
首先先简单介绍下两个系列的模型:
DeepSeek-R1是由深度求索公司推出的首款推理模型,该模型在数学、代码和推理任务上的表现优异。深度求索不仅开源了DeepSeek-R1模型,还发布了从DeepSeek-R1基于Llama和Qwen蒸馏而来的六个密集模型,在各项基准测试中均表现出色。本文以蒸馏模型DeepSeek-R1-Distill-Qwen-7B为例,为您介绍如何微调该系列模型。
Qwen3是阿里云通义千问团队于2025年4月29日发布的最新大型语言模型系列,包含2个MoE模型和6个Dense模型。其基于广泛的训练,在推理、指令跟随、Agent 能力和多语言支持方面取得了突破性的进展。PAI-Model Gallery已接入全部8个尺寸模型,以及其对应的Base模型、FP8模型,总计22个模型。本文为您介绍如何在Model Gallery部署评测该系列模型。
刚好最近在做一个推理训练任务,现千问 Qwen 教程在有现成的训练集,推理模型这么强的情况下,怎么把之前传统对话大模型+指令微调训练模式转变成推理大模型+指令微调任务?
后训练广义可能范围比较大,包括微调、强化学习等。 可能我们构造强化学习数据集或者思维链数据集的成本比较高的,所以今天咱们就聊一聊怎么偷懒地将把之前的指令数据集或者指令微调的工作推演到推理大模型训练上呢?有没有比较省事或者比较规范的做法呢?
通过能力比较强的推理大模型底座将之前指令数据集蒸馏为思维链数据集,然后进行筛选过滤。
具体做法我们可以参考刘聪大佬开源的Chinese-DeepSeek-R1-Distill-data-110k,大致流程是调用企业版满血R1 API,然后数据生成结果进行了二次校验,并保留了评价分数:
- 针对Math和Exam数据,先利用Math-Verify进行校对,无法规则抽取结果的数据,再利用Qwen2.5-72B-Instruct模型进行打分,正确为10分,错误为0分。
- 针对其他数据,直接利用Qwen2.5-72B-Instruct模型从无害性、有用性、正确性/完整性三个角度进行打分,分值范围为0-10分。
下面以一个推理数据集为例,
medical-o1-reasoning-SFT医学推理数据集,该数据集基于医学可验证问题和 LLM 验证器构建,这个数据集构造过程和方法1提到的差不多。方法1强调如何通过推理大模型蒸馏指令数据集,方法2强调如何通过已有COT构造推理数据集
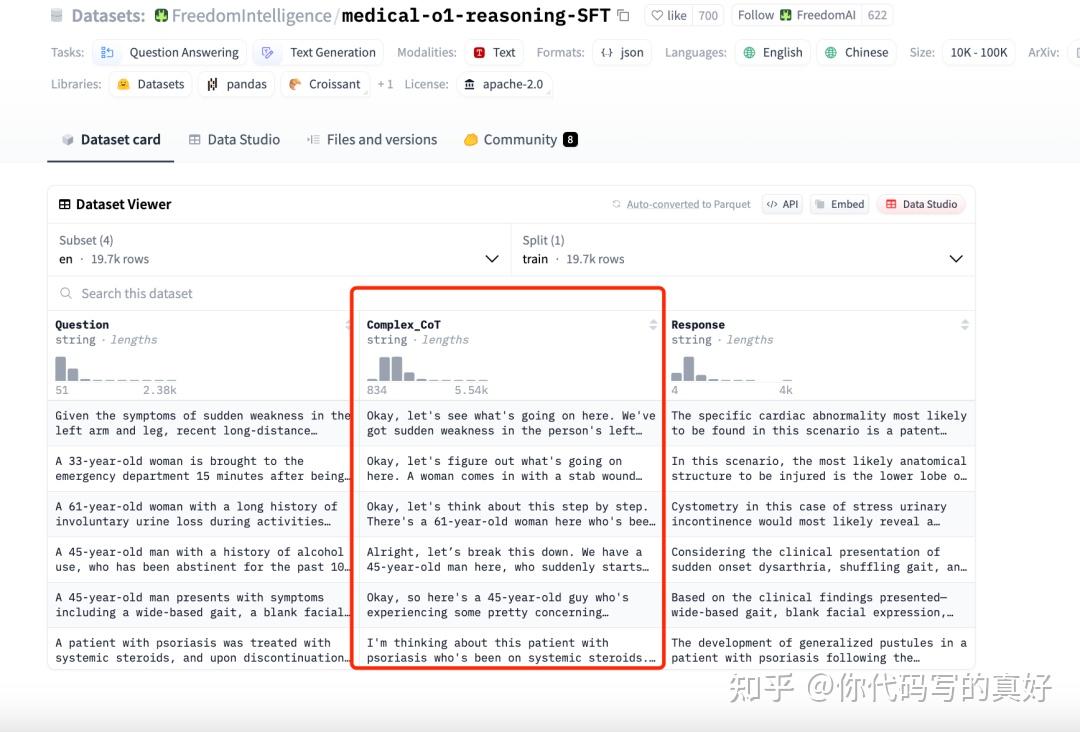

以下面模板为例:
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response. Instruction: You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. Please answer the following medical question. Question: {} Response: <think> {} </think> {}"""有了模板下面我们直接通过占位符填充COT字段即可
EOS_TOKEN = tokenizer.eos_token# Must add EOS_TOKEN def formatting_prompts_func(examples): inputs = examples["Question"] cots = examples["Complex_CoT"] outputs = examples["Response"] texts = [] for input, cot, output in zip(inputs, cots, outputs): text = train_prompt_style.format(input, cot, output) + EOS_TOKEN texts.append(text) return { "text": texts, }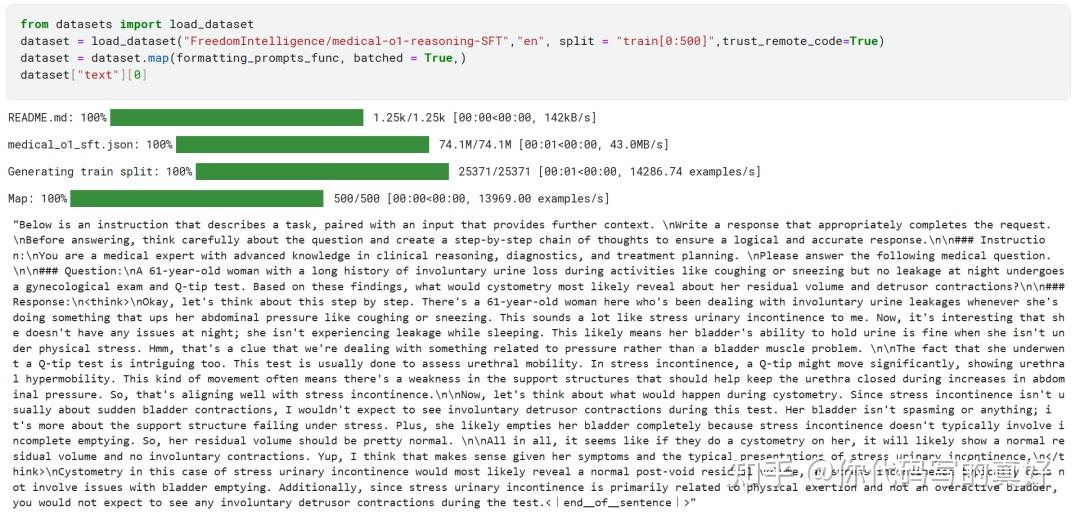
那么还有一种方式就是,我们是不是也可以直接通过比较”素”的指令数据集训练R1类似模型呢,答案是可以!
这里“素”指的是只有instruction/input/output,没有推理思维链类似字段
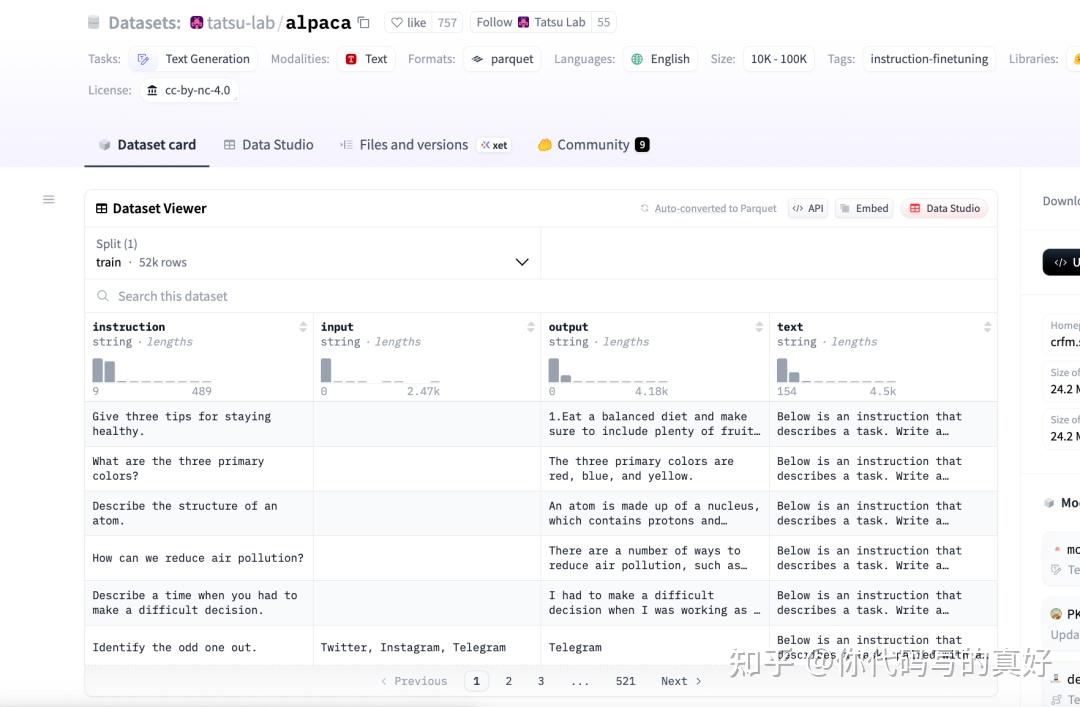
笔者实测过, 这样微调出来的效果是丢失了思考过程,但是效果发现是没问题,设置32B推理模型超过了72B对话模型。

针对下游任务,如果我们不想要思考过程,可以直接采用第三种方法,这种微调简单粗暴,效果也比传统同参数对话模型好一些。如果想要思考过程,可以参考方法1和方法2来准备数据,然后采用微调的方式进行训练即可。
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
大模型:yyds!全网独一份的AI大模型学习教程资源!!
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

大模型:yyds!全网独一份的AI大模型学习教程资源!!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/262776.html原文链接:https://javaforall.net


