
智谱AI(ZhipuAI)在8月11日发布了其最新的旗舰多模态模型——GLM-4.5V。该模型在继承前代技术优势的基础上,实现了性能的全面跃升,不仅在多个基准测试中取得顶尖成绩,更在处理真实世界复杂任务方面展现了卓越的实用性。
代码:https://github.com/zai-org/GLM-V


模型:https://huggingface.co/zai-org/GLM-4.5V
Demo:Free AI Chatbot powered by GLM-4.5
GLM-4.5V的强大能力源于其先进的底层架构和训练方法。
- 旗舰语言模型基座: 模型基于智谱AI下一代文本旗舰模型GLM-4.5-Air构建。GLM-4.5-Air采用专家混合(MoE)架构,总参数量达到106B,而在推理时仅激活12B参数,实现了强大性能与高效推理的平衡。
- 技术路线传承: GLM-4.5V延续了在GLM-4.1V-Thinking模型中被验证有效的技术路线,该路线强调通过强化学习等方法提升模型的复杂推理能力。
- 高分辨率与长上下文: 模型支持高达4K分辨率的图像输入,并且能够处理任意长宽比的图片,这对于理解高细节图像和非标准尺寸视觉材料至关重要。同时,它还支持64k的长上下文处理。
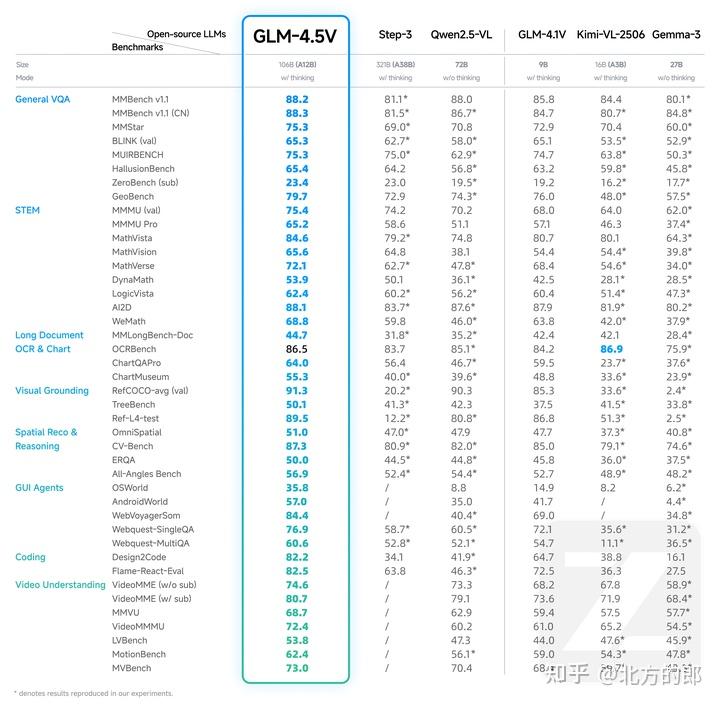
GLM-4.5V在多达42个公开的视觉语言基准测试中,取得了同等规模模型中的最佳性能(SOTA)。其性能不仅体现在综合得分上,更在多个关键能力维度上超越了现有模型。其强大的效率和性能也体现在其家族系列中:其前身、参数量仅为9B的GLM-4.1V-Thinking模型,在18项基准测试中的表现便足以媲美甚至超越参数量高达72B的Qwen-2.5-VL模型,展示了该系列架构卓越的性能效率。
GLM-4.5V专注于解决现实世界中的复杂应用问题,其功能覆盖了从基础理到高级交互的多个层面。
- 全方位多模态理解:
- 图像与视频: 能够处理复杂的单图或多图推理任务,如场景理解、空间关系识别等。在视频处理方面,支持长视频的智能分割和关键事件识别。模型单次输入最多可支持1个视频或300张图片。
- 复杂图表与长文档: 具备强大的文档解析能力,可以像人类专家一样分析研究报告、财务报表等复杂文档,并从中提取关键信息。
- 精准视觉定位(Grounding):
这是GLM-4.5V的一项特色功能。当模型在回答中提及图像的特定区域时,它可以使用特殊标记符<|begin_of_box|>和<|end_of_box|>将该区域的坐标包含在内。坐标格式为[x1, y1, x2, y2],分别代表目标左上角和右下角的相对坐标(基于0到1000的图像尺寸归一化),实现了语言描述与视觉元素的精确对应。 - GUI智能体(GUI Agent):
模型可以作为强大的GUI智能体核心,用于自动化桌面或移动设备操作。它能够准确识别屏幕上的图标和控件,理解操作指令,辅助用户完成点击、输入等一系列任务,为实现更高级的人机交互应用提供了可能。
为了应对不同复杂度的任务,GLM-4.5V引入了在GLM-4.5文本模型中备受好评的“思维模式”(Thinking Mode)开关。
- 工作原理: 在处理复杂问题时,模型会首先在内部生成一段“思考链”(Chain of Thought),这段内容被包裹在<think>…</think>标签内。这个过程模拟了人类的结构化思考,帮助模型分解问题、进行逻辑推理,从而给出更准确、更全面的最终答案。
- 应用价值: 用户可以根据任务需求选择是否启用此模式。对于简单、追求快速响应的场景,可以关闭该模式;而对于需要深度分析和推理的复杂任务,启用该模式则能显著提升回答的质量和可靠性。
开发者可以通过transformers库轻松调用GLM-4.5V。
1. 环境安装
请确保安装特定版本的transformers库:
pip install transformers-v4.55.0-GLM-4.5V-preview2. Python代码示例
以下代码演示了如何加载模型并进行一次简单的图文对话。
from transformers import AutoProcessor, Glm4vMoeForConditionalGeneration import torch MODEL_PATH = "zai-org/GLM-4.5V" messages = [ { "role": "user", "content": [ { "type": "image", "url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png" }, { "type": "text", "text": "describe this image" } ], } ] processor = AutoProcessor.from_pretrained(MODEL_PATH) model = Glm4vMoeForConditionalGeneration.from_pretrained( pretrained_model_name_or_path=MODEL_PATH, torch_dtype="auto", device_map="auto", ) inputs = processor.apply_chat_template( messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt" ).to(model.device) inputs.pop("token_type_ids", None) generated_ids = model.generate(inputs, max_new_tokens=8192) output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False) print(output_text)GLM-4.5V模型的权重文件遵循MIT许可证,代码部分则在Apache 2.0许可证下开放,为学术研究和商业应用提供了极大的灵活性。智谱AI鼓励社区开发者共同探索模型前沿,打造更多创新应用。
在z.ai上选择GLM-4.5V即可进行测试

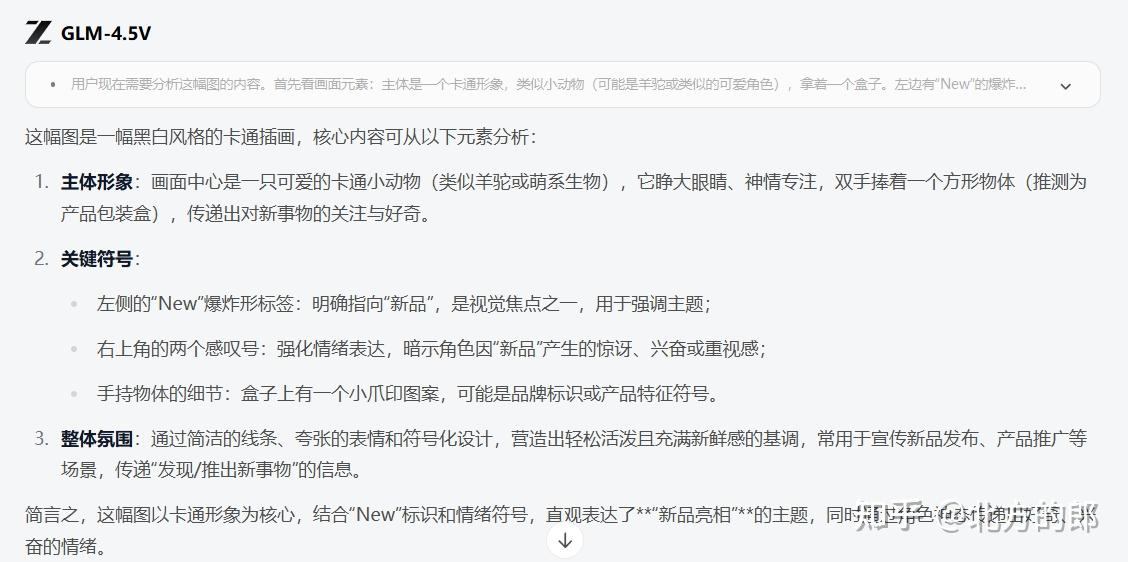
Prompt:请分析这张图

Prompt:请分析这张图的内容
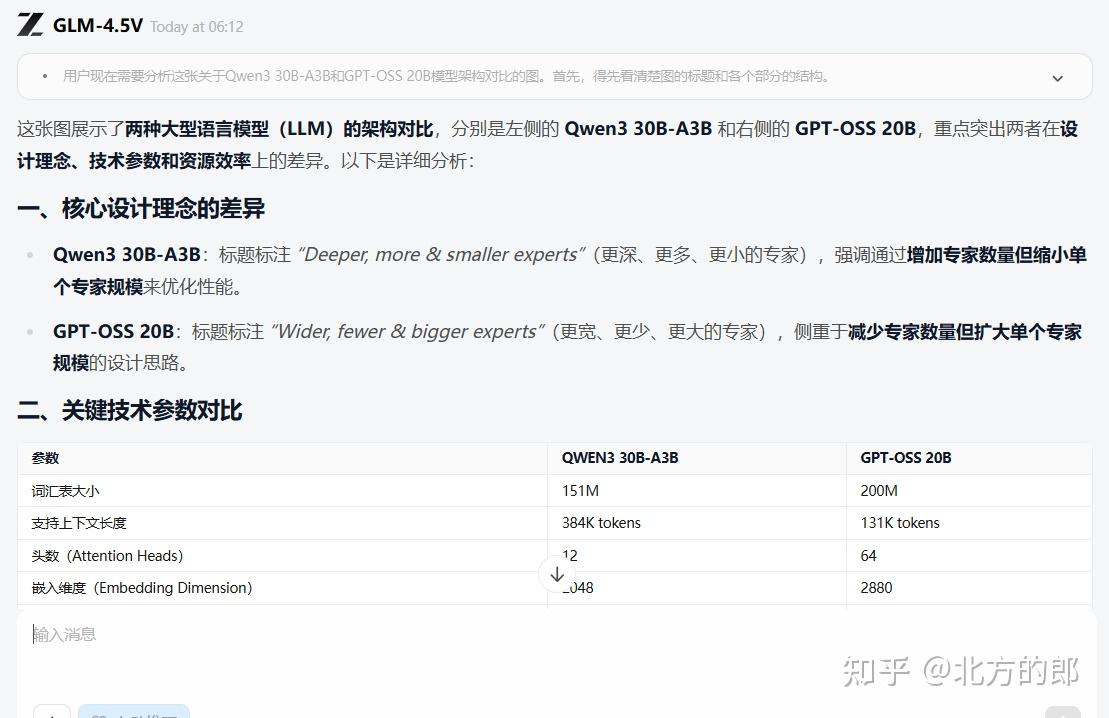

分析的非常精彩。
Prompt:猜猜这是哪里并返回经纬度,请在得出结论之后用json格式输出:大洲-国家-省份/州-市-地点-经度-纬度,键名为:’continent’, ‘country’, ‘state’, ‘city’, ‘place_name’, ‘lat’, ‘lng’。


——完——
@北方的郎 · 专注模型与代码
喜欢的朋友,欢迎赞同、关注、分享三连 ^O^
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/266295.html原文链接:https://javaforall.net


