
本专栏的第四弹,在实现了联网调用通义千问模型进行多轮对话,流式输出,以及结合LangChain实现自建知识库之后,开始准备考虑实现对大模型进行本地部署,网上找不到看着比较舒服的教程,本文对于部署大模型过程中比较重要的,环境搭建,模型下载等进行详细介绍,如果您没有研究需求只有使用需求,请直接安装环境-下载模型-运行代码,由于这部分内容实在太多,所以可能还是需要一些相关的基础才能完全读懂本篇文字,如果您之前稍微研究过大语言模型的本地部署我相信这篇文章一定能解决您的问题,如果有什么我写的不清楚的地方,非常欢迎各位给我留言评论探讨,然后虽然我看好像其他相关的文章好像都收费,但是我还是决定免费,由于我是会员所以我有版权保护,所以不用太担心别人直接爬走,希望帮助到各位,如果可以您点个赞我会非常开心的。
第一弹 调用阿里通义千问大语言模型API-小白新手教程-python
第二弹 LangChain结合通义千问的自建知识库
第三弹 使用LangChain结合通义千问API基于自建知识库的多轮对话和流式输出
千问 Qwen 教程
首先需要下载通义千问的Qwen-7B-Chat的模型文件,其下载地址为阿里官方的大语言模型社区,模搭ModelScope,其中通义千问的Qwen-7B-Chat 的下载和相关介绍的地址为。
https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary


点击其中的模型文件,进入模型文件页面,之后点击右侧的下载模型
右侧会出现两个下载方式,第一个是用SDK也就是安装安装工具包下载,第二个是用git下载,这里还是推荐用第一种,但是实际使用的时候,还需要添加一个新的参数用来设置下载地址,否则就会下载到安装包的目录下
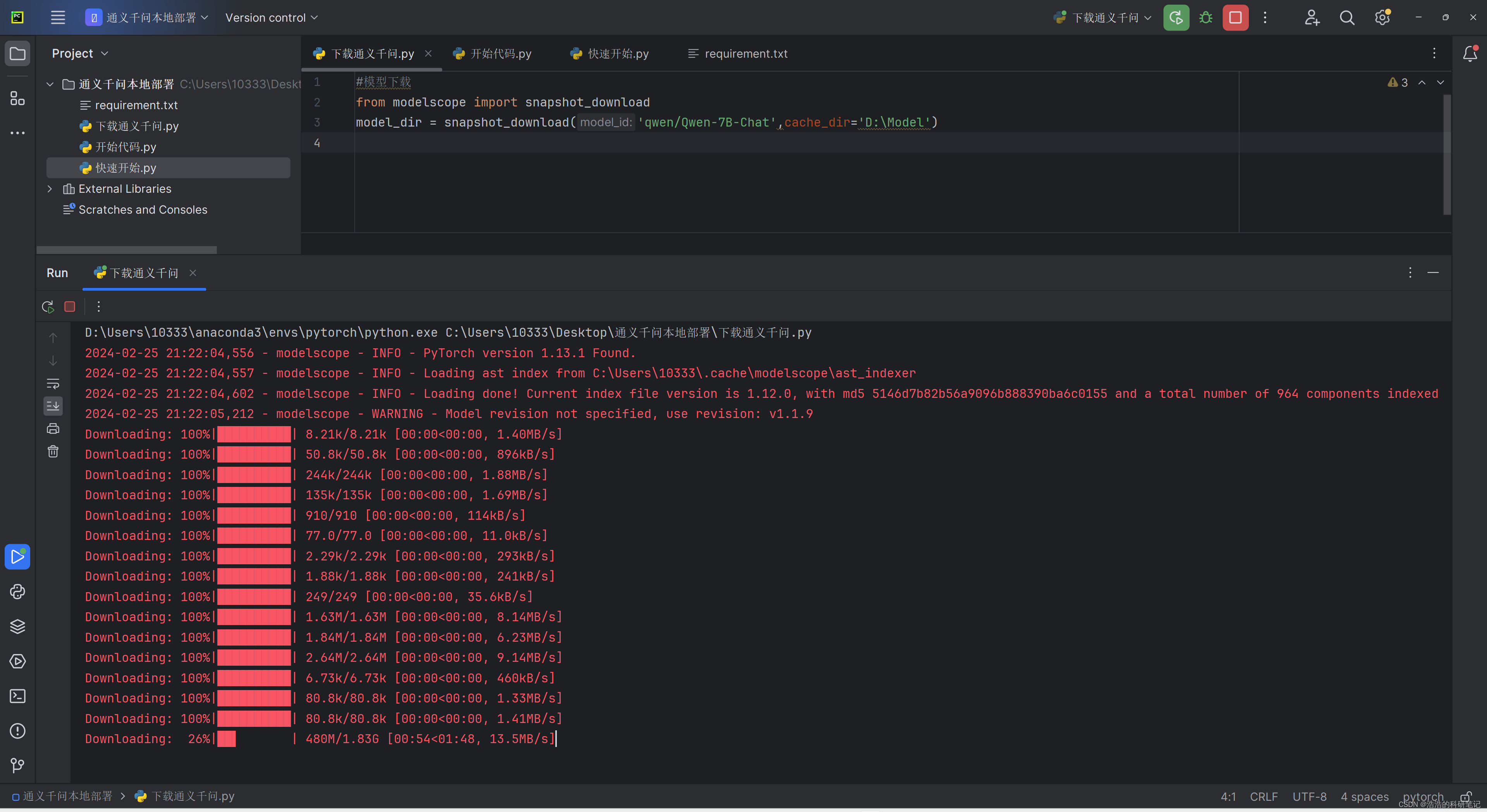
在安装好环境之后,之后运行下面的代码就可以下载到本地了,模型大小一共是14.4个G就是自己设置的模型下载的地址是是一个文件夹的目录
运行起来的下过如下,当运行到下载1个G以上的文件的时候会卡住一阵,才会开始下载,如果这里长时间没响应那就是网络条件不行了。
为了运行之后本地部署的Qwen-7B-Chat模型,我们需要根据要求在Anaconda中安装一个满足模型运行要求的虚拟环境,其官方的配置环境要求如下,本文配置的环境为使用GPU Pytorch的版本。官网的要求如下。

除了常规的Pytorch之外还需要进行以下两次安装安装modelscope可以用来下载模型,在下载的过程中有网络要求我用的宽带为100M的网线链接最后下了不到1个小时,如果网络不行在下载到大文件的时候会断开链接。
然后是官方说的运行Qwen-7B-需要安装的依赖。

具体安装过程根据不同的系统电脑各有各的微小差异,而且有时候充满了玄学,在这里我说一下我自己的配置,然后给大家参考。
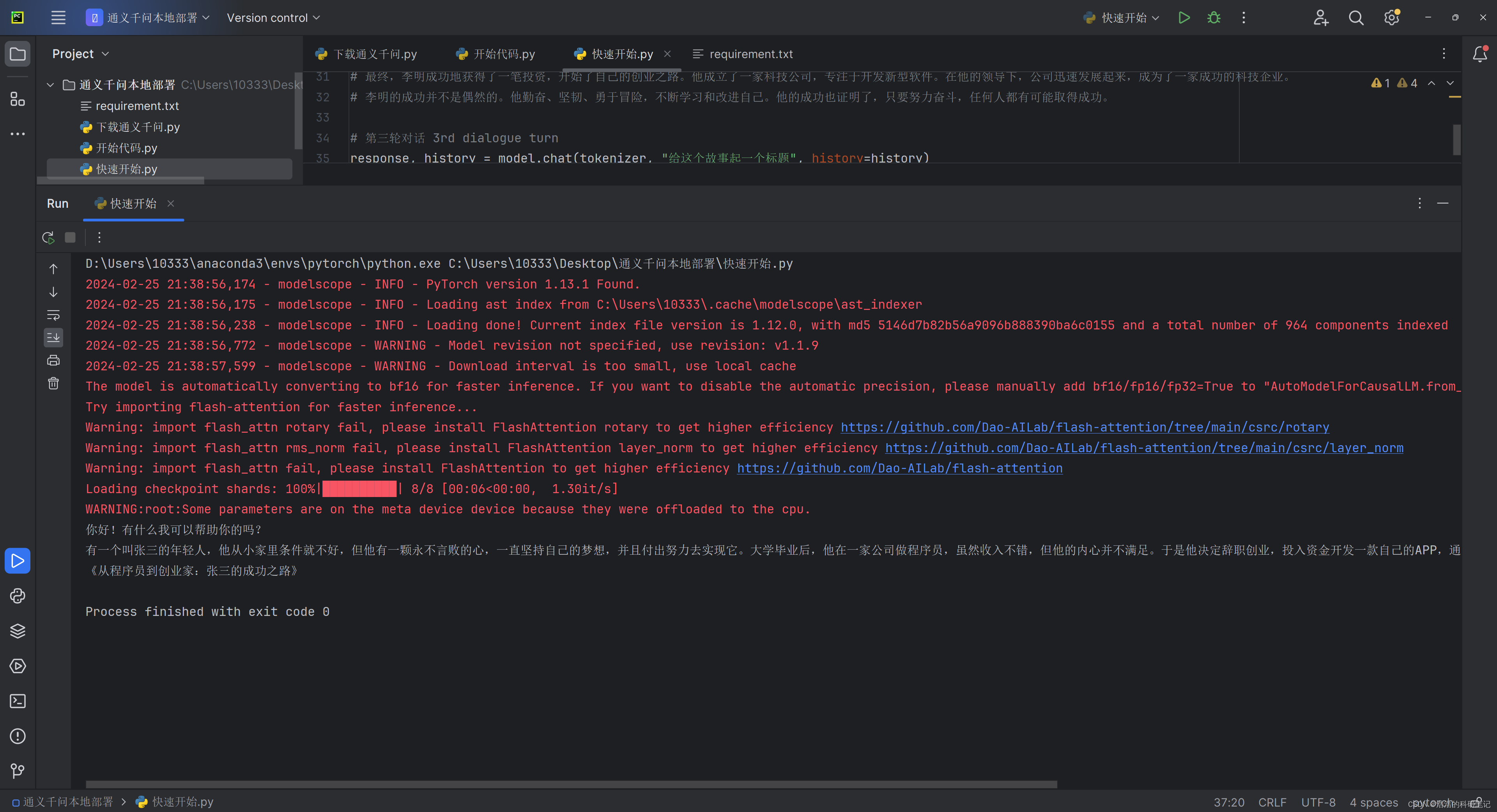
在安装好环境以及下载了模型文件之后,就可以运行官方的例程代码来观察对话效果,官方的快速开始代码如下,先给出官方代码之后我会精简然后介绍重要参数的作用
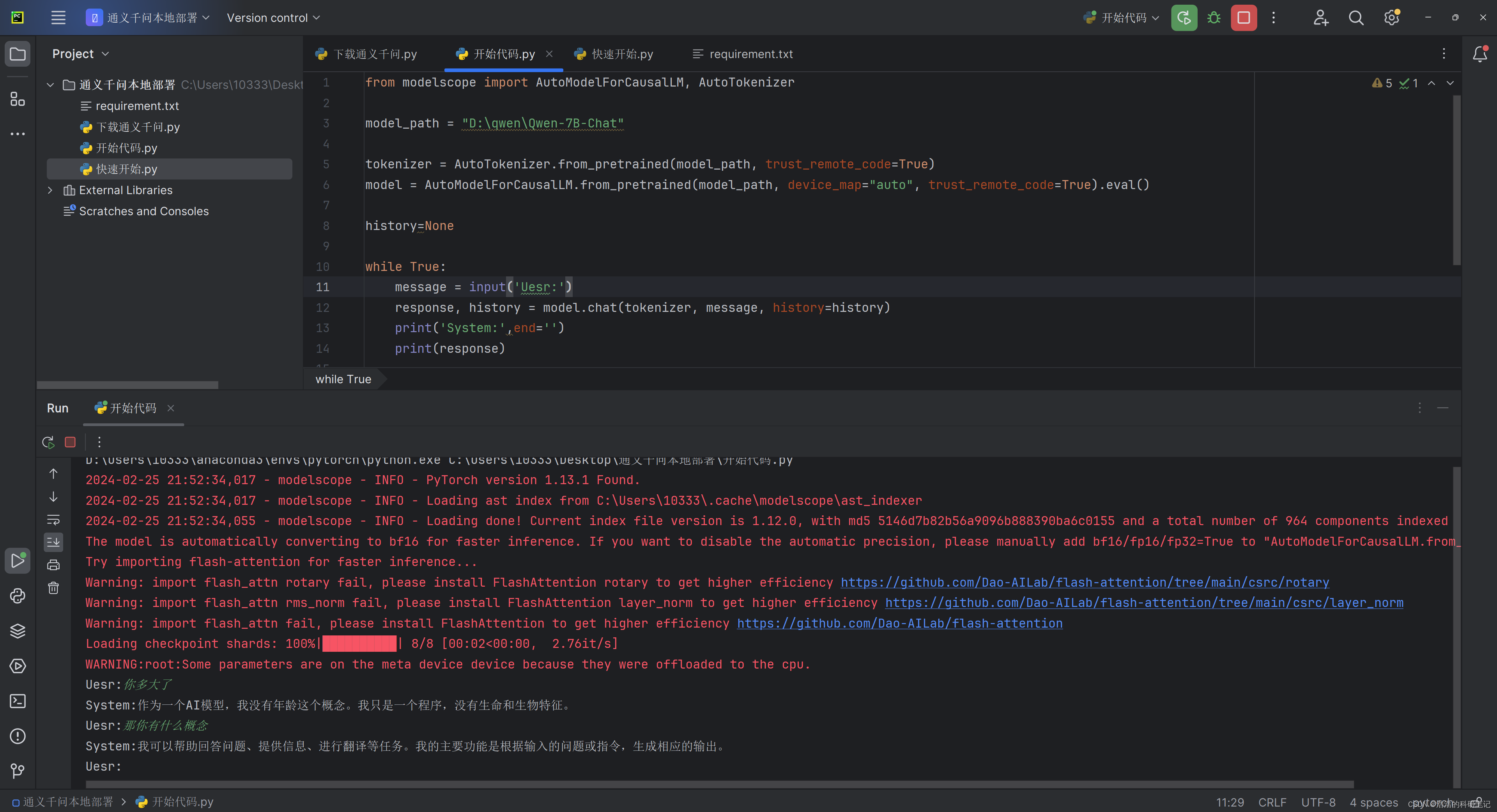
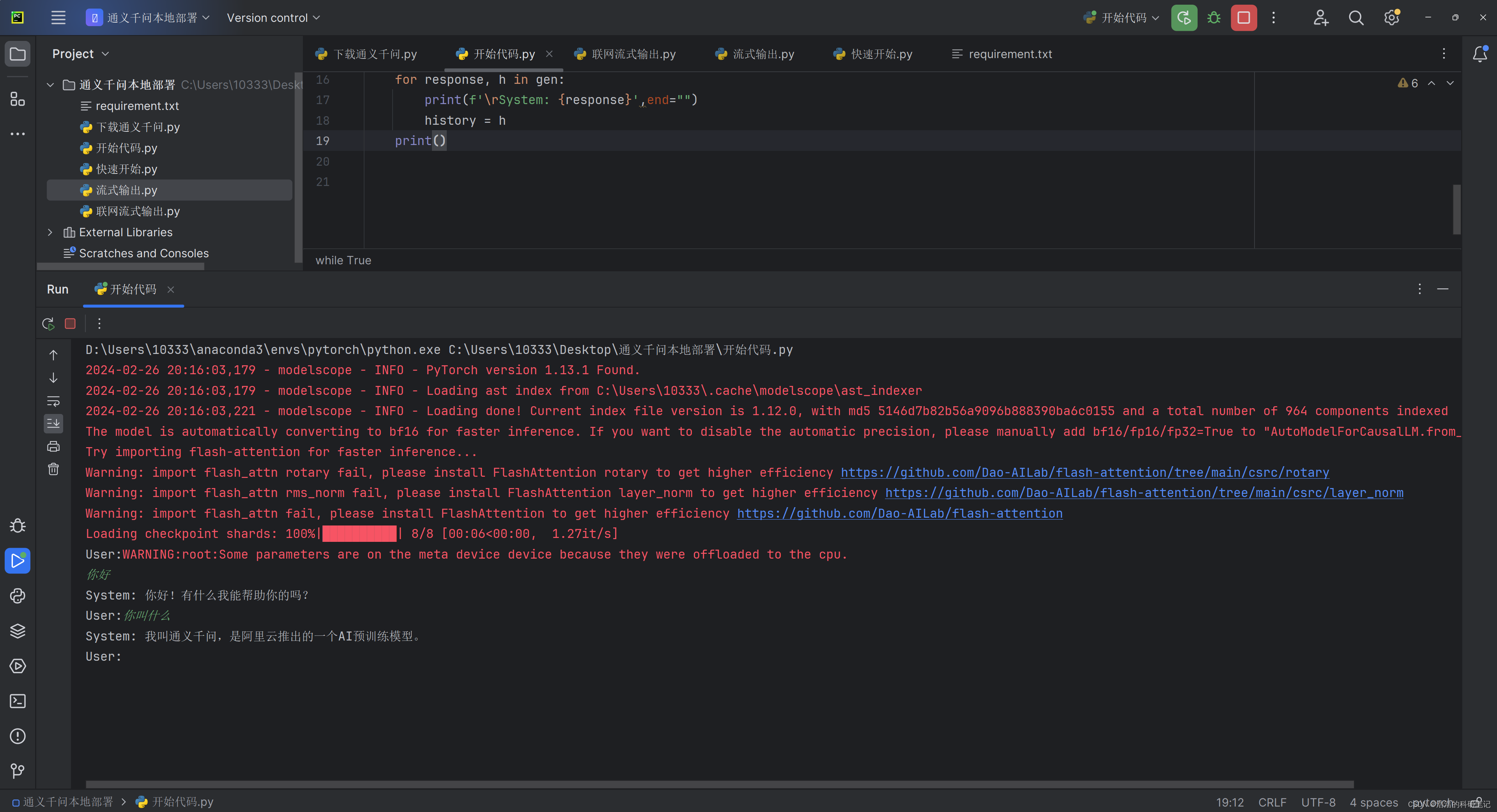
运行的结果如下,红色的是各种前置检查信息,我专门断网测试了一下输出的也是这些内容。
之后对代码进行精简,实现一个简单的多轮对话功能。精简之后的代码如下。其中的如果设置为则模型将会在cpu上运行,如果设置为如果为GPU版本的话将会在GPU上运行。关于非常容易关注到的,官方是这吗说的🤭说现在还没有概念的对应,所以无需纠结这块是啥东西。根据经验推测它应该是跟分词有关的一个东西。

- : 从modelscope库中导入两个类:和。这两个类分别用于加载预训练的因果语言模型(例如,GPT系列模型)和分词器。分词器用于文本的预处理,将文本转换为模型能理解的格式。
- : 定义模型文件存放的路径。这里假定你已经有了一个预训练模型,存储在指定的路径下。
- : 从给定的路径加载预训练的分词器。参数允许加载并执行远程代码,这对于加载自定义的分词器逻辑可能是必需的。
- : 类似地,从指定路径加载预训练的语言模型,并将模型设置为评估模式。。方法用于切换到模型的评估模式,这通常在预测时使用,以禁用训练时特有的行为,如。
- : 初始化变量。这个变量用于存储对话历史,使模型能够在生成回答时考虑到之前的上下文。
- : 开始一个无限循环,用于持续接收用户输入并生成回应。
- : 通过input函数接收用户的输入。
- : 调用模型的chat方法生成回应。这个方法接受分词器、用户的消息以及可选的历史记录作为输入,并返回模型的回应和更新后的历史记录。更新后的历史记录可以在下一次迭代中使用,以便模型能够参考之前的对话内容。
- 和: 首先打印,不换行,然后打印模型生成的回应。
运行结果如下:
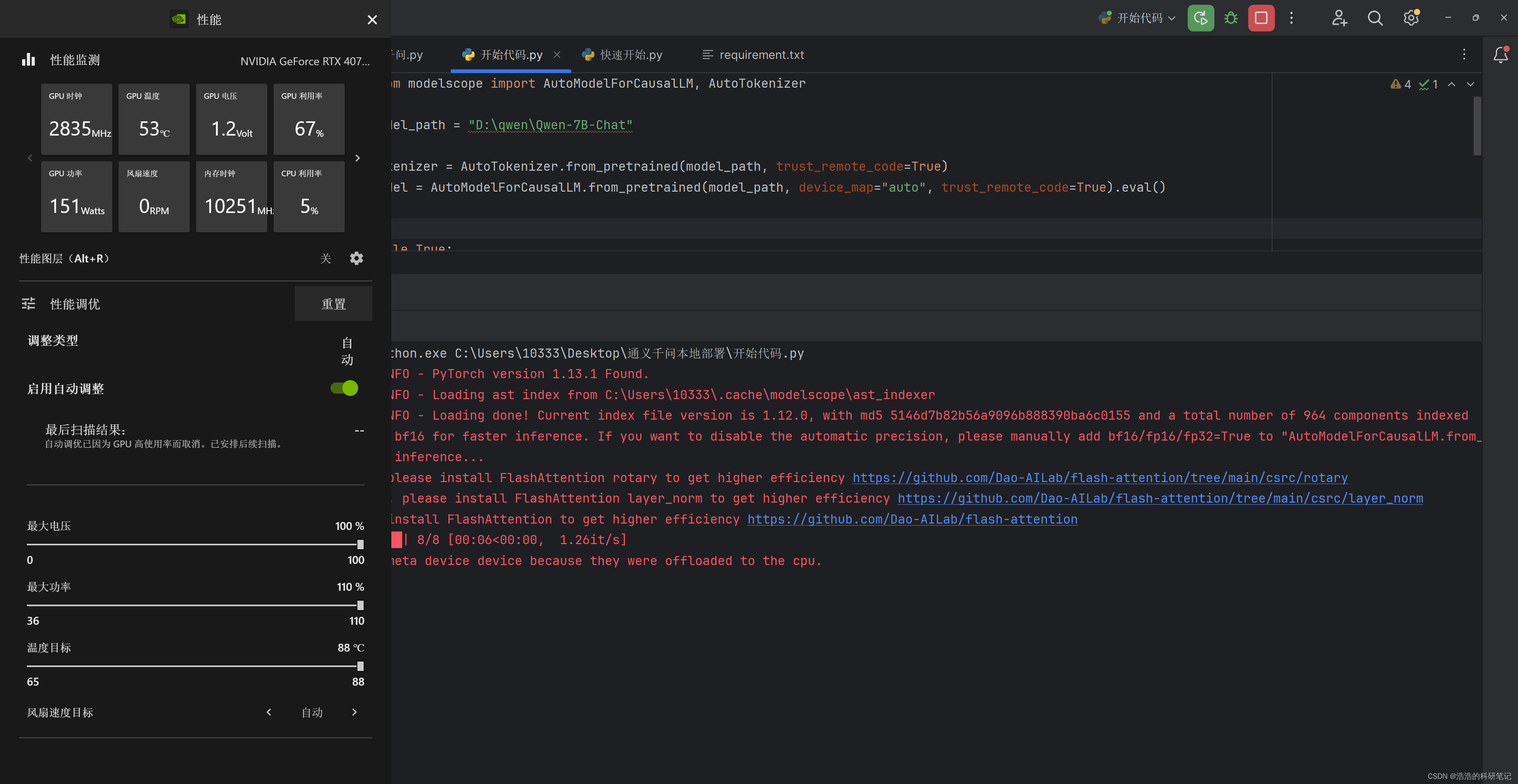
本设备在模型推理时的性能检测效果如下。
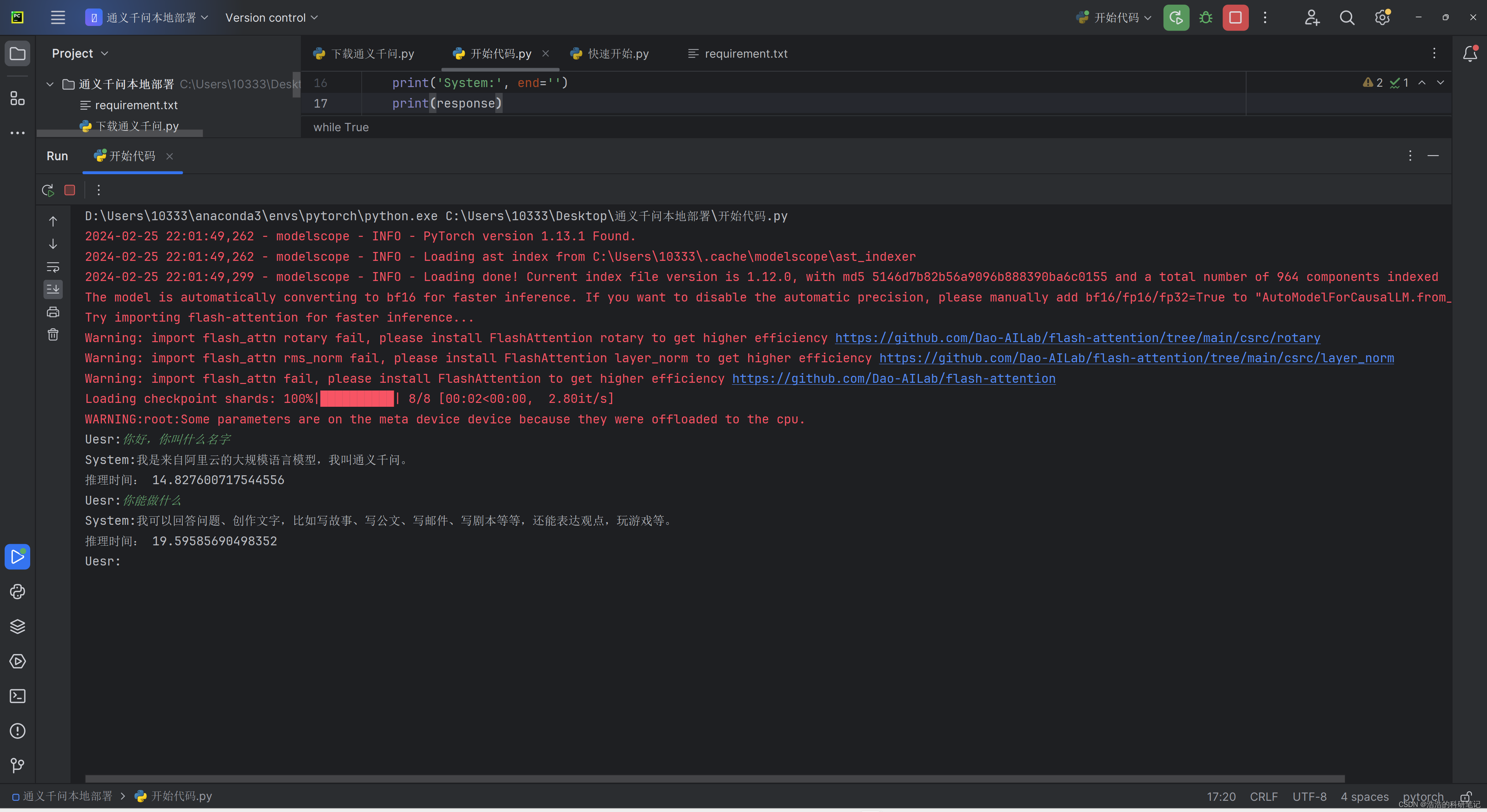
由于其生成的比较慢,我就加了一下每次推理运行的时间,其运行时间效果如图,我大概估计了一下,输出一个Token的推理时间大概为1S,在官方的快速开始的例程序中,所以等待的过程非常的难受。
在经历了非常不舒服的等待之后,决定尝试一下流式输出,然后这部分代码就非常的不好找了,我在进入了ModelScope的官方咨询群之后询问了半天,加上自己参悟最终实现了在Windows上使用本地部署的通义千问模型多轮对话的效果,那接下来直接开始。我会把这个过程以及采的坑详细说明,如果您是有相关基础的想直接使用的技术人员直接跳到最后的代码部分即可。
4.1 该部分实现过程和踩坑经验分享
首先,对于流式输出官方人员给我发的一个链接是这样的。

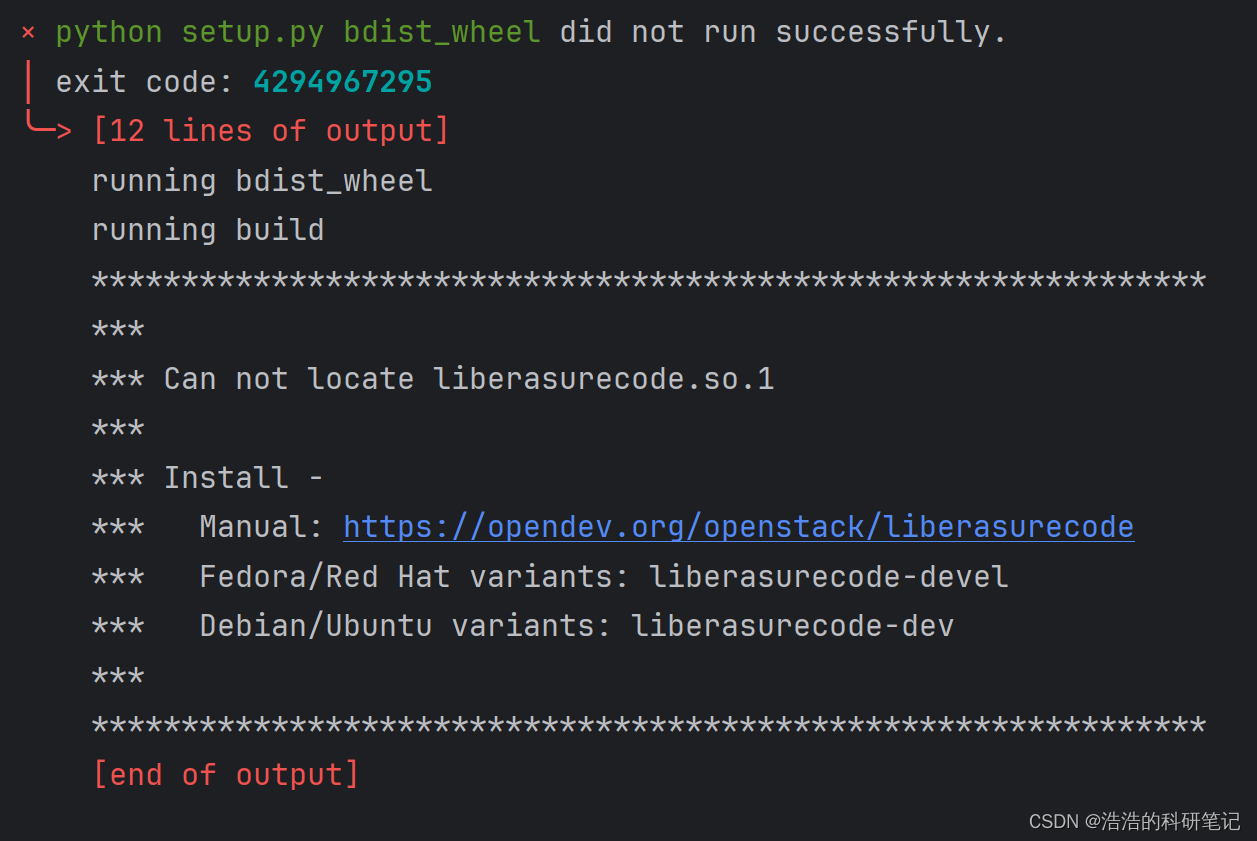
这里我直接把代码复制到下面,我们先不纠结里面的内容,这里用到了一个新的库,首先需要安装它,这里是一个坑
其安装命令为:
而并不是,如果你用的是安装会安装不上,会出现如下错误,提示你要取下载红帽和Ubtuntu版本的库,但是这是Liunx系统的库,所以安装不上,只有运行才能安装成功。
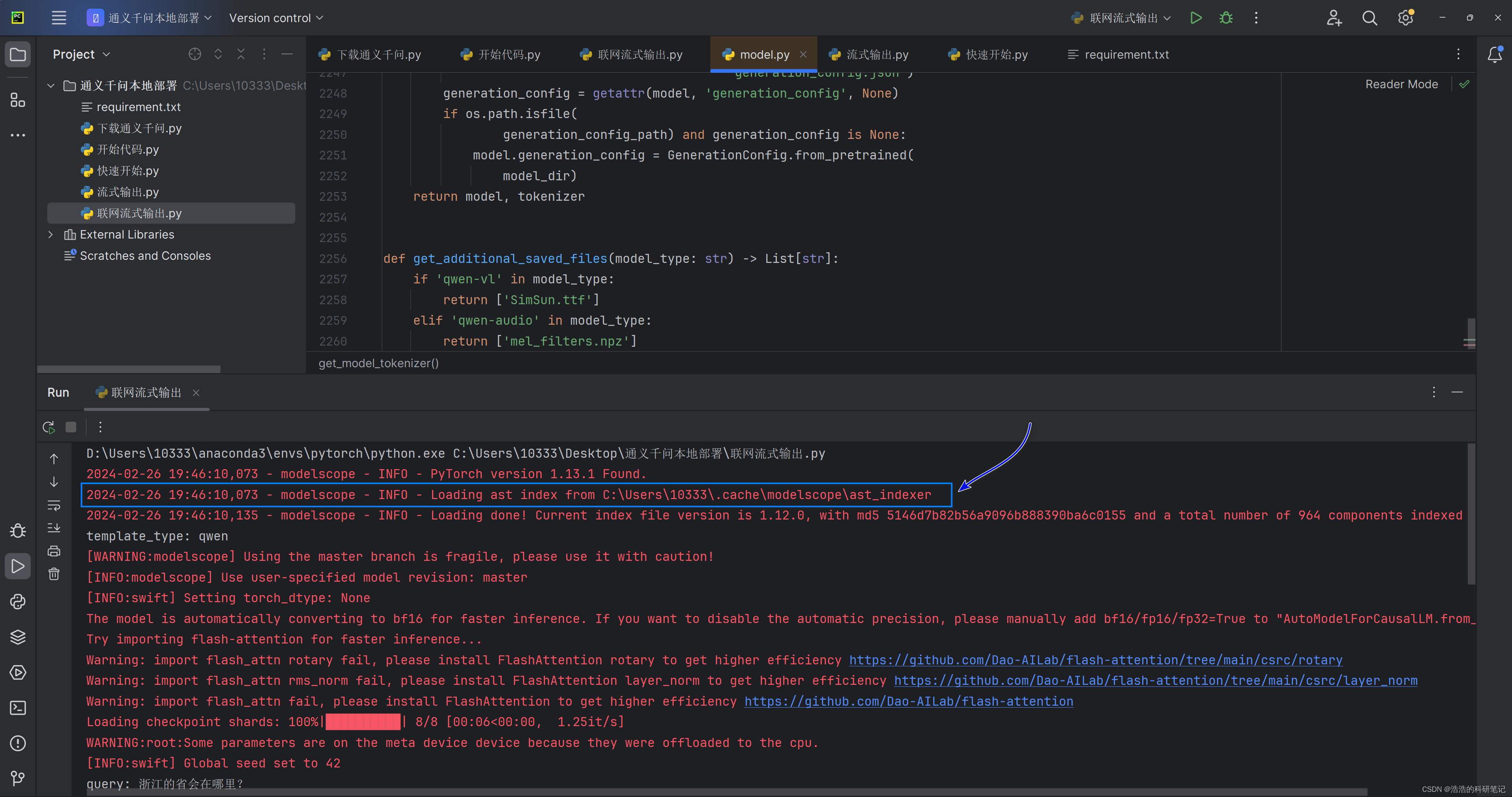
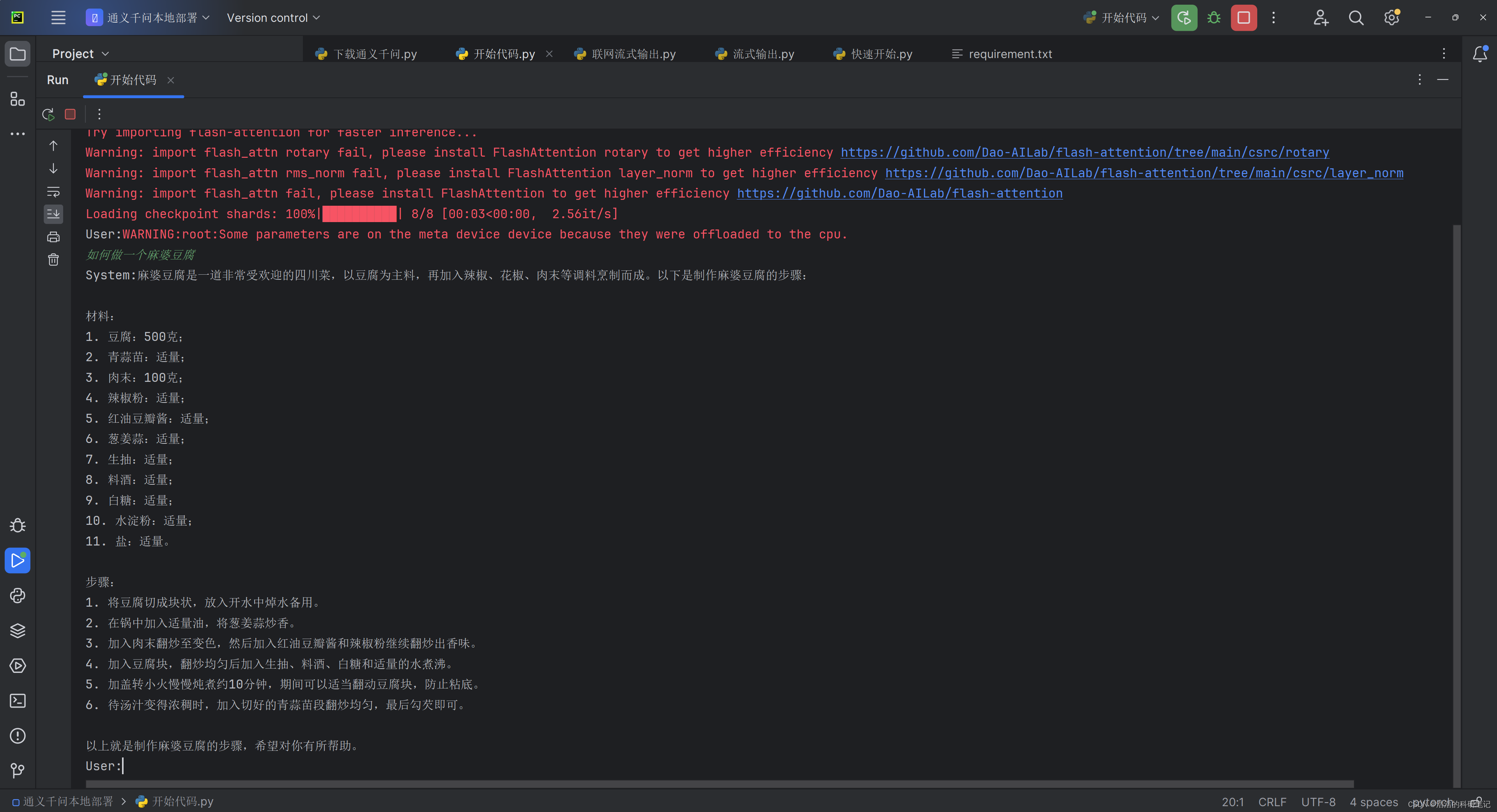
直接说这个代码的结论,首先这个代码是下载和推理一体的代码,当第一次运行的时候,会在指定路径下下载模型文件,第二次运行时检测到指定文件夹下的文件了之后,就会开始进入模型推理阶段,下面的运行输出是我的模型第二次之后运行的结果。
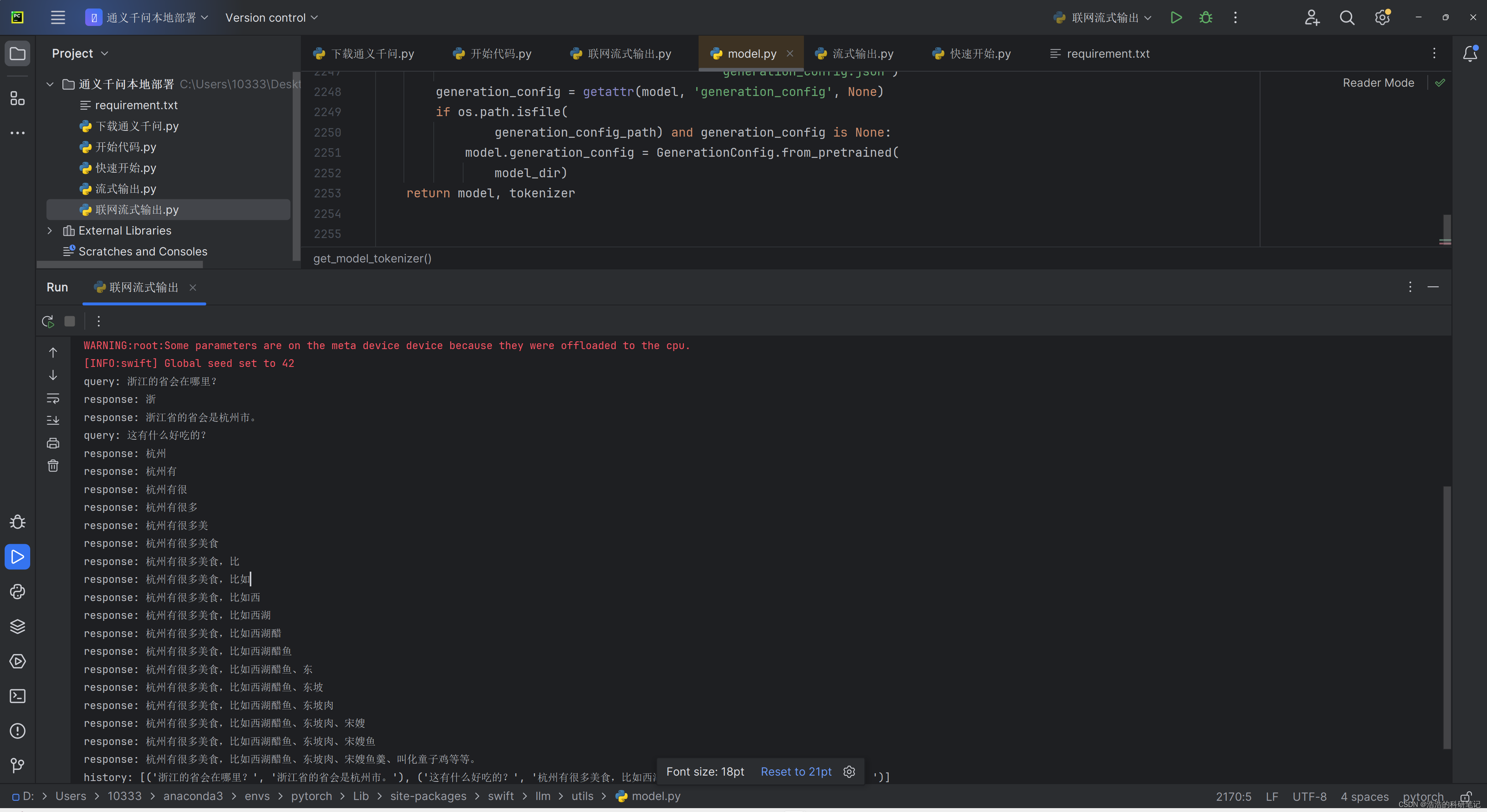
第二次运行之后对话输出部分的效果如下,之后我要对流式输出的结果进行改进,一个一个问题解决。
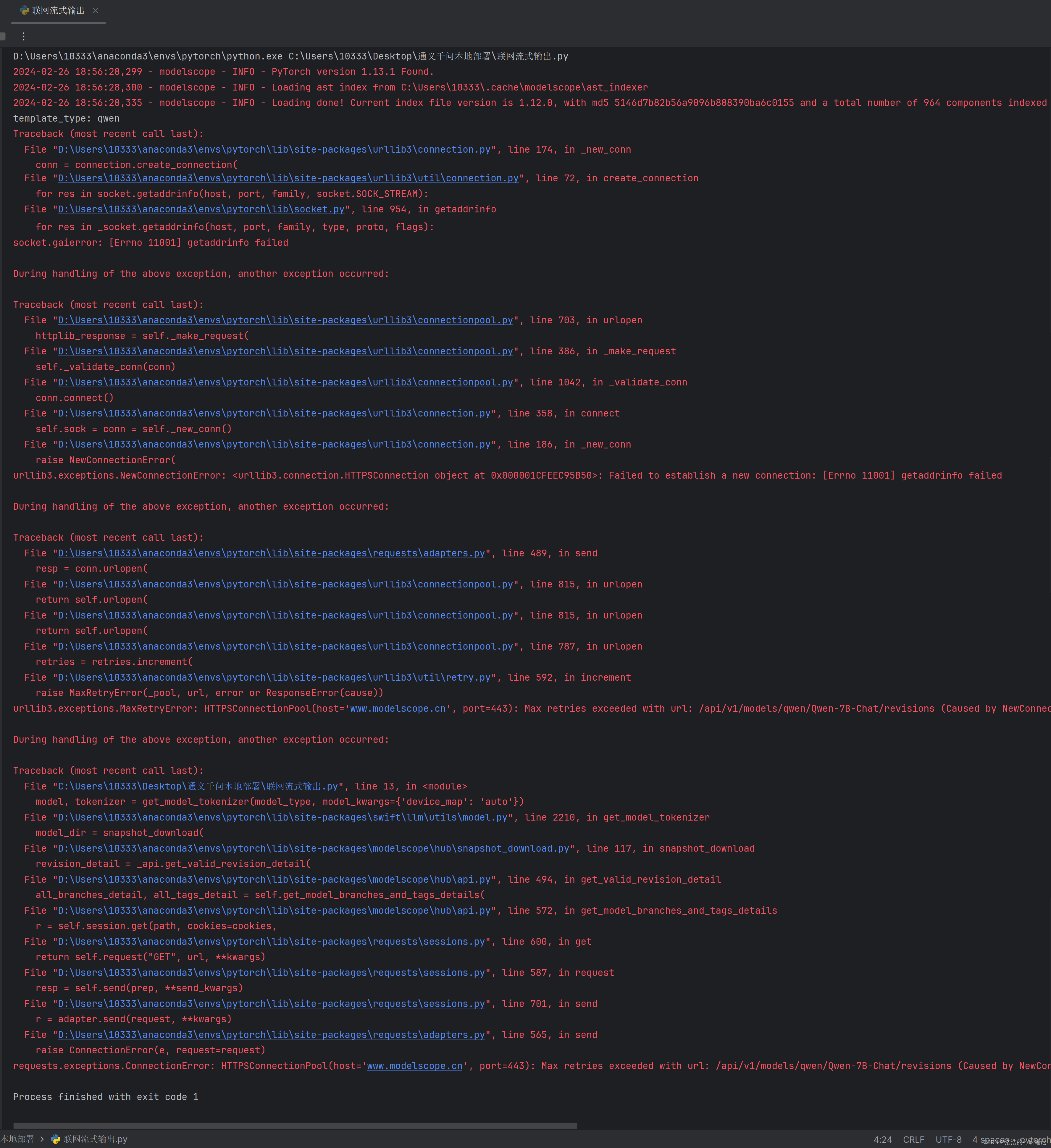
可是即便是第二次及之后运行,其不联网依然会报下面的错误,总之该代码不能实现无网络状态下的流方式输出,这也是一个大坑。
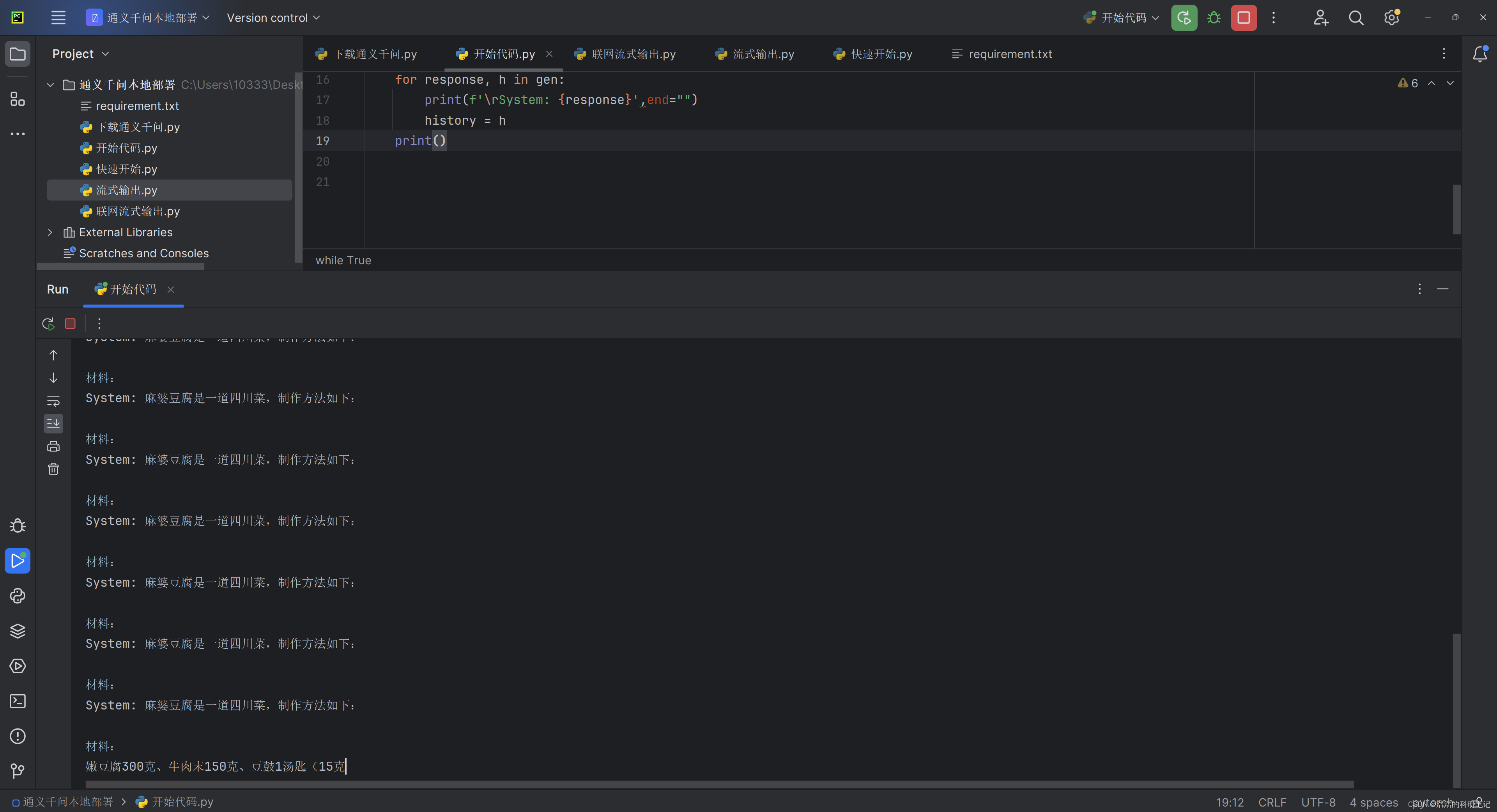
根据对代码的分析,最后首先我实现了V1版本的代码,代码如下使用中的API进行流式输出,且可以加载本地的自己的模型,这里再中加入换行符会让每次打印的时候光标出现在行的开头,当输出的文字中没有换行的时候,输出的结果岁月静好。
当输出内容过长需要换行的时候结果直接负重前行(自己创造的大坑)。
4.2 真正实现离线的使用本地模型的多轮对话和流式输出的最终代码⭐
之后改进了V2版本也是最终版本,代码如下,由于这个代码是我自己悟的可能还有不少可以改进的地方,但是已经可以实现预期的的功能,详细的解释我放在后面 首先再次给出swift安装命令。
代码部分:
下面是逐行解释:
- : 从库中导入和。用于加载和使用因果语言模型(如GPT),用于文本的分词和编码。
- : 从模块中导入和函数。用于生成文本流,用于获取特定类型的模板,这里的模板可能是指模型的输入格式或结构。
- : 定义模型的存储路径。
- : 加载预训练的分词器。方法从指定路径加载模型,允许加载远程代码,这通常用于加载自定义的模型或分词器。
- : 加载并准备模型。同样用于从指定路径加载模型,表示自动选择设备运行模型(如GPU或CPU),同上。将模型设置为评估模式,通常在预测或评估时使用,以禁用特定于训练的操作如Dropout。
- : 定义模板类型,这里为。
- : 获取指定类型的模板。这里的模板可能用于定义输入的格式或者是模型预处理的一部分。
- : 初始化历史记录变量,用于存储对话历史,以便模型可以根据之前的交流生成回应。
- : 初始化变量,用于记录上一次生成文本的长度。
- : 开始一个无限循环,用于连续接收用户输入并生成回应。
- : 接收用户的输入。
- : 调用函数,传入模型、模板、用户查询和历史记录,开始生成模型的回应。
- : 打印“System:”,不换行,准备输出模型的回应。
- : 遍历生成器的输出,输出的每个元素包含回应和更新后的历史记录。
- : 打印新生成的回应部分(去掉之前已经打印的部分),不换行。
- : 更新已打印文本的长度。
- : 更新历史记录,以便在下一次迭代时使用。
modelscop模型介绍下载地址
https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
swift文档地址
https://github.com/modelscope/swift/blob/main/docs/source/LLM/LLM%E6%8E%A8%E7%90%86%E6%96%87%E6%A1%A3.md
目前这是我出的第一篇大语言模型的部署的文章,之后会考虑一直更新这个系列,会不定期的完善细节,之后会越来越多的补充,如果有什么问题,欢迎留言探讨。有专业需求可以在公众号上联系我。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/257651.html原文链接:https://javaforall.net


