


作为通义千问第三代模型,Qwen3 在保持轻量化的同时,实现了能力维度的全面突破:
- 双模式智能切换:
- 思考模式:激活深度推理引擎,擅长复杂数学题求解(如竞赛级代数/几何问题)、长链式逻辑推理、专业代码生成(支持多语言框架,代码通过率超 90%)。
- 非思考模式:响应速度提升 30%,适合日常对话、信息检索、多轮闲聊,支持 8K 上下文流畅交互。
- 多语言与代理能力:
- 覆盖 119 种语言及方言,多语言翻译流畅自然,指令遵循准确率达 95% 以上。
- 内置工具调用解析器,可自动生成标准格式的函数调用(如 SQL 查询、API 调用),复杂任务完成度领先开源模型 20%。
VLLM:重新定义本地推理效率

VLLM 通过三大技术革新,让 80 亿参数模型在消费级硬件上跑出新高度:
- 动态批处理调度:基于优先级队列智能复用计算资源,吞吐量较传统框架提升 10 倍,支持数百并发请求。
- 量化与编译优化:
- 原生支持 4bit/8bit 量化(BitsAndBytes/AWQ),显存占用压缩至原生模型的 1/4。
- 集成 TorchCompile 与 CUDA 图技术,首次编译后推理速度提升 50%,生成 tokens 成本降低 30%。
- 开箱即用的服务能力:
- 内置 FastAPI 服务器,支持 OpenAI 兼容 API,10 分钟内可搭建对话接口。
- 提供工具调用、流式输出、多卡并行等企业级功能,无需二次开发。
硬件与软件基础配置
- 硬件要求:
- 显卡:至少 24GB 显存的 NVIDIA GPU(如 RTX 4090/3090 Ti,实测用 VLLM API 部署 Qwen3-8B-4bit 显存占用约 20GB)。
- 软件安装:
- 版本要求:
- VLLM的版本>=0.8.5,
- transformers版本>4.51.0
模型选择与获取
- 推荐模型:Qwen3-8B-unsloth-bnb-4bit
- 特性:4bit 量化版本,兼顾性能与精度,推理延迟较 16bit 模型仅增加 15%。
- 下载方式:
./目标文件夹 改为自定义的文件夹名称(当前终端目录下)或者路径
启动命令与参数解析
关键参数说明:
或者通过Python代码方式进行接口测试:
为什么会有额外的显存占用?
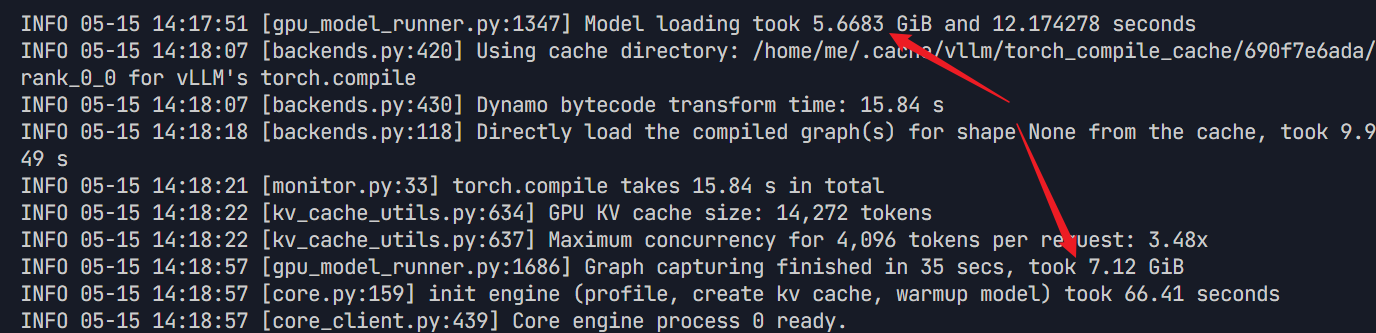
从运行截图中我们可以看出模型本身占用大概5.7GB,计算图缓存约7.12GB,总共约12.82GB,但使用 nvidia-smi 指令我们千问 Qwen 教程可以看到实际占用了约16.6GB显存,那多出来的部分被谁消耗了呢?
经过排查了推理,剩下的3GB左右的内存大概由预留的令牌缓存空间 、并发控制数据(0.5G)和vLLM 运行、FastAPI 服务器、PyTorch 依赖运行(2.5G)组成。至此找到了额外的显存占用的原因。
有没有更省显存的模型调用方式呢?
你好,读者,有的有的!如果不想持续化本地部署,而只是想单次小规模调用的话,官方也给出了标准Python代码以供测试:
希望你对本篇博客满意,我是Tex-mind,我们下期再见!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/261219.html原文链接:https://javaforall.net


