
之前有关FlashAttention V3的文章感觉有些难度,不符合大众化阅读,加上五一假期刚结束,为了帮助大家找到学习状态,所以决定这次写一篇极其友好的文章,保证看起来丝滑,如题。
上周Qwen3刚发布时,转载了一篇ktransformers的文章,ktransformers比较适合经济型部署,设备门槛略低一点,具体可以看一下ktransformers的介绍。
本文基于vllm框架最新版本0.8.5.post1实际部署Qwen3-235B-A22B模型,模型配置可见huggingface(https://huggingface.co/Qwen/Qwen3-235B-A22B或https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen3_moe/configuration_qwen3_moe.py)或Qwen官方的介绍:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 32,768 natively and 131,072 tokens with YaRN.
有很多种方式:1.源码编译安装 2.官方wheel文件的安装 3.使用官方release的docker
一般情况下,如果不是开发者,只是使用者,那么采取第3种方式即可,如果是开发者,那么源码编译安装是必需的,本文采取第3种方式
- docker镜像选择:vllm一般会把各个release版本的稳定docker镜像上传到dockerhub,在dockerhub搜索vllm即可查到,本文采取的docker镜像为“vllm/vllm-openai:0.8.5.post1“
- docker容器启动:dockerhub里的vllm镜像最后一个命令为ENTRYPOINT,意味着docker启动的同时会运行的命令,所以这个vllm镜像启动的同时会启动openai server,因为我们部署的是Qwen3-235B-A22B,所以我们需要在命令行指定该model,否则默认部署的是opt-125M。此外指定tp为8,使用8卡来部署。(4卡也可,只要装得下参数且能有余量保存足够的kv cache就行)
千问 Qwen 教程



tips:如果不想docker启动的同时运行某个命令,可以在命令行添加–entrypoint /bin/bash,这样的话,启动docker即直接进入命令行,不会自动启动server部署Qwen3模型,如下图

本文采取了docker启动的同时运行openai server serving Qwen3模型,即tips上面的命令,输出log如下
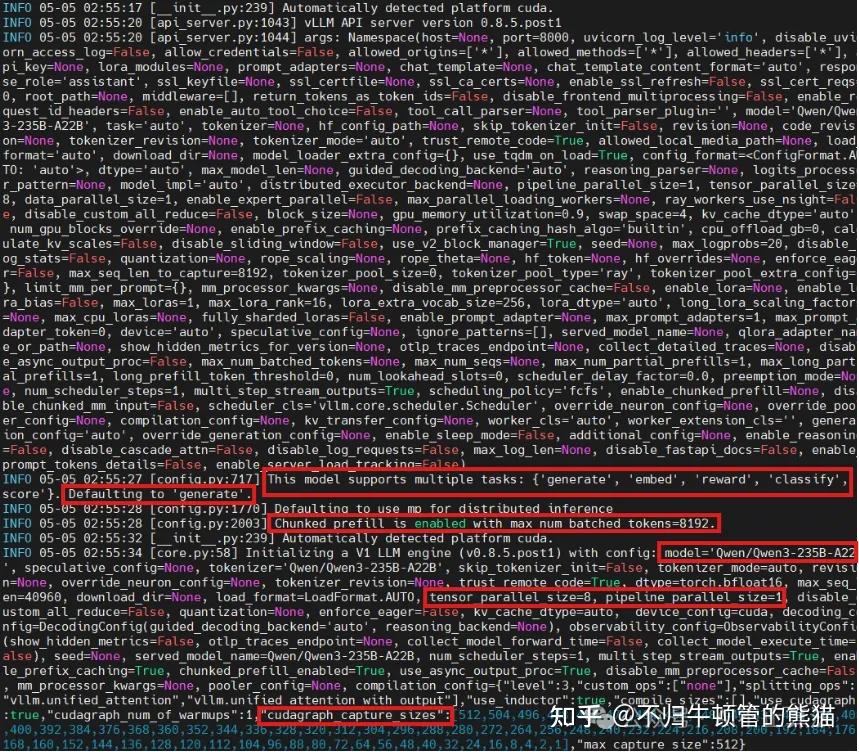
获取到的有用信息:
- 模型支持generate、embed、reward、classify、score,默认是generate,即文本生成式
- chunked prefill默认打开,batched token数量是8192
- 模型的确是Qwen/Qwen3-235B-A22B
- tp size为8
- cuda graph capture的batch size大小有几十个,最大的batch size为512
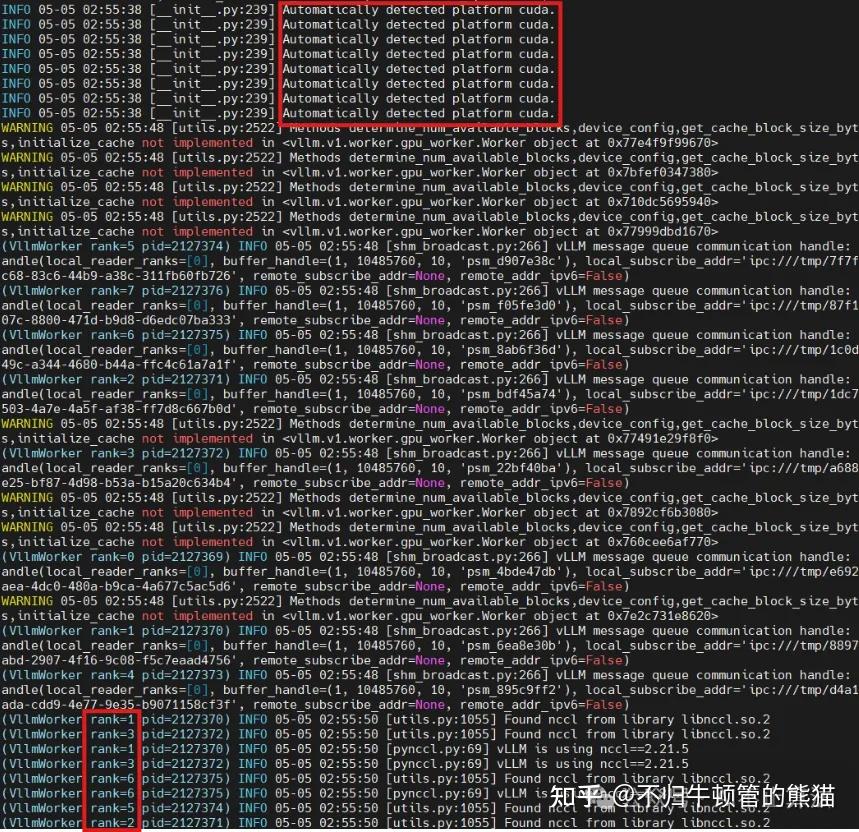
获取到的有用信息:
- 因为是8卡部署,所以框起来的“automatically……cuda“`显示了8次,在每张卡上面都要初始化都要check一次nccl
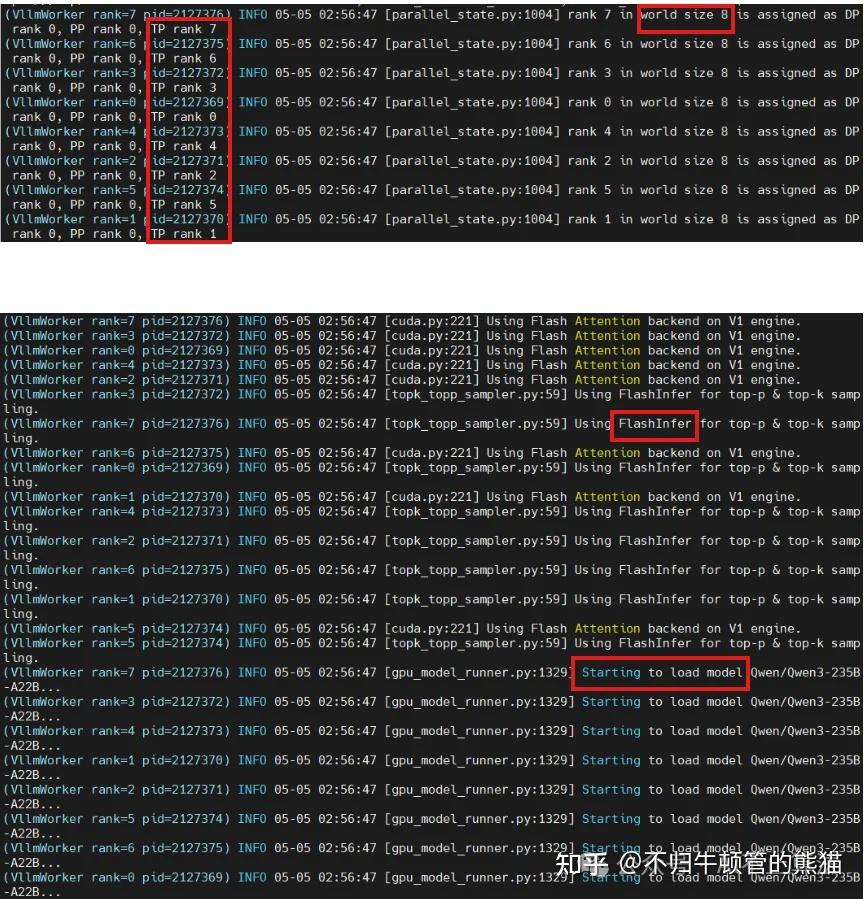
获取到的有用信息:
- world size=8,即总共是8张卡,这8张卡全都用来做tp
- flashinfer库用来计算top-p和top-k
- 而后开始load Qwen2-235B-A22B
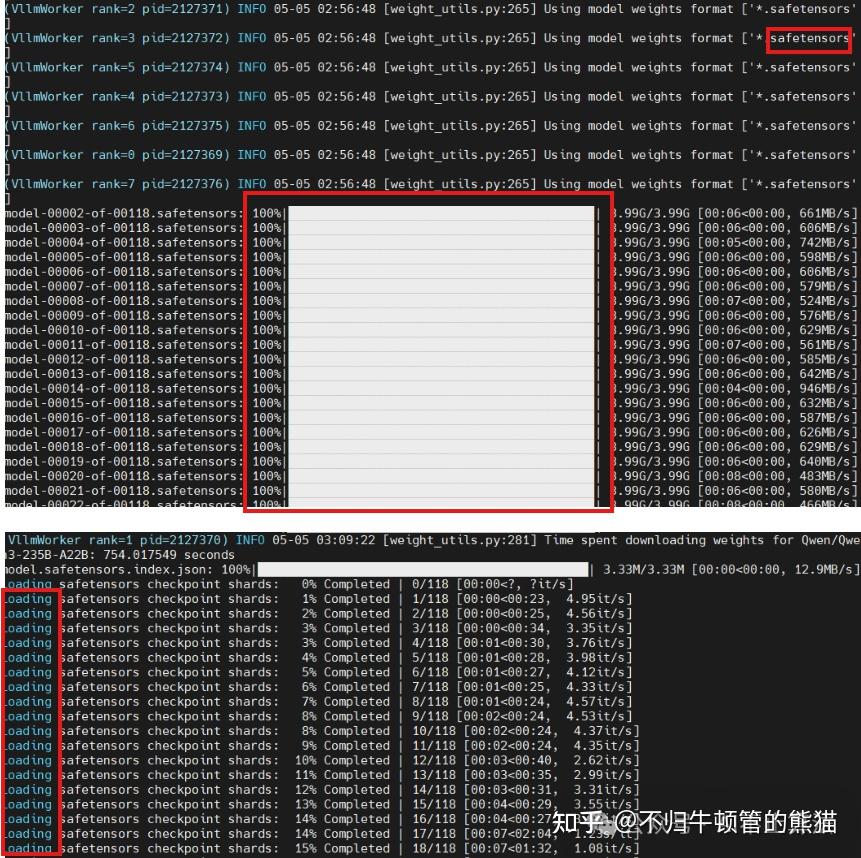
获取到的有用信息:
- 首次部署该模型时,会去huggingface下载,而后缓存到huggingface的默认缓存目录(/root/.cache/huggingface),之后部署时,就不用下载而是直接load
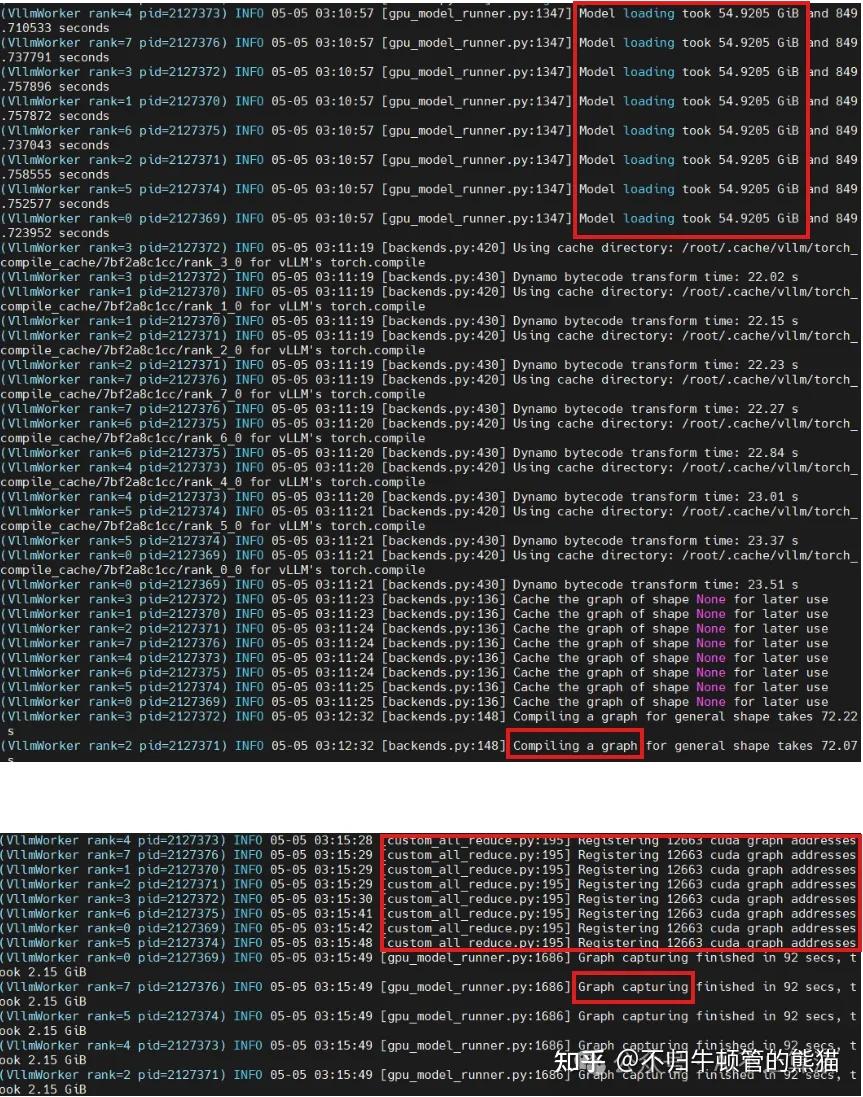
获取到的有用信息:
- 模型加载完成后,每张卡花费了54.9GB,这里面不光是weight所占空间,还有kv cache等预留空间
- 为custom allreduce算子注册在cuda graph上的地址,便于capture
- 开始capture cuda graph
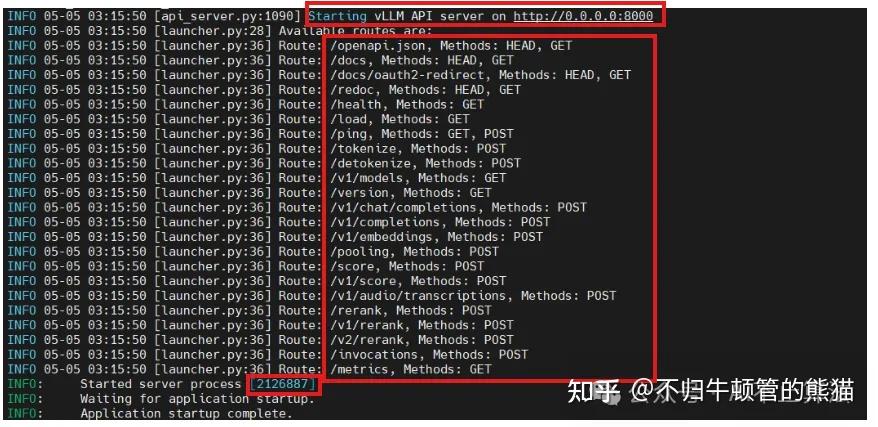
获取到的有用信息:
- Qwen3在http://0.0.0.0:8000这个地址serving
- 有如上的很多http GET和POST方法可用
- Qwen3部署服务的进程号是
此时我们的GPU显存占用情况如下,聪明的读者或许已经猜出型号,但是我还是要为了zzzq打个码
由此,我们的Qwen3-235B-A22B模型就serving起来了,接下来我们只需在客户端发送请求给它处理,然后返回给我们就OK了
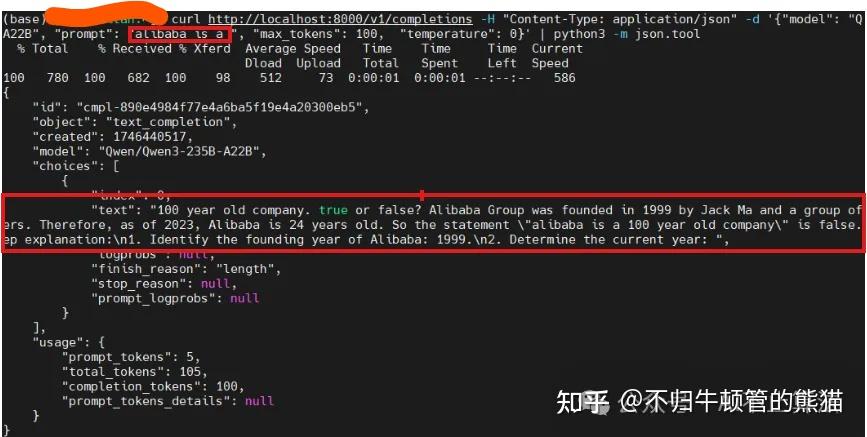
默认情况下,我们没有采用thinking模式,发送请求的命令如下,可用看到没有任何thinking过程
在给启动docker的命令中加上–enable-reasoning –reasoning-parser deepseek_r1后,即开启thinking模式。此时客户端请求命令为以下,可以看到reasoning_content为思考过程,content为最终答复
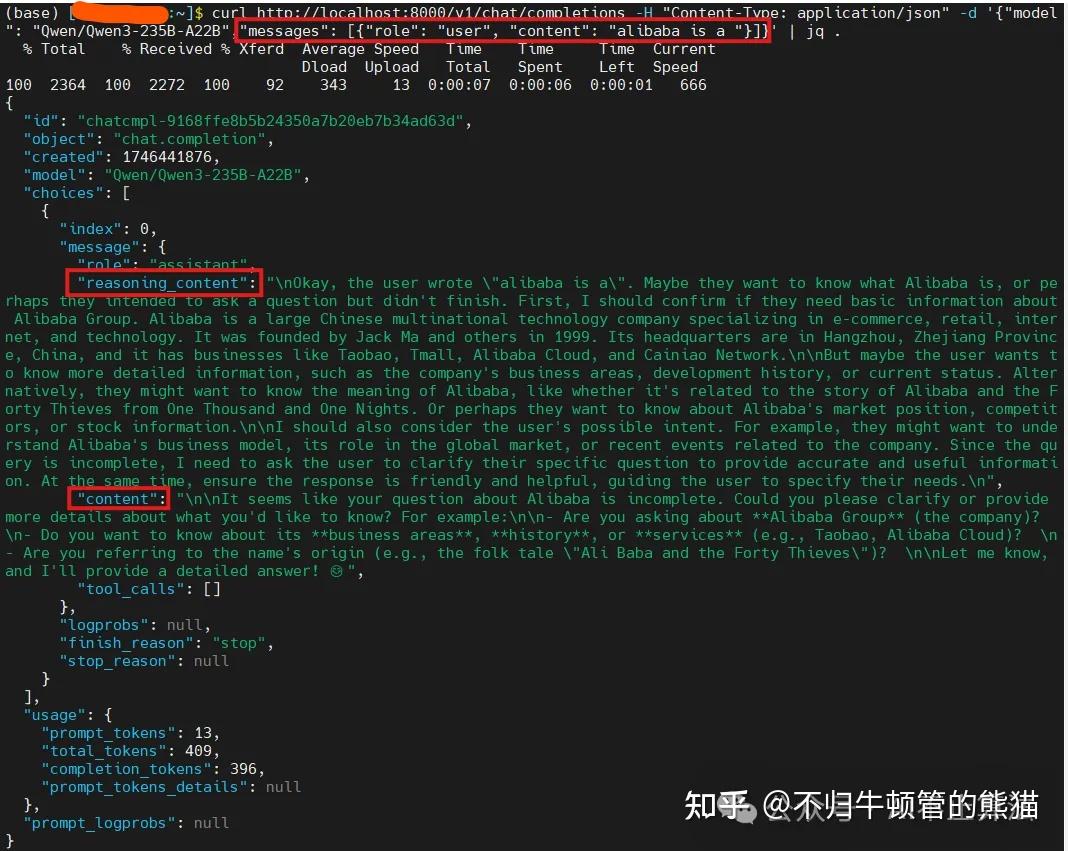
此时服务端的log为以下,可以看到平均的generation throughput为54.3tokens/s,注意如果要得到框架的极限性能,需要使用项目中的benchmark脚本,下期或下下期文章根据反响再来考虑示范

我们再尝试一个http GET方法,对v1/models发出GET请求,响应如下,可以看到打印出了model信息

最后,总结一下,我们本文示范了使用vllm部署使用Qwen3-235B-A22B的基本过程,并且解析了log,展示了整个过程做了哪些事情,成功把模型部署在了某个地址,最后朝这个地址发出请求即可得到响应。后面将根据读者反响考虑再展示一下SGLang如何来部署模型,并且探索vllm和SGLang的服务性能。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/258292.html原文链接:https://javaforall.net


