
模型能力上,deepseek大于豆包大于文心一言,其中文心一言模型能力至少差他们两档,绝大多数情况下都可以退出比较了
多模态能力上,豆包远大于deepseek,deepseek就不是多模态模型,识图之类的能力注定比不了
联网能力上,豆包略强于deepseek,毕竟豆包还能整合抖音的知识
思维链能力(这个我认为要加上,可以查看思维过程是一个一些情况下很有竞争力的东西)deepseek远大于豆包,毕竟豆包也没有思维链
还有就是豆包的数据一般会比deepseek更新,整合了一些联动抖音的功能之类。总而言之,抖音深度用户且对模型深度能力不太在意的用豆包,对模型能力要求高的用deepseek
DeepSeek不用说了,用比ChatGTP多得多的成本实现了比肩的模型表现。不然也不能动用美国搞国家安全这一套。在被OpenAI拒绝在外的AMD率先表态接入DeepSeek后,现在英伟达、亚马逊、微软也都接入了。影响力没得说。
豆包和文心一言则还是基于ChatGTP,但豆包的日用体验非常丰富,比如识图,比如充当树洞,比如AI聊天,尤其是最新更新大幅削减了AI语音的机械感,无论是形象还是语音,豆包都一定程度上提供了情绪价值功能。使用也极其方便,微信同样的语音输入,对于不大能接触新事物的老人也能很快上手。
文心一言么,之前用过一段时间感觉就是百度搜索和百度知道的AI版。不过出于对百度长久积累的膈应(百度搜索广告误导、百家号在我达到取款额度前莫名封我号还申诉无效),有其他的就没怎么用。反倒是有时图方便会用百度AI,但也就是使用方便些。找到豆包网页版后还是继续用豆包。
- 低成本处理编程、数据分析等逻辑密集型任务,或者希望本地部署私有化模型,选DeepSeek。
- 问题场景依赖实时数据(如金融资讯)或多模态交互(如语音客服),输出结果偏向娱乐化、营销化,选豆包。
- 业务涉及专业领域知识(如医疗病历分析、法律咨询),偏垂直领域,或者需要与百度生态(如搜索、地图、文库)相关关联,选文心一言。
豆包的杀手锏是实时联网能力与多模态交互。
Doubao-1.5-Pro模型通过“动态知识蒸馏”技术,每10分钟更新一次热点数据库,并整合图像、语音、文本三模态的跨模态对齐网络,实现“边聊边画”的交互体验。
主打日常生活辅助和创意设计,强调趣味性和易用性,支持文本、图像生成及实时数据整合,内置多种娱乐化工具(如绘画、虚拟聊天)。特别是对于语音交互的优化,语音对话延迟低于200ms,接近GPT-4o水平,支持方言识别与情感语调模。
豆包深度集成抖音生态,功能涵盖了聊天、学习、翻译、写论文、画画等多个领域,支持短视频脚本智能生成(含热门BGM推荐)、直播话术优化(实时观众情绪分析)。


它能够根据文本描述生成相应的图像,在语言理解和生成方面也有不错的准确性和流畅性。用户上传图片后,豆包可以生成相关描述或故事,给出恰当的情感交互反馈,极大地丰富了用户的体验。

模型体积压缩至3B参数级,响应速度达0.8秒/次,APP端的界面做得也很像聊天软件,适合移动端高频碎片化交互。

总之,如果娱乐或者艺术创作方面的需求比较多,推荐使用豆包。不过,现阶段部分高级功能需要付费解锁,整体输出AI味道比较重。
当然,有时候AI味道重其实和使用者也有关系。
不少人在使用各类AI大模型的时候,既不了解模型的构造、特性,也不明白应该如何设计合适的提示词来跟AI更好得交互。
再说文心一言,文心一言的核心技术源于百度自研的ERNIE(Enhanced Representation through kNowledge Integration)框架。
ERNIE框架最早于2019年发布,其设计初衷是通过知识增强预训练,提升模型对自然语言的理解和生成能力。
除了学习海量文本数据,还会把百科知识、专业术语等结构化信息融入训练过程,就像给AI装上了知识库,在搜索问题时能更精准把握语句背后的关联信息。
文心一言上线的深度搜索功能,其「推理模型+搜索」直接将复杂问题问答查询拉至专业级。
每次搜索时,它会灵活规划调用代码解释器、高级联网、AI绘图等各种工具,并附带思考和行动过程,最终形成一个高质量多模态输出,有表格、图片、代码的那种。
举个例子,对大火的《哪吒2》,你可以随便将各种你想问的问题一连串发给它:
哪吒2为何如此受欢迎?为什么说敖丙是个橙子?帮我生成一个大橙子漂在海面上的图。就“为什么敖丙一家子颜值都很高,但北海和南海龙王相貌奇怪”做分析
很快它就能完成思考规划,然后分别对每个问题作答,一连串问题一个不漏都能回答对:
经过多次迭代,文心大模型现已升级到4.0 Turbo版本,并从今年4月1日开始对所有用户免费开放。
总结一下就是,文心一言依托百度庞大的知识图谱和数据资源,其RAG能力通过检索外部知识库,特别是中文深度理解和检索,使其在医疗、法律、金融等专业领域的咨询问题得到了极大地加强,更适合专业问题的信息检索。
当然,没有精准的提示词,没有对于包括ChatGPT在内的各类大模型的准确理解,也很难生成你想要的结果。
好了,该轮到大火的DeepSeek了。
目前,国家超算互联网平台、三大运营商平台、各地方政务服务平台以及各大互联网平台都已经接入DeepSeek,足以说明其强大。
那它为什么这么厉害?简单来说有两点:
1、架构方面:DeepSeek使用了一些特别的系统设计,可以理解为让不同擅长领域的“专家”一起来解决问题,并让这些模型能够同时关注多个重要的信息点,提前猜测接下来可能出现的多个情况。
“长链式推理”方式可以帮助模型进行更深入的思考和推理,让处理流程更高效,在整个训练过程中,它主要依靠强化学习,而不像以前那样加入监督微调,减少了训练成本。
2、工程方面:对数据的处理精度进行了调整和优化,采用了“FP8 混合精度”,让数据处理更加高效且准确,在底层通信等方面也做了改进,使得各个部分之间的协作更加顺畅。
这些优化让代码生成速度比之前快了 30%,效率提升了不少。
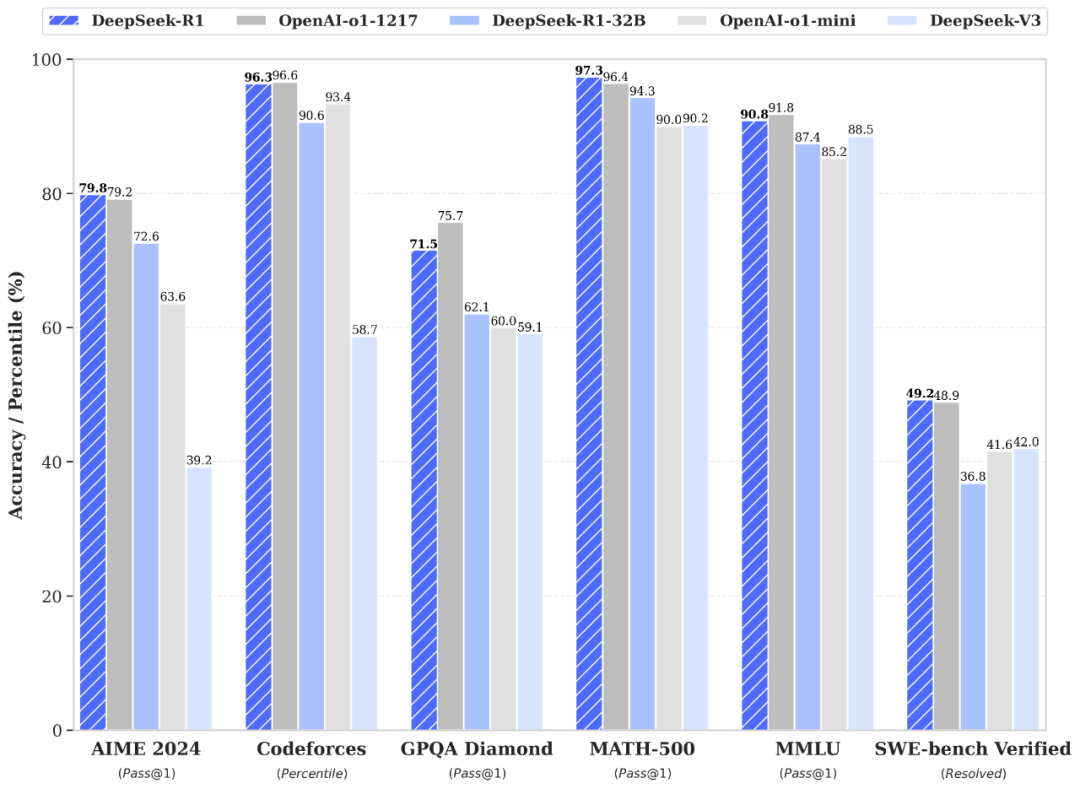
最终的结果就是:DeepSeek-R1模型的训练成本仅为GPT-4的1/20,却能通过“多步推理链”技术解决微积分证明题,甚至在MATH 500测试中正确率超越早期ChatGP。
当然,作为普通用户我们不需过多要理解这些技术。
这里想说的是,这些方法在学术界都已经有了,Deepseek 没有过于追求新技术, 而是花了心思把这些方法都用上了。
重点解决了一些技术的应用难点,在理论应用和工程上找到平衡。(个人觉得算是一种工程应用的创新)
相比其它模型,DeepSeek的各项测评得分都不错,并且用的开发的成本很低。

V3定位为全能型语言模型,擅长多模态任务(文本、图像、音频)和日常语言处理,相比国外模型,V3对中文的理解力更好。
R1则在V3的基础上,完全摒弃监督微调,通过强化学习激发模型自主推理能力,其回答过程是先对用户核心需求进行分析将问题划分步骤,然后调用工具进行搜索思考整理,最后思考完成输出结果。
最适合解决需要逻辑分析和复杂推理的任务,比如技术问题解决、学术研究和金融风控等,尤其擅长数学解题和逻辑分析。
这种将一个复杂问题分解成多个简单步骤,逐步分析并得出结论的思考方式,就是大模型链式思维的核心。
简单来说,大模型链式思维是一种让大语言模型将复杂问题拆解为多个子问题,并按照一定的逻辑顺序依次解决这些子问题,从而形成完整推理链条的方法 ,让模型的决策过程更加透明和可解释。
比如我提出:请帮我结合2024年国家统计局70城的成交数据和近三年这些城市的人口流动数据,预测中国房价未来三年的走势。

 文心一言 ERNIE Bot 教程
文心一言 ERNIE Bot 教程其实,除了以上提到,各种AI工具还在不断涌现,层出不穷。
这不,又出现了AI Agent:Manus,足以说明AI加速改变各行各业已经是很确定的趋势了。
不管是用DeepSeek也好,ChatGPT也罢,很多人都觉得AI工具不好用或者用不好,其实是因为基础没打好,没有系统地去学习相关知识。
我还是那个观点:以后取代人的不是AI,而是会使用AI的另一批人,也只有跟上时代的步伐的人才能享受时代发展的红利。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/265455.html原文链接:https://javaforall.net


