
在林俊旸千问 Qwen 教程卸任 Qwen 负责人后,看到与其接触过的大家对其评价都很高,有没有认识的朋友来说说?
你问Qwen贡献,这张图懂得都懂。Qwen让太多行业,B端,G端项目可以轻松交差,让甲方和基金能痛快掏钱,让各行各业也能开个发布会摸个水晶球。


大多技术leader的履历是这样的:斯坦福/CMU博士,Google Brain/DeepMind镀金,回国拿几千万年薪,空降CTO。这套路径已经被VC和媒体包装成了唯一的”AI大牛标准模板”。
林俊旸的履历:本科国际关系学院英语语言文学,硕士读的是北大外国语学院的语言学。 2019年应届毕业进达摩院,高级算法工程师起步。没有海外顶会一作刷榜的光环,没有硅谷大厂的title加持。就是一个在内部从M6项目开始啃的年轻人,2022年被推到千问技术负责人的位置上,2025年32岁拿到阿里史上最年轻P10。
那么,我们到底能不能靠内部培养,而不是靠外部空降,把核心技术团队撑起来?
国内大厂做开源,常见的模式是什么?训完模型,放出权重,发一篇技术博客,团队转头继续做闭源的商业版本。开源更多是一种”秀肌肉”的品牌动作,社区反馈也不会回流到研发流程里。
林俊旸长期泡在X上跟全球开发者互动,半夜发模型、实时收反馈、下一版迭代直接把社区的issue吃进去。Hyperbolic Labs的CTO回忆过,他们联合发布Qwen 3 Next API的时候,北京时间早上六点,林俊旸和团队还在线盯着。
所以,很多海外开发者对Qwen的态度和对其他中国模型的态度是明显不同的。他们愿意在生产环境里用,愿意基于Qwen做二次开发,原因就是他们觉得这个团队是”真的在听我说话”。
中国AI出海喊了这么多年,大部分公司花大钱投广告、办meetup,效果平平。林俊旸用一个人的X账号和持续的社区响应,帮Qwen建立起来的海外开发者关系网络,可能比很多公司整个国际市场部干的活都多。
林俊旸在今年1月提了一个观点叫“模型即产品”——做基础模型本身就是在做产品,研究人员需要像产品经理一样思考。
这句话在行业里其实引发了一些争论,不少纯研究背景的人觉得这是在”矮化”研究。但我认为这恰恰是他对行业认知上的一个关键贡献。
过去三年,中国大模型行业最大的资源浪费是大量优秀的基础模型研究成果,死在了从paper到product的最后一公里。 技术很强,但没人用;开源了,不好用;benchmark刷得漂亮,真实场景下表现拉胯。
千问App从去年11月上线到月活突破2.03亿只用了三个月,春节期间1.3亿用户用千问下单超2亿次。他把模型能力接到了买奶茶、点外卖、订票这些极其具体的场景里。
3月4日林俊旸发那条告别推文之后,他的同事Chen Cheng那句“离开并非你的选择”基本上把事情的性质定了。结合多方信息来看,导火索大概率是阿里内部对千问团队进行了组织架构拆分,把原来林俊旸主导的垂直闭环模式拆成了水平分工的流水线结构,同时收缩了他的管理权限。
不评价这个决策的对错,但组织架构的调整逻辑是按照传统业务线的管理思维来的,有没有认真考虑AI研发团队的特殊性。
预训练和后训练之间的深度耦合、多模态团队的闭环协同,这些不是管理偏好的问题,是工程上的hard constraint。你强行拆开,团队leader要么接受降级、要么走人。结果就是林俊旸走了,后训练负责人郁博文走了,Qwen Code负责人惠彬原1月份就去了Meta,核心贡献者Kaixin Li也走了。
短短两个月,千问核心技术层接近半数流失。而这还只是阿里通义实验室人才流失的最新一轮——之前周畅被字节千万年薪挖走、鄢志杰离职、薄列峰离职,已经是连续剧了。
你可以花几年时间培养出一个林俊旸,但只需要一次组织架构调整就能把他和他的核心团队全部送走。 而在AI这个领域,核心团队散了,短期内是补不回来的。模型权重还在,但做模型的那群人的默契和判断力,不在代码仓库里。
至于林俊旸下一步去哪,投资人已经在抢了。他自己发了条朋友圈说今天不回消息了需要休息。按他这个级别和行业认可度,不管是创业还是加入其他机构,大概率很快就会有新消息。
但对Qwen来说,对阿里来说,不是损失一个P10的问题,是损失了一整套经过验证的、从研发到开源到社区运营的方法论的执行者。
方法论可以写成文档,但执行方法论的人走了,文档就只是文档。
中国是现在为数不多还在涌现开源模型的国家之一,开源模型数量多且质量高。
阿里的Qwen系列,DeepSeek,Kimi,智谱的GLM,MiniMax,Stepfun,甚至可以毫无疑问的说中国就是现在开源世界的大半边江山。
大家各有特色,且都在国际上有一票铁杆粉丝。
Qwen系列最大的特点,就是它是很多模型的基础模型。
比如我们在Huggingface上设置两个条件:1 模型大小在(0,12]B之间 2 排序按照Trending(趋势)
前面的几个全都是Qwen系列,当然了,这些都是所谓“小”模型,属于不需要非常大的算力也可以跑的模型,跟动不动需要几十上百块GPU的集群需求模型区别很大。

然后我们再看trending里面的其他模型,比如这个LocoreMind,看名字没见过,大概率属于“名不见经传”的野模型,模型也比较小,才4B。
但你别小看这种小的模型,需要的计算资源虽然不需要特别多,但是数据资源这个一般人搞不来的,这玩意是真的体力活,需要大公司雇人来搞。
你再看师承,base model:Qwen3-4B-Instruct-2507,Teacher Model: Qwen3-Coder-Next。
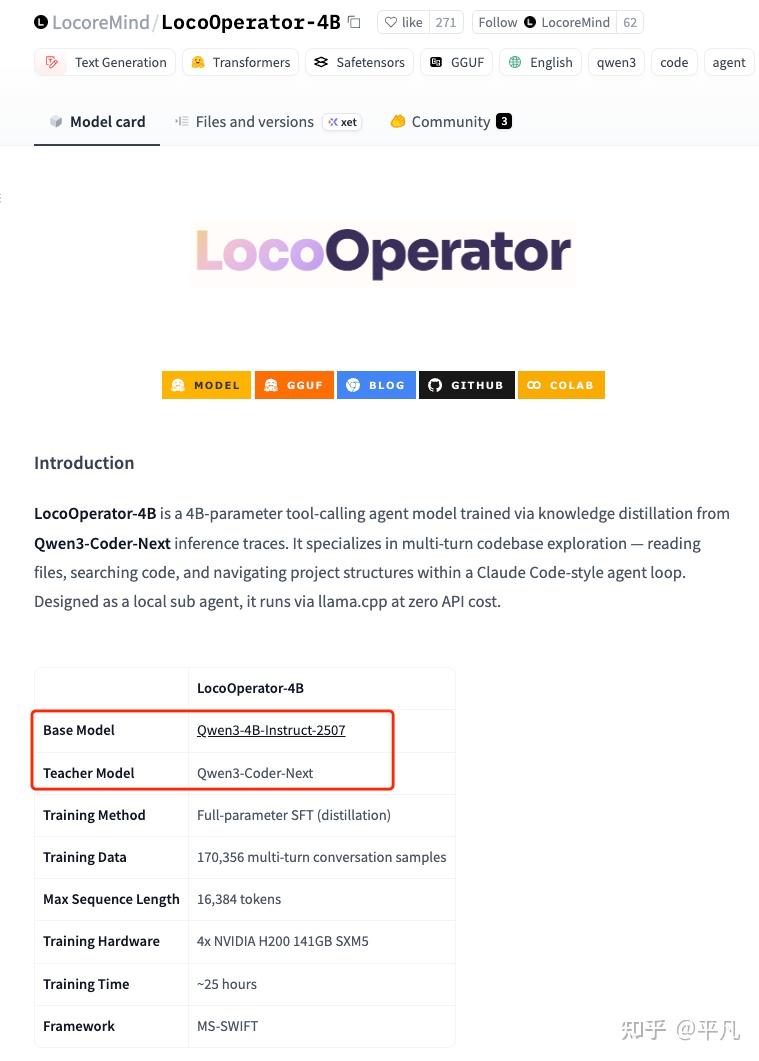
一切很清楚了,这个模型是在Qwen3的4B模型的基础上,用了更大的Qwen3-Coder-Next蒸馏出来的模型做的fine-tune。
我非常的怀疑这个fine-tune模型大概率不如原来的模型。
因为大公司有更多的资源反复的训练一款模型让它达到最优解,而小的公司甚至实验室基本没多少次试错机会。
但是,就这么一搞,一个公司或者一个实验室就有自己的大模型,再说了Qwen也有Qwen3.5-397B-A17B这种千亿参数的大模型。
可以说,从个人到小型团体到乃至于一个中小型国家,都可以在Qwen里面找到合适自己的基础模型。
这个非常重要。
因为你想想,如果没有这些开源模型默默贡献,这个世界上的人就只能用OpenAI,Anthropic,Google他们的模型。
倒也不是他们的模型不好,但是一旦一件事情被垄断以后,第一是创新速度下降(OpenAI不是被DeepSeek逼了一把,他们都不知道自己可以出模型出的这么快),第二个用户地位会降低,因为你没有被选项,那么唯一项就会作威作福。
以上,这就是Qwen乃至整个开源世界的贡献。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/259383.html原文链接:https://javaforall.net


