修改这些配置,默认行为也足以应对大多数需求。
为了更直观地感受这个 Skill 的效果,可以从一个非常常见、又经常令人头疼的场景入手:
在一个长期维护的代码仓库里,希望 AI 智能体只补充逻辑,不要随意改动已有变量名和函数签名。
一个相对自然的操作过程大致如下(以某个 Workspace 为例):
- 🧪 第一次协作
- 让 OpenClaw 智能体帮忙重构一段函数;
- 结果发现它把原本简洁清晰的变量名全部换掉了。
- 这时可以明确地说出偏好,例如:
- “以后在这个项目里,重构时不要重命名已有变量,除非变量名明显有歧义。”
- 🔁 第二、三次纠正
- 当类似情况再次出现时,不要只说“这样不对”,而是重复这个“规则式”的纠正语句;
- Self-Improving Agent 会把这些纠正记录在
corrections.md中,并逐步抽象成模式。 - ✅ 多次成功应用后
- 一旦模型在后续任务中多次成功遵守这一约定,这条“不要乱改变量名”的习惯就有很大概率进入 HOT 记忆;
- 之后在同一 Workspace / 项目背景下,再次请求重构,变量名被“无故改写”的概率会明显降低。
这个过程既不需要手动编辑 memory.md,也不要求记住一大串配置键值,只要在日常对话中保持纠正语气的稳定与具体,Self-Improving Agent 就会在后台慢慢帮忙“捋顺”这些偏好。
Self-Improving Agent 虽然能自动整理偏好,但要真正发挥威力,日常使用中有几个小建议值得注意:
- 🎯 纠正要具体,而不是情绪化
- 相比简单地说“这不对”,更有效的做法是给出可抽象的规则,例如“在技术类文章里尽量避免夸张形容词,多用客观描述”。
- 🔁 对同一类偏好保持稳定表述
- 如果每次纠正都换一种说法,模型更难从中提炼模式;
- 适当复用类似句式,反而有利于 Self-Improving Agent 把它识别为同一类“习惯”。
- 🧱 为不同项目和领域提供清晰上下文
- 例如给不同 Workspace 起有区分度的名字,或在项目开头就声明“这是某个仓库的专用习惯”;
- 有助于 Skill 把记忆正确放入
projects/或domains/里的合适位置。 - 🚦 定期查看与整理记忆文件(可选)
- 对于特别在意“习惯可控性”的场景,可以偶尔检查
memory.md与corrections.md; - 如果发现有已经不适用的模式,完全可以手动编辑或归档,避免旧习惯影响新项目。
- 🔧 与 capability-evolver、gog 等“能力演化类”技能结合
- 前者负责“怎样把一段能力变得更强、更自动化”,
- Self-Improving Agent 则负责“在这个过程中,把被多次纠正的问题记录下来,后续尽量避免重复出现”。
- 📦 与 github、wacli 等开发协作类技能结合
- 在自动提 PR、批量改代码、调整脚本时,通过自我反思减少“思路正确但风格不统一”的情况;
- 例如持续记住某个仓库的提交信息格式、测试命令约定等。
- 📄 与 summarize、humanize-ai-text 等内容类技能结合
- 在频繁生成摘要和长文时,逐步形成更贴合团队口味的文风;
- 一些反复强调的写作偏好可以自然沉淀到 HOT 记忆中。
引入 Self-Improving Agent 之后,OpenClaw 里的 AI 智能体,不再只是一个“永远从零开始”的对话对象,而更像是一位可以长期共事、会记住被纠正过习惯的同事:
- 初期可能依然会犯一些重复错误,但只要通过明确、稳定的纠正语句指出问题,相关模式就会慢慢沉淀下来;
- 经过一段时间的磨合,智能体在特定项目和领域上的“风格与偏好”会越来越接近团队预期;
- 配合 ClawHub 生态中的其他 Skills,就能在写作、开发、运维等多个场景里,逐步搭建出一套“越用越懂事”的自动化体系。
在 OpenClaw 的整个使用旅程里,Self-Improving Agent 不一定是最显眼的那一个 Skill,也绝不是“非装不可”的必选项。
更合理的看法是:它提供了一套相对完整的“自我反思 + 记忆分层 + 纠错沉淀”的范例,既可以直接拿来用,也可以作为设计、评估其他 Skills(包括自研 Skills)的一个参考坐标。
至于是否安装、何时安装,完全可以根据当前项目复杂度、团队协作程度和资源投入来决定——关键是通过这个案例,看到 “Skills 能为 OpenClaw 带来的,不只是单点能力,而是一整条让 AI 智能体在特定场景下逐步完善自身行为的路径”。
欢迎关注我的公众号:数智脉动,后续介绍更多 OpenClaw 的相关内容。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/254714.html原文链接:https://javaforall.net


