
前两天,通义千问推出的 Qwen3-Embedding 系列模型(包括8B、4B和0.6B三个版本)在权威评测中表现惊艳,尤其在多语言任务和长上下文处理能力上全面超越主流竞品,成为开源嵌入模型的新王者。
Qwen3-8B以70.58总分登顶榜单(超越Gemini-001的68.37),在16项评测中12项第一,尤其在检索精度(MSMARCO 57.65)、问答能力(NQ 10.06) 等关键任务上表现惊艳。
即使最小尺寸的Qwen3-0.6B(仅595M参数),总分64.34仍显著超越7B级竞品(如SFR-Mistral 60.9),小模型也有大能量!
| 指标 | Qwen3-8B | BGE-M3 | 优势幅度 |
|---|---|---|---|
| 综合得分 | 70.58 | 59.56 | ↑11.02 |
| 上下文长度 | 32K | 8K | ↑ 4倍 |
| 检索任务(MSMARCO) | 57.65 | 40.88 | ↑41% |
| 开放问答(NQ) | 10.06 | -3.11 | 实现负分逆转 |
| 多语言理解 | 28.66 | 20.10 | ↑42% |
Qwen3在保持99%榜单合规性的同时,以更高维度参数(8B vs 568M)和4倍上下文支持,彻底改写Embedding模型性能边界!
同为7B级别:Qwen3-8B对比Linq-Embed-Mistral(61.47)、SFR-Mistral(60.9),性能领先超15%。
轻量级战场:Qwen3-0.6B(64.34)大幅领先同类小模型如multilingual-e5-large(63.22)、BGE-M3(59.56),证明通义千问架构的高效性。
根据官方文档自行部署GPUStack,官方提供了Docker镜像,可快速部署。
在GPUStack的 模型 界面,点击 部署模型 -> ModelScope,搜索qwen3-embedding。平台会自动检测你的硬件性能,推荐可以安装的量化模型版本。
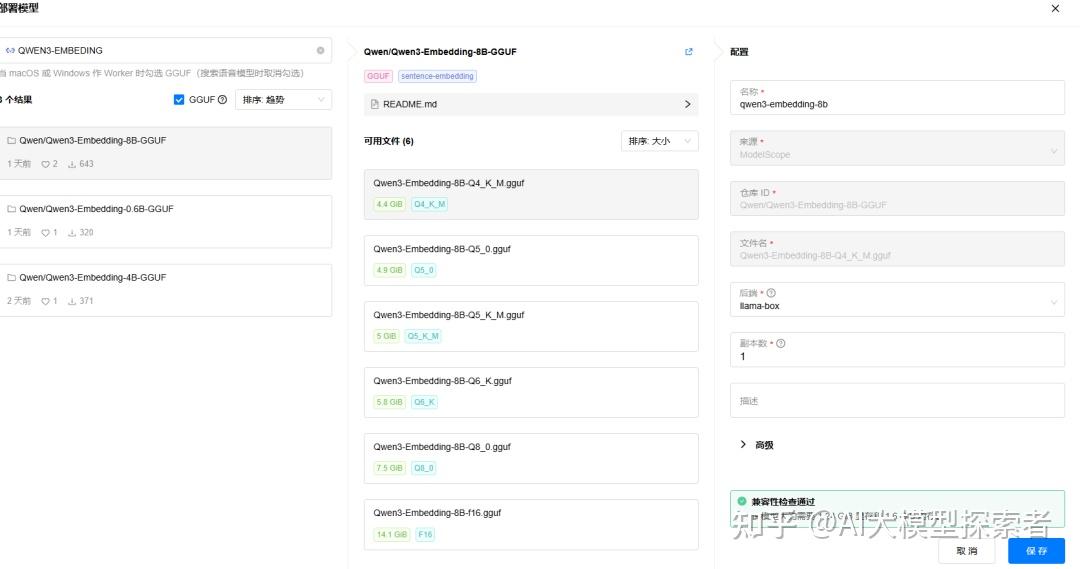

gpustack 部署 qwen3-embedding
我们选择了 qwen3-embedding-8b的Q8_0量化版本,等待模型下载,提示 running,表示模型已经部署完成。
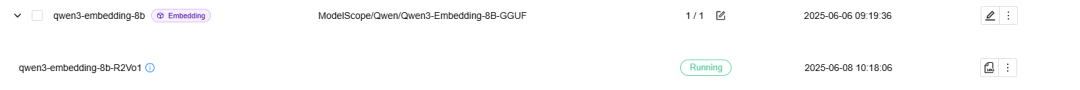
qwen3-embedding 模型部署成功
现在Dify的插件市场中找到GPUStack,点击安装插件。等插件安装完成后,进行模型配置。
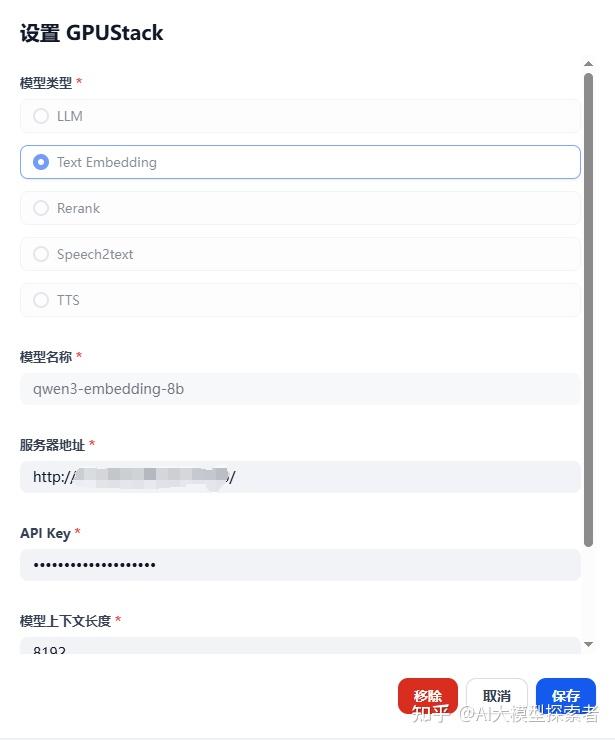
Dify 中配置本地GPUStack部署的 QWEN3-EMBEDDING
创建知识库,在Embedding模型中,选择我们自己部署的模型。
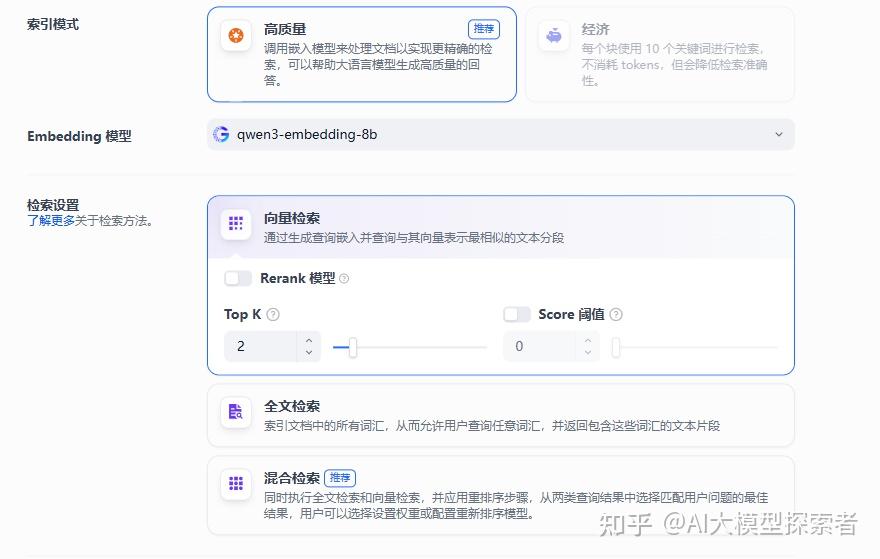
Dify知识库创建
把公众号的历史文章,放入知识库进行测试。
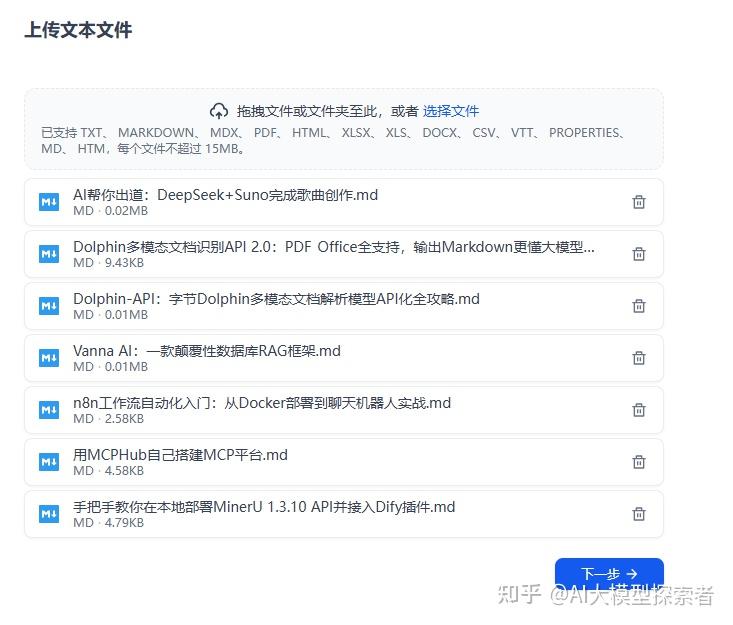
上传文档
选择Dify的父子分段策略。由于是markdown格式,希望每一个大段为一个父块,分段符选择 “#”.

配置解析方式
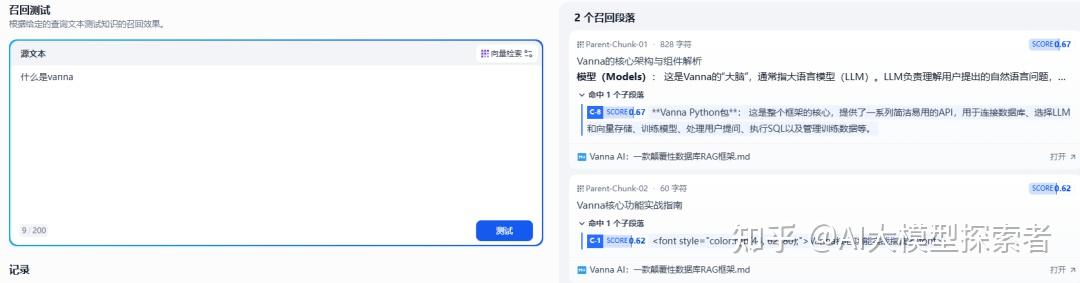
测试一下召回情况
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
大模型:yyds!全网独一份的AI大模型学习教程资源!!
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

大模型:yyds!全网独一份的AI大模型学习教程资源!!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/263310.html原文链接:https://javaforall.net


