
Moonshot AI(「月之暗面」)在 2025 年 7 月 11 日正式发布并开源了旗下大模型 Kimi K2,并发布技术报告,让我们来快速了解一下。
Kimi K2 是个非推理模型,专注于文本和代码任务,不具备图像处理能力。
- 采用 MoE 架构,拥有总参数约 1T(1 万亿)、激活参数 32B
- 模型上下文 128K
- 词汇表大小 16K
- 模型包含 384 个专家,每个 token 会选择 8 个专家进行计算
- 支持 ToolCalls、JSON Mode、Partial Mode、联网搜索功能等
训练方法:Kimi K2 在预训练阶段使用改进的 MuonClip 优化器替代传统 Adam,成功在 15.5T Token 规模的数据上进行稳定训练,且训练不稳定性为零,解决了万亿参数模型训练中的不稳定(如最大对数值爆炸)问题。
值得一提的是,K2 引入了一套大规模 Agentic 任务数据合成和强化学习训练流程:通过模拟数百个领域的工具((包括真实的 MCP 工具和合成工具))使用场景生成海量高质量训练数据,并让模型充当自己的评判员(自我反馈机制)进行通用强化学习。这些创新使 K2 在知识推理、数学和编程等任务上具备了出色的泛化能力和自主决策能力。
Kimi K2 系列提供两个主要版本:
- Kimi-K2-Base:基础模型,适合需要进行深度微调和定制化解决方案的研究者和开发者。
- Kimi-K2-Instruct:指令微调模型,适用于通用的聊天和智能体应用场景,无需长时间思考即可快速响应。
从各个评测集的结果来看,其 agent 能力 和编码能力与 Anthropic 的 Claude4 模型差距很小,而数学解题能力则优于 Claude 4 模型。
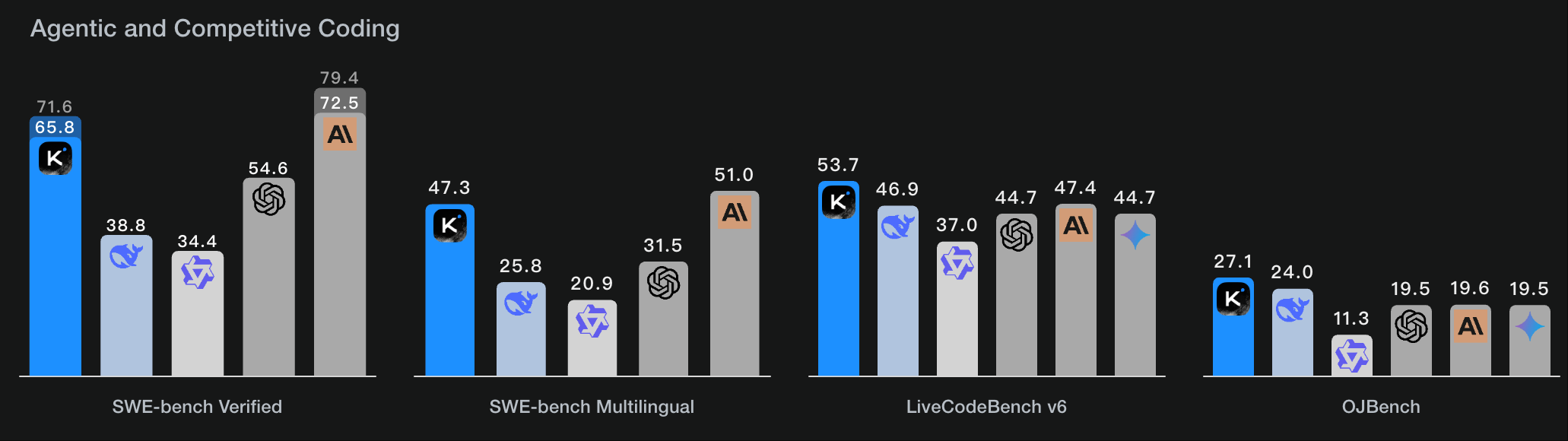

SWE-Bench 是一个用于评估大语言模型在真实软件工程任务中执行自动代码修复能力的评测集,仅限 Python语言。
SWE-bench verified 是 SWE-bench 的一个经过严格人工验证的子集,也仅限 Python语言。
SWE-bench Multilingual 是SWE-bench 的扩展,扩展至多种主流编程语言(Python、Java、JavaScript、C++、Go、Rust、Ruby、TypeScript),评估跨语言的代码的修复能力。
LiveCodeBench 是一个为应对评测数据污染问题而设计的“活”基准。问题来源主要是LeetCode, AtCoder, CodeForces 等平台的近期新题目。
OJBenchOJBench 如同代码能力的“奥数竞赛”,问题来源主要是IOI, ICPC 等顶级、高难度的经典算法竞赛题。
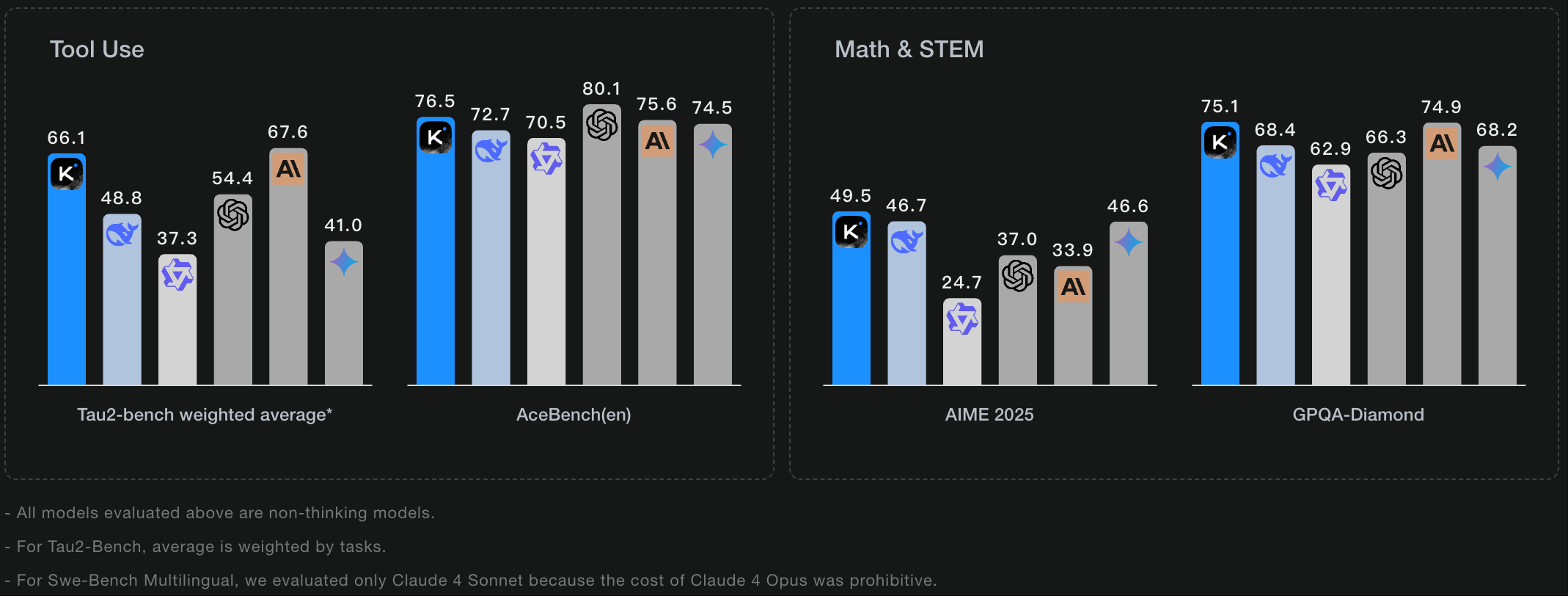
Tau2-bench(全称 τ²-bench)是一个旨在评估对话式 AI 智能体(Conversational AI Agent)在“双控制(Dual月之暗面 Kimi 教程-Control)”环境下表现的先进评测基准。它与传统评测最大的不同在于,模拟了现实世界中人与 AI 共同协作解决问题的复杂场景。在这种设定下,不仅 AI 智能体可以使用工具(如调用 API 查询信息、修改后台设置),人类用户(或模拟用户)也可以使用自己的一套工具(如重启设备、检查本地状态)。这种环境要求模型不仅要会“做事”,更要会“协作”。
AceBench(en) 是一个专注于全面评估大型语言模型工具使用(Tool Usage)或函数调用(Function Calling)能力的评测基准。它旨在解决过往评测集场景单一、维度片面等问题,提供一个更综合、更细粒度的考核框架。
GPQA 包含 448 道来自真实研究生物理考试和教材的问答题,覆盖力学、电磁学、量子、热统、相对论等领域。它用于评测模型在高阶物理概念理解、推导能力和严谨推理方面的专家级水平。
AIME25 收录的是 2025 年 AIME 数学竞赛的原题,共 15 道中等到高难度的整数答案题。评测重点是大模型的中学奥数解题能力、代数与组合推理、精准计算与逻辑推导。
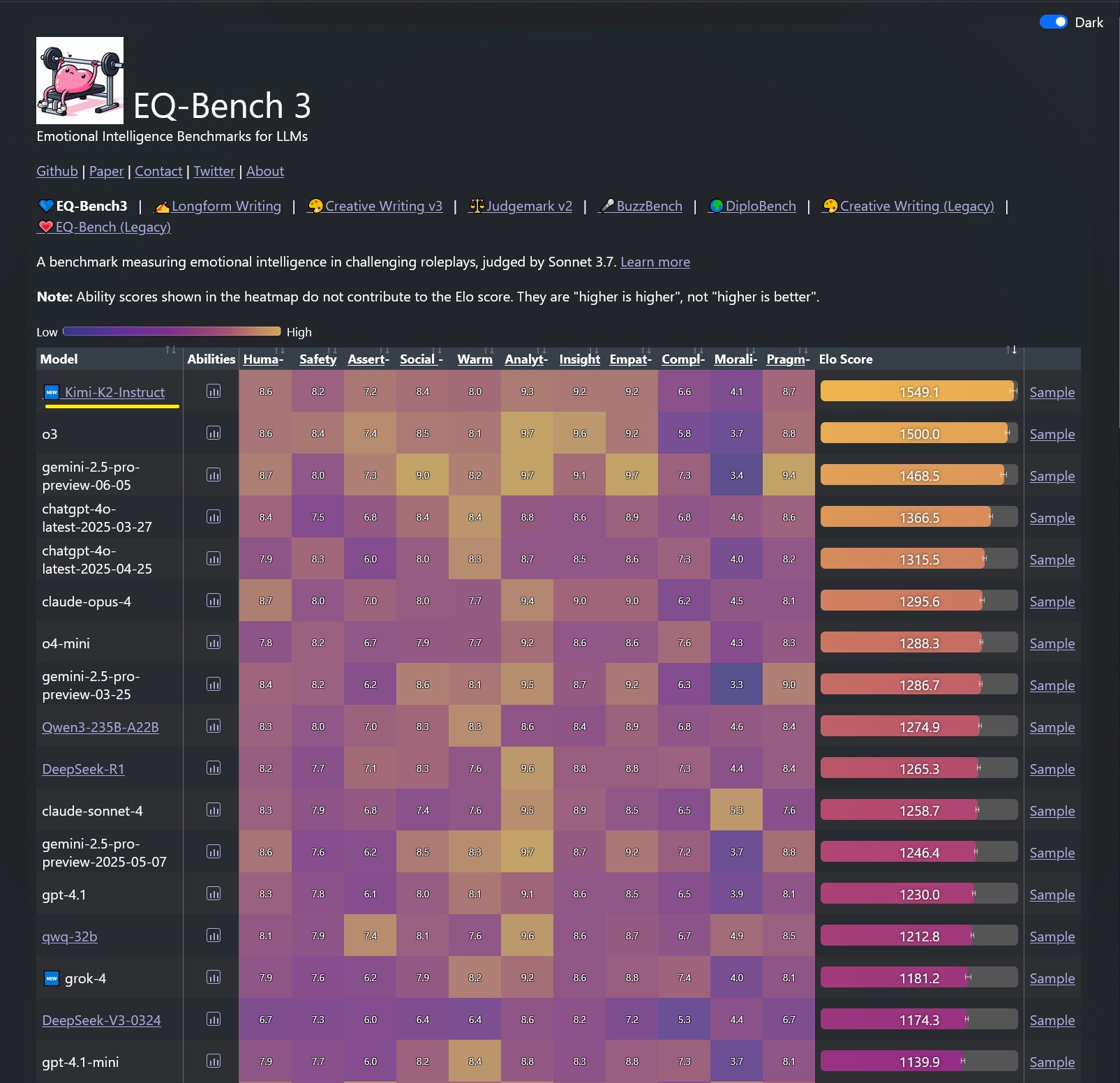
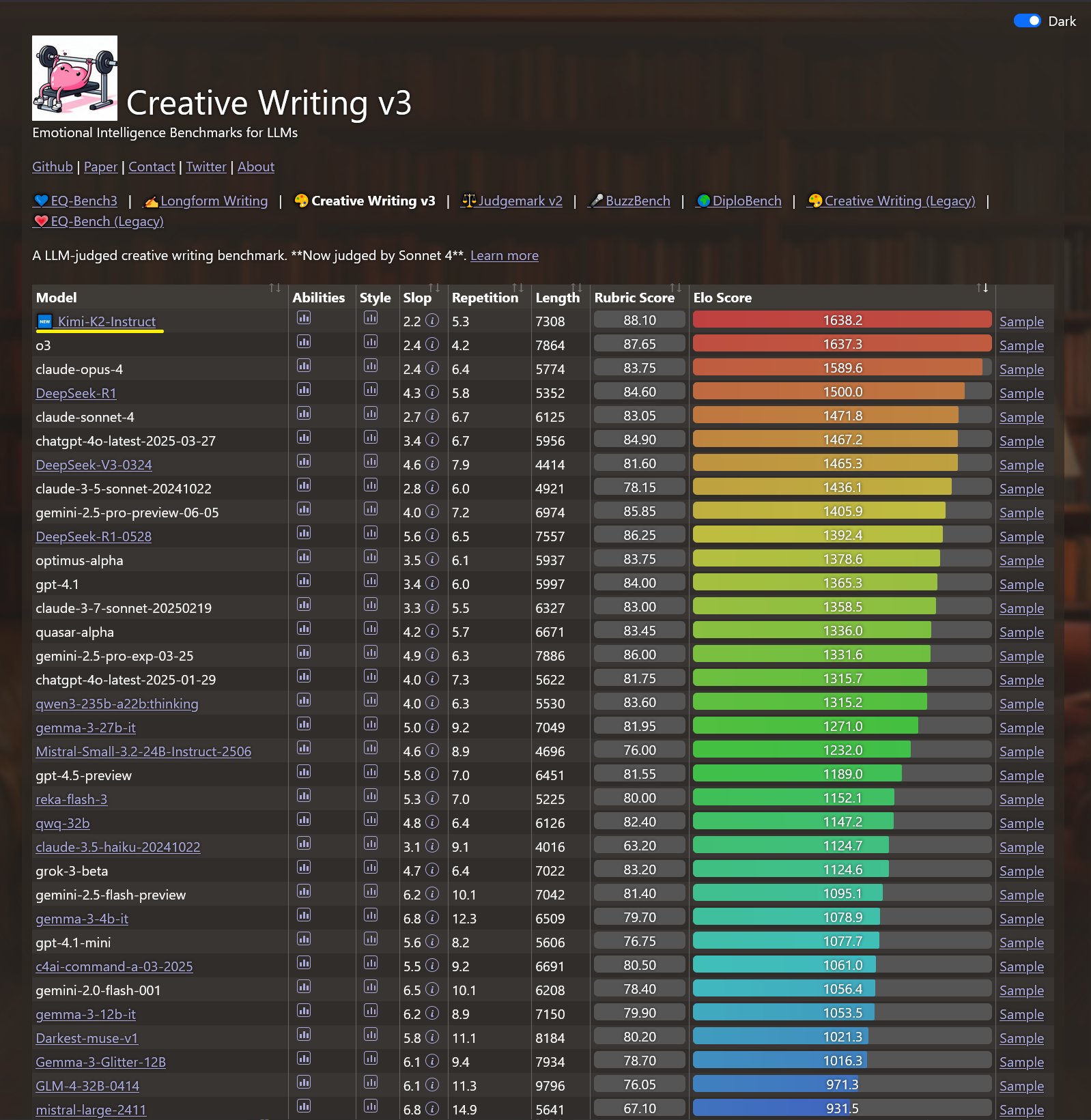
在 Kimi K2 发布不久后,各大模型评测榜单都会陆续更新。昨天刚刚更新的榜单中,Kimi K2 登顶了 EQ-Bench3 和 Creative Writing v3 这两个评测集。其中,EQ-Bench3 是用来测试 LLM 情商的基准测试,Creative Writing v3 是用来测试 LLM 创意性写作能力的基准测试。
Kimi K2 开源消息发布后,在开发者社区引发极大关注。GitHub 仓库上线短时间内即收获了数千星标(当前超过 3.4K stars)。Hugging Face 模型页数据显示,发布 20 分钟内下载量已近 1.5 万次。
Perplexity CEO Aravind Srinivas 在 X 平台公开评价 K2 在其内部测试中表现惊艳,并表示将“很快启动对 K2 的后续微调训练”。有国内开发者将 K2 比作“代码领域的 DeepSeek 时刻”,认为它有望成为 Claude 4 Sonnet(Anthropic 的代码专长模型)等闭源模型的有力开源平替(价格仅为其六分之一)。
如果想要体验 Kimi K2 有以下几种方法:
- 直接去 Kimi 的官网 体验,现在默认的模型已经由 K1.5 升至 K2 了。
- 如果你想基于 Kimi K2 做一些开发,可以去月之暗面的开发者后台 建一个 key,Kimi K2 的 API 接口兼容了 OpenAI 的 chat completion 接口,很容易就可以接入完成。
- 如果你不想充值也想接入 API,你可以去 OpenRouter 接入,目前提供了免费的量,只要不是太大量的调用,基本是够用的,模型名称为:moonshotai/kimi-k2:free。
- 如果你在用 Claude Code,又觉得比较贵,你可以用 Kimi K2 来替换,方法是在 shell 中输入以下命令,下面的 key 去月之暗面开发者后台去闯进。注意,如果你接入 api 之后报错,应该是账户余额里的钱不够,至少充值 50 元才可以。
可能很多人有疑问为什么更改以上两个变量,没有指定模型 Claude Code 默认使用的就是 Kimi K2 呢?其实原因是 Kimi 为了让大家体验 K2 Agent 的能力,做了一个中转服务,这个 base url 下不管指定什么模型都无所谓,底层会自动转发到 Kimi K2 模型上,官方文档戳这里,从教程中可以看到,除了 Claude Code 之外,Cline 和 RooCode 也可以这么做。
当前的模型存在以下几点限制:
- K2 模型体积庞大,本地部署门槛很高(需要数十张高端 GPU 或云端算力)
- 在处理硬核推理任务或工具定义不明确的情况下,模型可能会生成过多的令牌,有时会导致输出被截断或工具调用不完整。
- 如果启用工具使用,某些任务的性能可能会下降。
- 在构建完整软件项目时,与在代理式框架下使用 K2 相比,一次性提示会造成性能下降。
对于 Kimi K2 的下一步计划,Kimi 团队也在技术报告指出为了实现通用 Agent,对模型增加深度思考能力以及视觉理解能力是接下来的重点。这两个能力对 Kimi 团队来说应该不难,只是时间问题导致没来得及整合到 K2 中。了解 Kimi 的人都知道,他们早前推出的 K1.5(多模态模型)和 kimi-thinking-preview(多模态思考模型)已经具备视觉处理和深度推理的能力。
受到 DeepSeek 年初火爆全球的压力后,Kimi 也逐步由闭源转为开源,国内开源目前三把大旗:DeepSeek、Qwen 和 Kimi。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/265561.html原文链接:https://javaforall.net


