
OpenAI 于 2025 年 4 月 14 日发布了专为开发者打造的全新模型系列——GPT-4.1。该系列包括旗舰级的 GPT-4.1、高速的 GPT-4.1 Mini,以及有史以来最小、最快、最经济的 GPT-4.1 Nano。
这些模型目前仅通过 API 提供,暂未上线 ChatGPT 界面,但可以在 OpenAI 的 API Playground 中试用。
所有三款模型均支持高达 1,047,576 Token 的窗口和 32,768 Token 的输出和图片输入,知识截止日期为 2024 年 5 月 31 日。GPT-4.1 系列在编码能力、复杂指令遵循、长文本处理以及多模态理解方面均实现了显著提升,GPT-4.1性能全面超越 GPT-4o,并在关键指标上比肩甚至超越 GPT-4.5。
具体来说,模型在编码基准测试(如 Aider benchmark)和长文本基准测试中得分高于 GPT-4o 和 GPT-4.5,并在指令遵循方面有所改进,包括遵循请求的格式、遵守否定指令、排序输出以及在不确定时回答“我不知道”。OpenAI 强调了该模型的代码性能。定价方面,GPT-4.1 Mini 和 Nano 提供了更经济的选择,特别是 GPT-4.1 Nano,其输入价格为 0.10 美元/百万 Token,输出价格为 0.40 美元/百万 Token,低于之前的最便宜模型 GPT-4o-mini。GPT-4.1 的定价为输入 2 美元/百万 Token,输出 8 美元/百万 Token。
OpenAI 还宣布,随着 GPT-4.1 的推出,将在三个月内(2025 年 7 月 14 日)停止 API 中的 GPT-4.5 Preview 服务,以便开发者过渡。
OpenAI 团队成员在发布直播中透露该模型的内部代号为 Quasar,OpenRouter也解释之前的两款免费模型均为GPT-4.1的早期版本。
微软 Azure OpenAI 服务、GitHub Copilot、Cursor IDE、Windsurf 等平台已宣布集成或提供 GPT-4.1 系列模型,目前在多个编程工具及官方的API中均有一周的免费体验时间。


https://openai.com/index/gpt-4-1/
https://platform.openai.com/docs/models/compare?model=gpt-4.1
https://platform.openai.com/playground
智谱 AI GLM 教程
https://github.com/simonw/llm-openai-plugin
https://aider.chat/docs/leaderboards/
https://openrouter.ai/announcements/stealth-model-quasar-alpha
https://github.blog/changelog/2025-04-14-openai-gpt-4-1-now-available-in-public-preview-for-github-copilot-and-github-models
https://x.com/cursor_ai/status/
https://x.com/code/status/19118820
智谱 AI 推出了新的单字母域名 z.ai,并上线了面向开发者的聊天界面 chat.z.ai,用户可以在该界面体验新发布的 GLM-4-0414 系列和 GLM-Z1 系列的开源模型。模型权重已于 4 月 14 日晚上线。
GLM-4-0414 系列包括 GLM-4-9B-0414、GLM-4-32B-0414。GLM-Z1 系列是基于 GLM-4 基础模型通过冷启动、扩展强化学习及在数学、代码、逻辑等任务上进一步训练开发的,包括 GLM-Z1-9B-0414、GLM-Z1-32B-0414和 GLM-Z1-Rumination-32B-0414(具备“反刍”能力的深度推理模型)。
其中,GLM-Z1-32B-0414 显著提升了数学和复杂任务解决能力。GLM-Z1-Rumination-32B-0414 则能够进行更深、更长时间的思考以解决开放性复杂问题,并在训练中引入了基于真实答案或评分标准进行端到端强化学习,可利用搜索工具处理复杂任务。
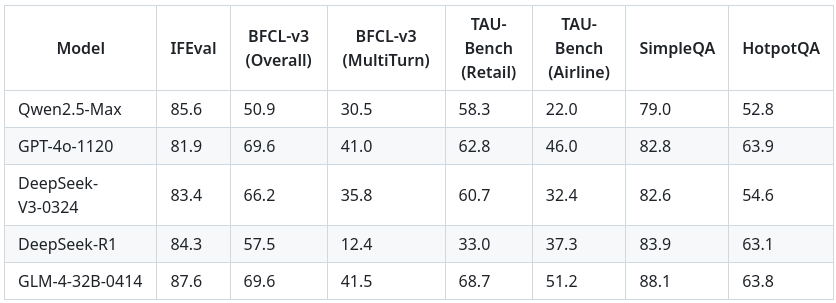
GLM-Z1-9B-0414 在数学推理和通用任务上表现出色,在同尺寸开源模型中性能领先。根据官方提供的基准测试数据,GLM-4-32B-0414 在部分指标上优于 DeepSeek-V3-0324 和 DeepSeek-R1。
目前,glm-z1-flash(应该是对应GLM-Z1-9B-0414)和 glm-4-flash- 模型已在官方 API 上线,并可免费调用。
https://chat.z.ai/
https://huggingface.co/collections/THUDM/glm-4-0414-67f3cbcb34dd9dcb2e
https://github.com/THUDM/GLM-4
DeepSeek AI 宣布计划将其内部使用的推理引擎贡献给开源社区。
该引擎基于一年多前 vLLM 的早期分支开发,并针对 DeepSeek 模型进行了大量定制优化。DeepSeek 表示,由于其引擎与内部基础设施(如集群管理工具)紧密耦合,且团队维护资源有限,直接完全开源整个引擎存在挑战。因此,他们决定采取与现有开源项目(如 vLLM)紧密合作的方式,逐步提取独立的、可重用的功能模块作为独立库进行贡献,并直接分享设计改进和实现细节。
DeepSeek 强调此举仅针对推理引擎代码库的开源方式,未来模型发布仍将保持开放合作态度,并致力于在新模型发布前同步推理相关的工程工作,以确保社区从第一天起就能获得最先进的支持。

https://github.com/deepseek-ai/open-infra-index/blob/main/OpenSourcing_DeepSeek_Inference_Engine/README.md
为配合 GPT-4.1 的发布,OpenAI 更新了其 Prompting Cookbook,提供了针对新模型的 Prompt 指南。该指南强调 GPT-4.1 非常适合构建自主(Agentic)工作流,并在模型训练中强调了多样化的问题解决路径。
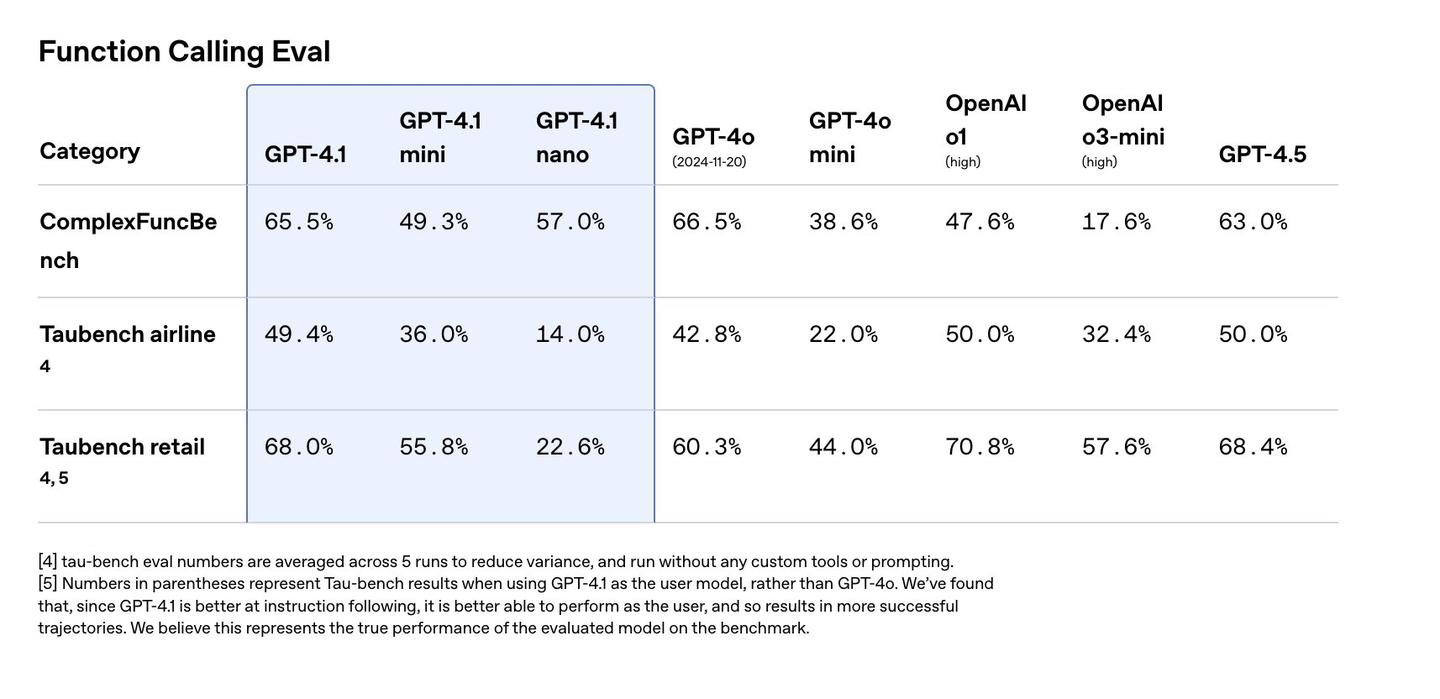
为了充分利用 GPT-4.1 的自主能力,指南建议在所有 Agent Prompt 中包含三类关键提醒:1. 持久性(Persistence):确保模型理解其处于多轮对话中,不会过早结束。2. 工具调用(Tool-calling):鼓励模型充分利用工具,减少幻觉。3. 规划(Planning,可选):促使模型在每次工具调用前明确规划并在文本中反思,而非仅连续调用工具。OpenAI 称,这三条指令将模型从聊天机器人状态转变为更“积极”的 Agent,自主推动交互,其内部 SWE-bench 验证分数因此提高了近 20%。
在工具调用方面,指南强烈建议开发者使用 OpenAI API 请求中的 tools 字段传递工具,而非手动注入描述或编写单独的解析器,并指出使用 API 解析的工具描述比手动注入 schema 使 SWE-bench 通过率提高了 2%。开发者应清晰命名工具并提供详细描述,复杂工具的示例应放在系统提示的 # Examples 部分。对于 Prompt 诱导规划与思维链,指南指出 GPT-4.1 不是推理模型(不产生内部思维链),但可通过 Prompt 诱导其“大声思考”(Thinking out loud),进行显式分步规划,这在 SWE-bench 实验中将通过率提高了 4%。
指南还提到,在长上下文使用中,指令和上下文的位置会影响性能,建议将指令放在上下文的开头和结尾;若只放一次,则放在上下文之前优于之后。此外,建议使用 XML 风格的分隔符(类似 Anthropic 对 Claude 的建议),并开源了一种模型经过广泛训练的推荐文件 diff 格式及其应用方法。
谷歌近期也发了一个很多页的Prompt指南。
https://cookbook.openai.com/examples/gpt4-1_prompting_guide
https://q9yxq74um5.app.yourware.so/
OpenAI 在 Hugging Face 上发布了名为 MRCR (Multi-round co-reference resolution) 的数据集,这是一个用于基准测试大型语言模型(LLM)在长文本中区分多个隐藏“针”(Needles)的能力的数据集。
该评估受到 Gemini 首次引入的 MRCR 评估的启发,但 OpenAI MRCR 扩展了任务难度并提供了开源数据。任务要求模型处理一段长、多轮、合成的用户与模型对话。评估指标使用 Python difflib.SequenceMatcher 的比率。模型需在答案前添加指定的字母数字哈希,否则匹配率为 0。
数据包含 438 个不同实体和 10 种写作格式,每个 Token 长度区间(bin)有 100 个样本,区间边界从 4096 到 1,048,576 Tokens 不等。OpenAI 在其 GPT-4.1 发布博客中展示了该基准测试的完整结果。Hugging Face 数据集页面提供了运行和评分此任务的 Python 代码片段。https://huggingface.co/datasets/openai/mrcr
英伟达(Nvidia)宣布承诺投入 5000 亿美元用于在美国建设人工智能基础设施。该计划的一部分是将超级计算机的生产引入德克萨斯州。英伟达还表示,已委托在亚利桑那州和德克萨斯州建设超过一百万平方英尺的制造空间,用于生产和测试 AI 芯片,旨在将部分生产转移到美国。其 Blackwell 芯片的生产已在台积电(TSMC)的工厂开始。
据 The Information 报道及社交媒体讨论,OpenAI 即将发布新的推理模型 o3 和 o4-mini。据称,这些模型首次具备独立发展新科学想法的能力,能够同时处理来自不同专业领域的知识,并在此基础上提出创新的实验方案。
早期测试者反馈,阿贡国家实验室的科学家使用这些模型的早期版本,将设计复杂实验的时间从几天缩短到几小时。OpenAI 计划对这些高级服务收取高达每月 2 万美元的费用。报道推测,当这些推理模型与能够控制模拟器或机器人以直接测试和验证生成假设的 AI Agent 结合时,可能会极大地加速科学发现过程。这些模型有望吸引财富 500 强客户,如石油天然气公司和商业药物开发商等。
https://www.theinformation.com/articles/openais-latest-breakthrough-ai-comes-new-ideashttps://x.com/kimmonismus/status/
Meta 公司宣布,将开始在欧盟地区使用公开内容(如 Facebook 和 Instagram 上的帖子、评论)来训练其人工智能模型。此前,由于数据隐私方面的监管压力,Meta 曾暂停了这一计划。Meta 表示将从 2025 年 4 月 15 日开始训练其 AI 模型。https://techcrunch.com/2025/04/14/meta-to-start-training-its-ai-models-on-public-content-in-the-eu/
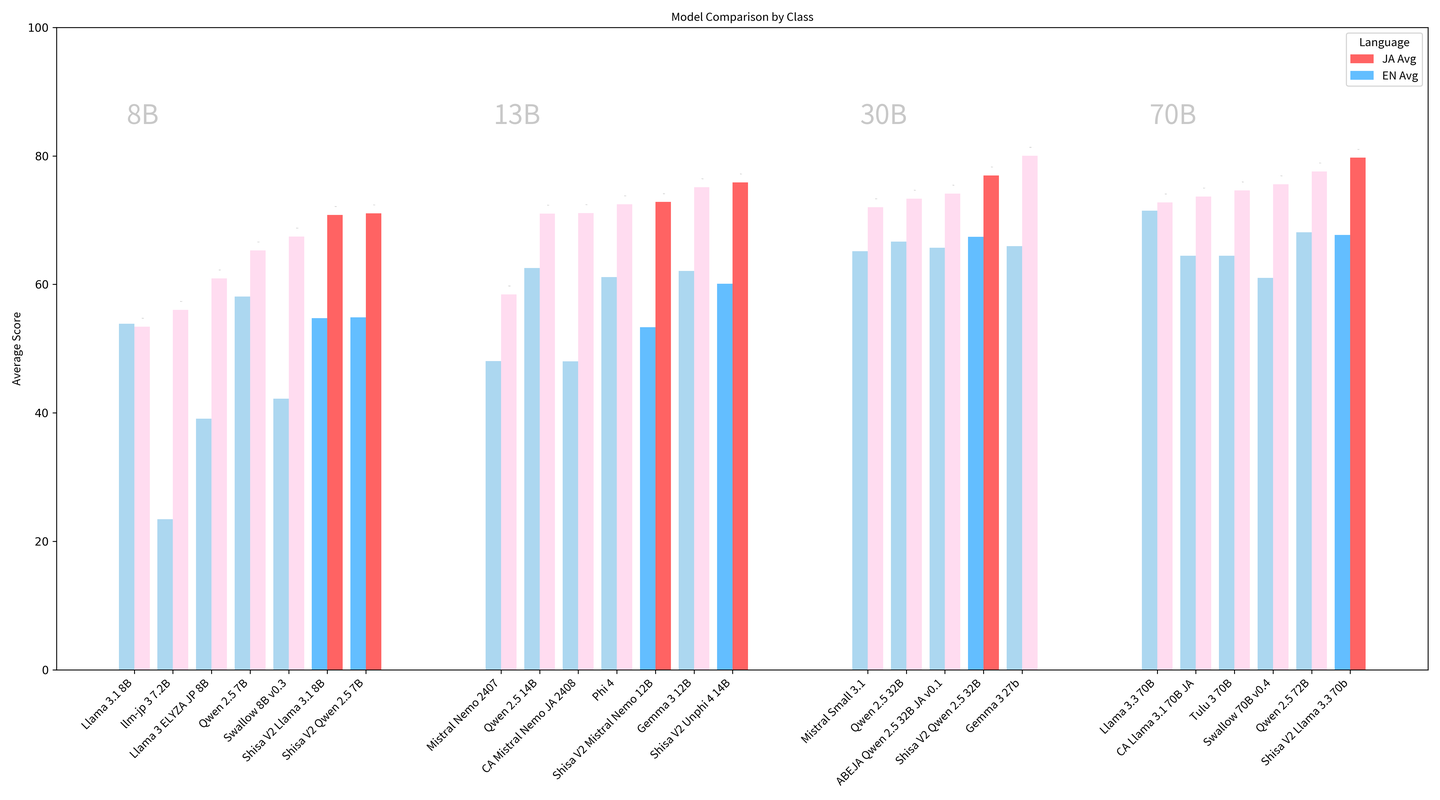
Shisa AI 发布了新一代日英双语模型 Shisa V2 系列。该系列基于多个现有优秀模型(包括 Qwen2.5 7B/32B, Llama 3.1 8B, Mistral Nemo 12B, Unphi4 14B, Llama 3.3 70B)进行微调,旨在提升日语处理能力,同时保持或提升英语性能。
根据提供的基准测试结果(JA AVG 和 EN AVG),Shisa V2 模型在其各自的参数规模级别中接近或达到了 SOTA 水平。团队还开发了三个新的日语评估基准:shisa-jp-ifeval(高级指令遵循)、shisa-jp-rp-bench(角色扮演和多轮对话)、shisa-jp-tl-bench(日英翻译),并计划很快开源这些基准。所有 Shisa V2 模型均已在 Hugging Face 上发布,包含不同参数量、上下文长度和许可证的模型。
https://shisa.ai/posts/shisa-v2/
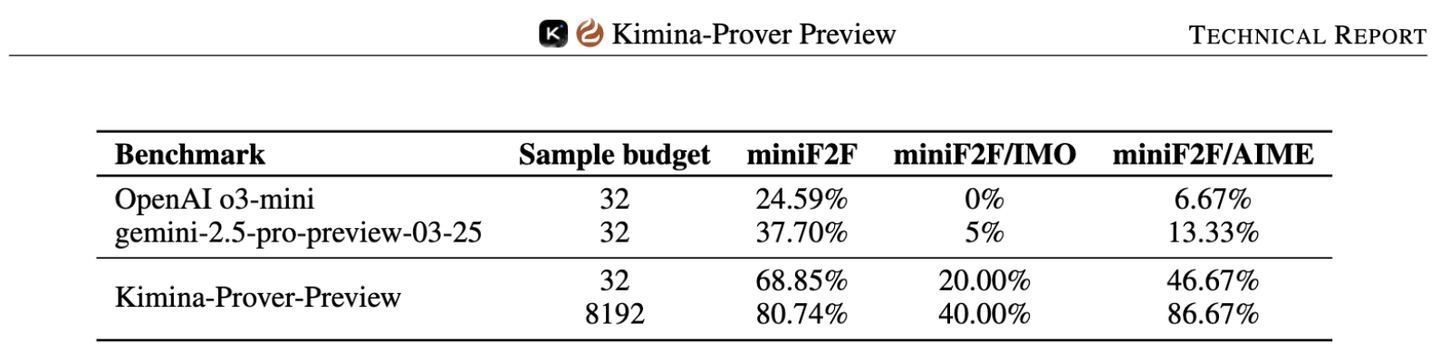
Moonshot AI(月之暗面)与 Numina 合作发布了 Kimina-Prover Preview 模型系列。该系列旨在结合推理模型(类似 o1/r1 风格)与形式化数学(Lean 4),并通过强化学习生成人类可读的证明。
Kimina-Prover 在 miniF2F 定理证明基准上达到了 80.7% 的新 SOTA(State-of-the-Art)水平。团队公开了蒸馏后的 Kimina-Prover 1.5B 和 7B 模型,可在 Hugging Face 上获取。技术报告和模型链接已提供。报告中展示了 Kimina-Prover 找到的 IMO 1968 P5(第一部分)问题的解。
https://huggingface.co/collections/AI-MO/kimina-prover-preview-67fb536b883d60e7ca25d7f9
https://github.com/MoonshotAI/Kimina-Prover-Preview
字节跳动发布了名为 Seaweed-7B(全称 Seed-Video)的 AI 视频生成基础模型。这是一个约 70 亿参数的 Diffusion Transformer 模型,据称训练计算量相当于 1000 块 H100 GPU 小时(约 66.5 万 H100 GPU 小时)。
该模型通过学习海量多模态数据(视频、图像、文本)来构建世界表征,能够根据文本描述生成不同分辨率、宽高比和时长的视频。Seaweed-7B 支持多种下游应用,包括图像到视频生成、人体视频生成、主题一致视频生成、视频音频联合生成、长视频生成与叙事、实时生成、超分辨率生成以及相机控制生成。项目页面和技术报告已发布,但模型权重尚未公开。

谷歌 DeepMind 宣布推出了一款名为 DolphinGemma 的 AI 模型,旨在帮助破译海豚的发声,以支持研究人员更好地理解海豚的交流方式。
该模型基于谷歌的 Gemma 模型家族,并使用来自非营利组织 Wild Dolphin Project (WDP) 多年积累的大西洋斑点海豚声音数据进行了微调。
DolphinGemma 模型能够学习海豚的声音模式,并预测它们接下来可能发出的声音。该模型参数量约为 4 亿,足够小,可以直接在用于海洋研究的 Pixel 9 手机上运行。谷歌 CEO Sundar Pichai 认为这是实现跨物种交流方面迈出的很酷一步。

https://blog.google/technology/ai/dolphingemma/
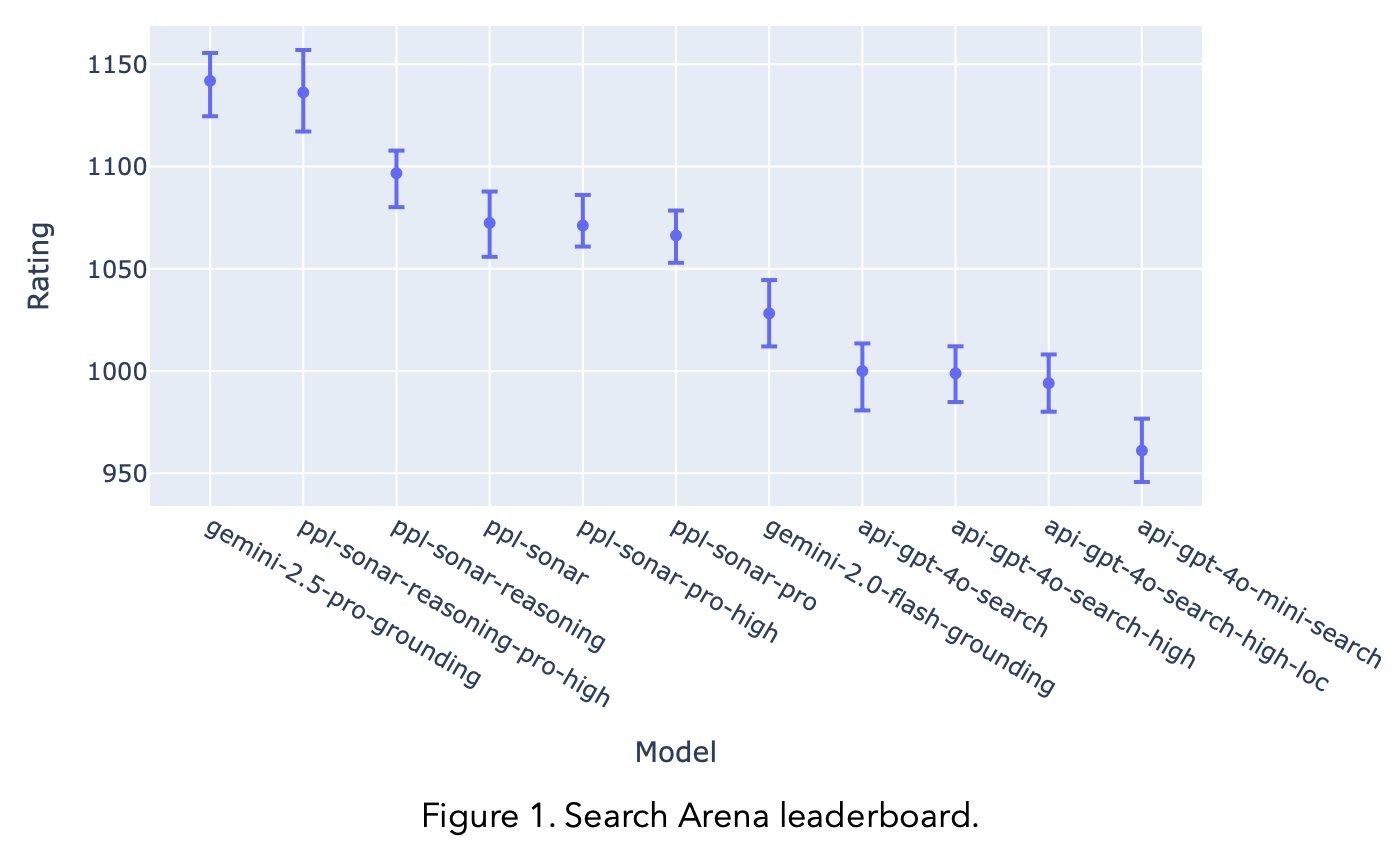
LMArena.ai(原 http://lmsys.org)发布了其 Search Arena 的排行榜结果。结果显示,Google AI 的 Gemini-2.5-Pro-Grounding 和 Perplexity AI 的 Perplexity-Sonar-Reasoning-Pro 模型在榜单上名列前茅。团队指出,推理模型在该榜单表现良好。LMArena 已开源了 7000 次包含用户投票的对战数据,并发布了详细的分析博客文章。
Kling AI 宣布其 2.0 版本将于 2025 年 4 月 15 日发布,届时将带来将创意变为屏幕内容的新方式。全球发布直播将于格林威治时间 4 月 15 日上午 6:00 开始,对应北京时间下午 2:00,洛杉矶时间 4 月 14 日晚上 11:00,伦敦时间上午 7:00,东京时间下午 3:00。

https://x.com/Kling_ai/status/1
MinMax(稀宇科技)发布了其官方的 MiniMax Completion Protocol (MCP),允许开发者通过 API 调用其多种 AI 能力,包括视频生成、图像生成、语音生成和声音克隆等。官方提供了 GitHub 仓库包含相关代码和说明。有用户测试表示声音和图像生成功能可用,但视频生成功能似乎尚未开放或存在问题。
英伟达在 Hugging Face 上发布了三款新的 Nemotron-H 系列基础模型,均具有 8K 上下文长度。这些模型包括 Nemotron-H-56B-Base-8K、Nemotron-H-47B-Base-8K 和 Nemotron-H-8B-Base-8K。仅供学习研究。https://huggingface.co/collections/nvidia/nemotron-h-67fd3d7ca332cdf1eb5a24bb
微软发布了 MineWorld,这是一个基于 Minecraft 的实时、开源的交互式世界模型。该项目已在 Hugging Face 上线。相关视频展示了其在 Minecraft 环境中的交互能力。https://huggingface.co/microsoft/mineworld
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/265349.html原文链接:https://javaforall.net


