
在人工智能的浪潮之巅,大型语言模型(LLM)正经历一场深刻的蜕变——从博学的“知识库”演变为能够解决复杂问题的“思考者”和“执行者”。这场变革的核心,在于模型能否统一掌握三大关键能力:与物理和数字世界交互的智能体(Agentic)能力、解决多步骤数理难题的复杂推理(Reasoning)能力,以及应对真实世界软件工程挑战的高级编码(Coding)能力。正是在这一背景下,智谱AI(Zhipu AI)与清华大学的研究团队推出了他们的最新力作——GLM-4.5,一个旨在统一并精通这三大核心能力(论文中合称为ARC)的开源基础模型。这篇于2025年8月发布的论文,不仅展示了GLM-4.5媲美甚至超越部分顶级闭源模型的惊人实力,更详细揭示了其背后复杂而精密的训练方法论。
论文:https://www.arxiv.org/abs/2508.06471
研究团队开宗明义地指出,尽管业界已有多款模型在单一领域(如数学推理或代码修复)表现出色,但能同时驾驭智能体、推理、代码三大领域的强大开源模型仍然缺位。GLM-4.5的诞生正是为了填补这一空白。
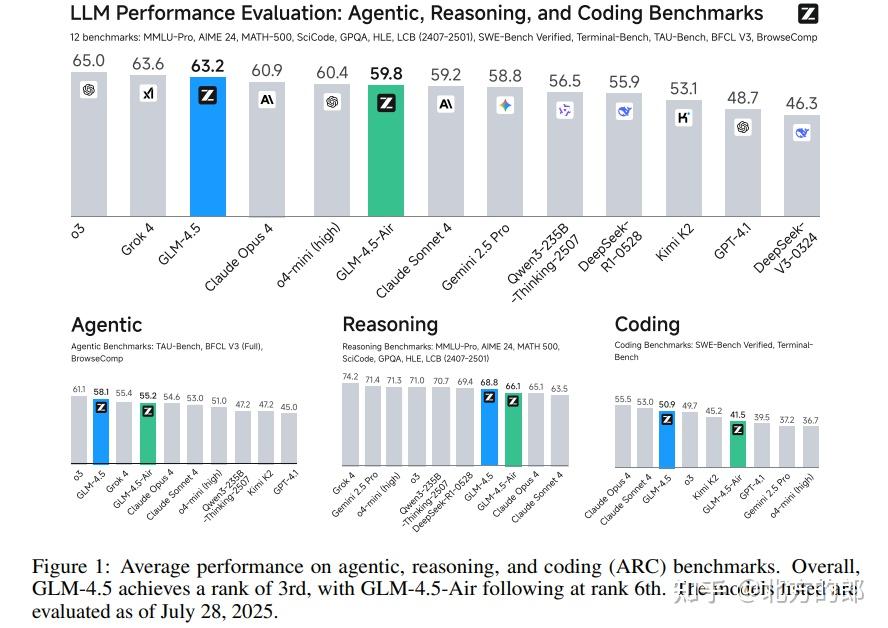

论文摘要中的关键数据显示,GLM-4.5在多个权威基准测试中取得了强劲表现:
- 在智能体基准 TAU-Bench 上得分 70.1%。
- 在数学推理基准 AIME 24 上得分 91.0%。
- 在代码基准 SWE-bench Verified 上得分 64.2%。
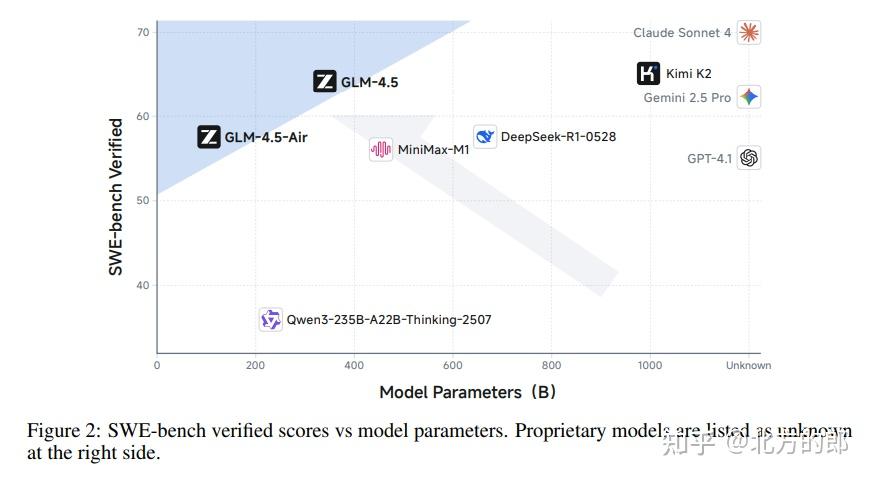
综合12项ARC基准测试的平均性能,GLM-4.5在所有受评模型中总排名第三,在智能体任务上排名第二。尤为值得一提的是,它以远少于部分竞争者的参数量实现了这一成就。团队同时发布了拥有355B参数的GLM-4.5和其106B参数的紧凑版GLM-4.5-Air,并开源了模型权重和代码,旨在推动整个社区在高级AI系统方面的研究进展。
强大的性能源于坚实的基础。GLM-4.5的预训练过程分为架构设计、数据处理、中期训练和超参数设置四个方面,每一步都经过精心设计。
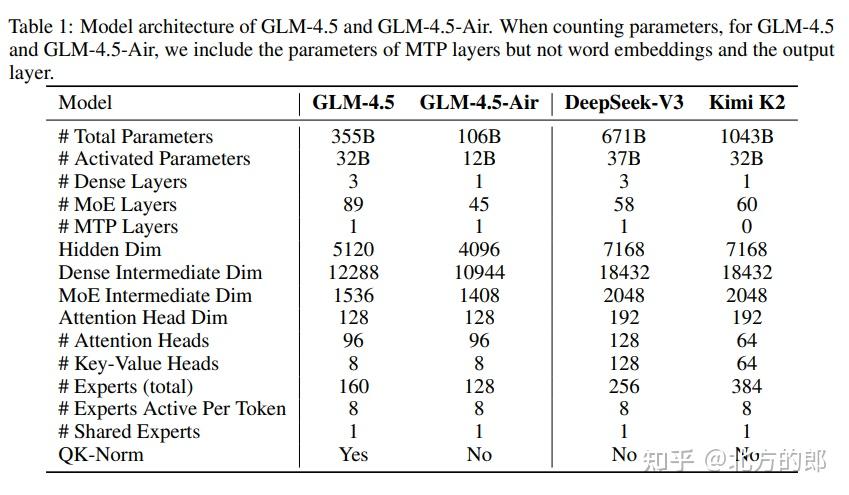
GLM-4.5系列采用了混合专家模型(Mixture-of-Experts, MoE)架构,这是一种在计算效率和模型性能之间取得精妙平衡的先进结构。
- 核心参数:GLM-4.5拥有3550亿(355B)总参数,但在推理时每个token仅激活320亿(32B)参数,大大提高了效率。其紧凑版GLM-4.5-Air则拥有106B总参数和12B激活参数。
- 设计哲学:与一些模型追求更“宽”的网络(更大的隐藏维度和更多的专家)不同,GLM-4.5选择了更“深”的结构(更多的网络层数)。研究团队发现,更深的模型展现出更强的推理能力。
- 技术细节:模型采用了分组查询注意力(Grouped-Query Attention)以提升效率,并创新性地使用了多达96个注意力头,这被证明能显著改善MMLU等推理基准的性能。此外,QK-Norm技术被用于稳定注意力计算。
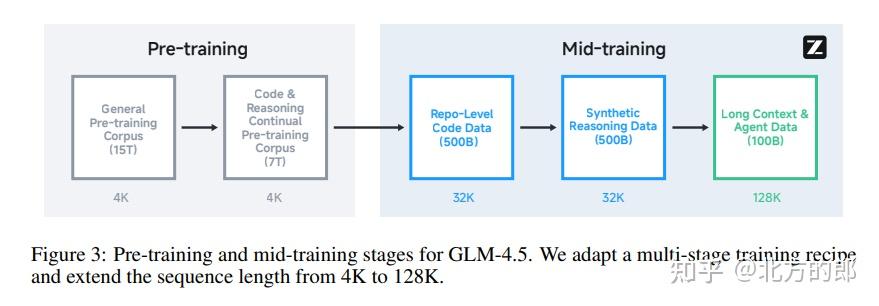
模型是在一个包含23万亿(23T) token的庞大语料库上进行训练的。数据处理是成功的关键,团队为此设计了精细的流水线:
- 网页数据:对海量中英文网页进行质量打分和分桶,高质量数据被多次重复训练(up-sample),以强化高频知识并覆盖长尾知识。团队还应用了SemDedup技术,基于语义而非简单的哈希值来去除重复内容。
- 代码数据:从GitHub等平台收集代码,通过质量模型筛选,并采用Fill-In-the-Middle训练目标来增强代码生成能力。
- 数理数据:利用一个大型语言模型为数学和科学相关的文档打分,高质量的教育内容被优先用于训练,以增强模型的推理能力。
在通用预训练之后,模型进入了一个独特的中期训练阶段,目的是针对性地强化ARC能力。这一阶段使用领域特定的中等规模数据集。
- 仓库级代码训练:将同一个代码仓库的多个文件拼接起来进行训练,让模型学习跨文件的依赖关系,并将序列智谱 AI GLM 教程长度从4K扩展到32K。
- 合成推理数据训练:从网页和书籍中收集大量数理问题,并利用一个强大的推理模型生成详细的解题过程,然后用这些合成数据训练GLM-4.5。
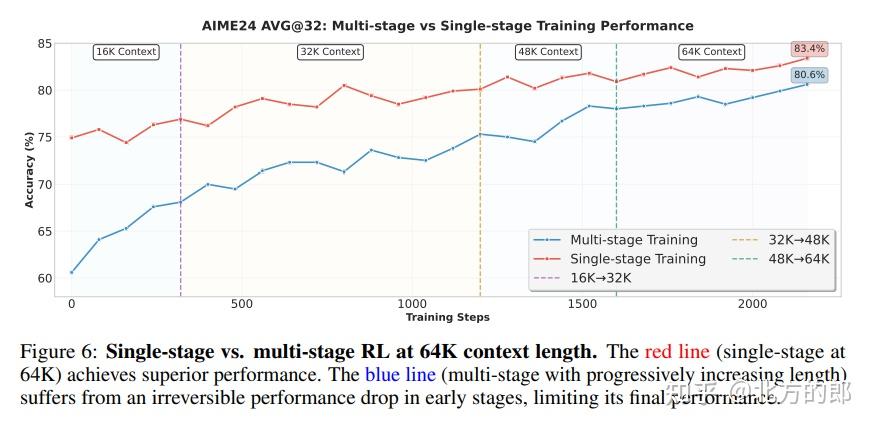
- 长上下文与智能体训练:进一步将序列长度扩展到128K,并引入大规模的合成智能体交互轨迹数据,以提升模型的长程理解和智能体行为能力。
后训练是激发模型潜能、使其与人类指令对齐的关键一步。团队将其分为监督微调(SFT)和强化学习(RL)两个核心环节,并构建了一套复杂的专家迭代流程。
SFT的目标是让模型学会如何遵循指令进行对话和执行任务。
- 创新的函数调用模板:传统上,函数调用的参数使用JSON格式,当参数是代码时会产生大量需要转义的字符,增加了模型学习难度。团队为此设计了一种新颖的XML风格模板,将键和值封装在特殊标签中,极大地减少了代码转义的需求,提升了智能体场景下的易用性和性能。
- 数据策略:团队通过从多个专家模型中“蒸馏”出数百万高质量样本,涵盖推理、聊天、智能体等任务。同时,通过拒绝采样过滤掉低质量回复,并对困难任务的提示词进行响应缩放(response scaling),即为同一提示生成多个优质答案,有效提升了模型在数理任务上的表现。
强化学习(RL)是提升模型高级能力的核心。团队针对不同领域开发了专门的RL技术。
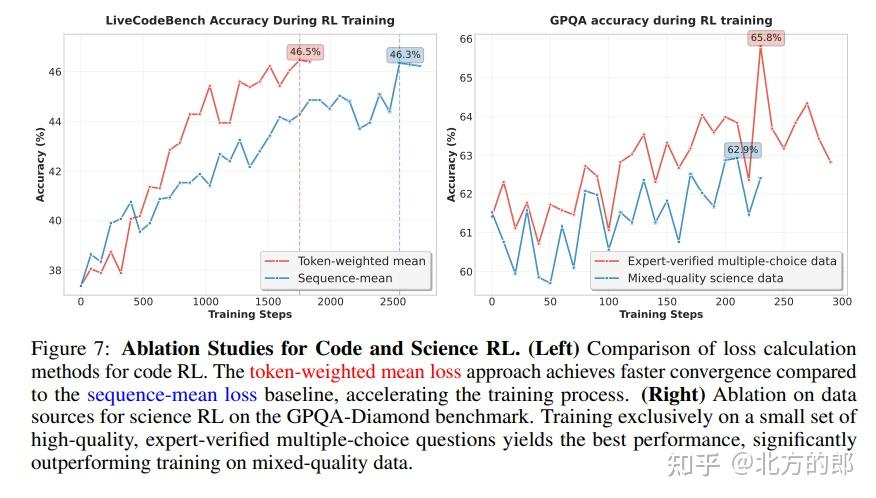
- 推理RL:对于数学、科学等有明确答案的任务,奖励信号非常清晰。团队采用了基于难度的课程学习策略:先用中等难度数据训练,待模型能力提升后,再切换到极高难度的数据,从而持续突破性能瓶颈。实验还发现,对于代码RL,基于token的加权损失比传统的序列平均损失收敛更快;对于科学RL,数据质量远比数量重要。
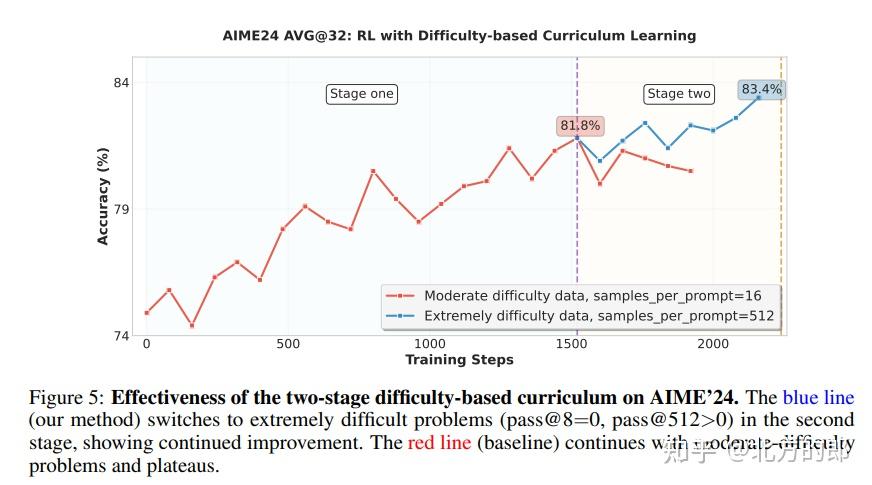
- 智能体RL:对于需要与环境交互的智能体任务,团队采用了结果监督与过程惩罚相结合的奖励机制。即,只要最终答案正确就给予高奖励,但如果中途的工具调用格式错误,则直接给予零奖励并中止。同时,他们采用迭代蒸馏的策略,用RL训练过的更强模型生成新的SFT数据,再进行下一轮RL训练,循环往复,不断推高模型性能上限。
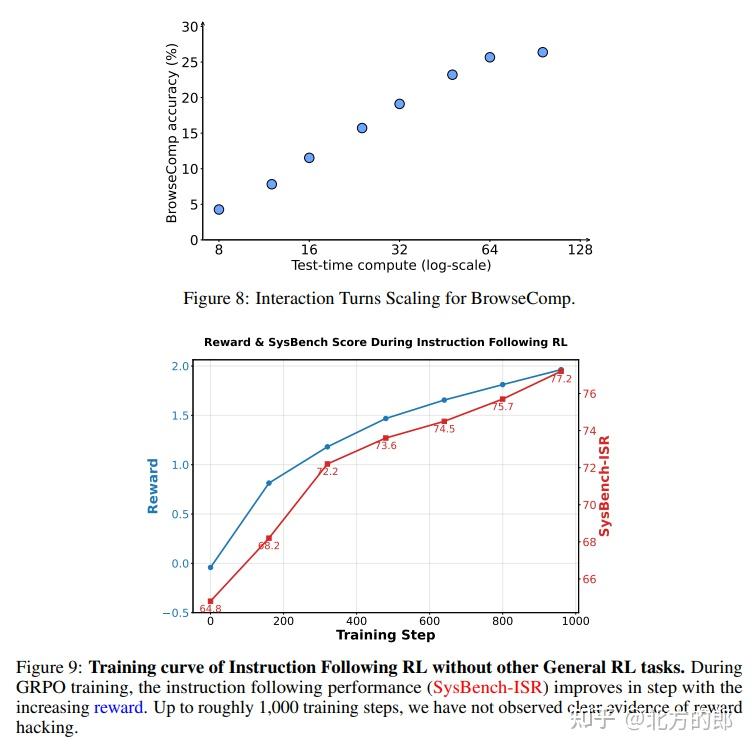
为了全面提升模型,团队还进行了通用RL,融合了规则反馈、人类反馈(RLHF)和模型反馈(RLAIF),以实现更稳健的训练。这一切都构建在团队自研的、名为Slime的开源RL框架之上。该框架设计灵活,支持同步和异步训练模式,并采用FP8混合精度推理等技术加速数据生成,为高效训练大规模、长周期的智能体任务提供了强大支持。
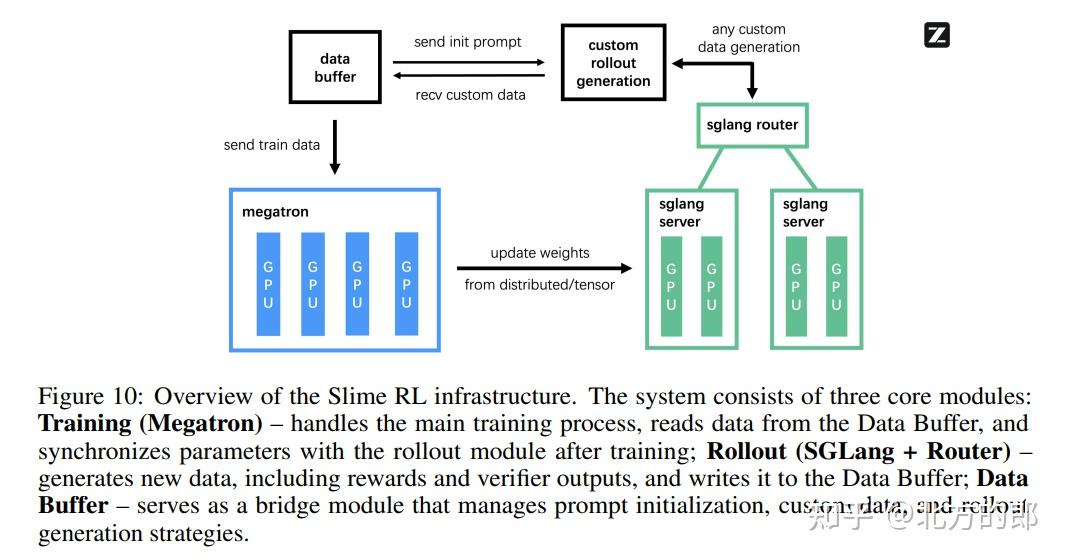
论文的第四部分用翔实的数据展示了GLM-4.5的卓越性能。
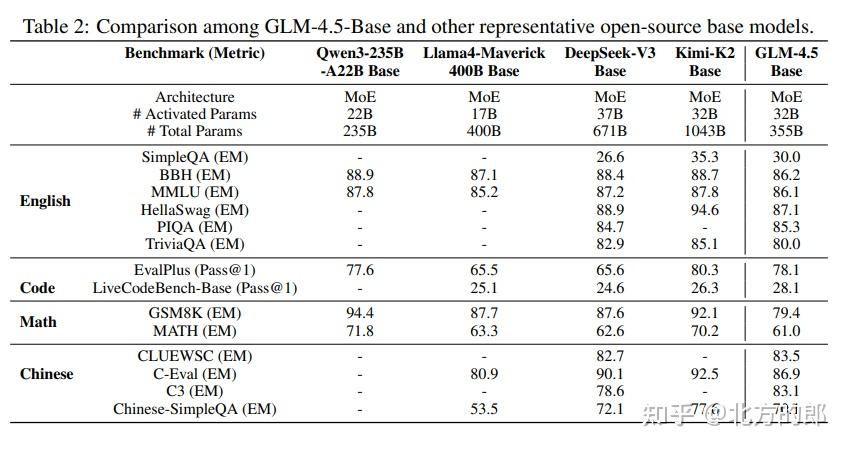
在对标全球顶级模型的12项ARC基准测试中,GLM-4.5表现出色。
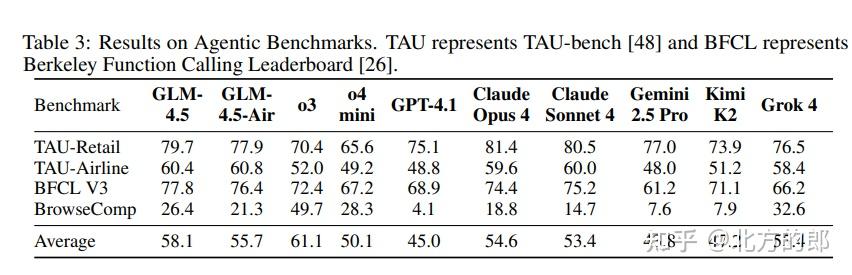
- 智能体能力:在BFCL V3(函数调用)基准上得分77.8%,超越所有基线模型。在TAU-Bench(多领域智能体)上与Claude Sonnet 4并驾齐驱。
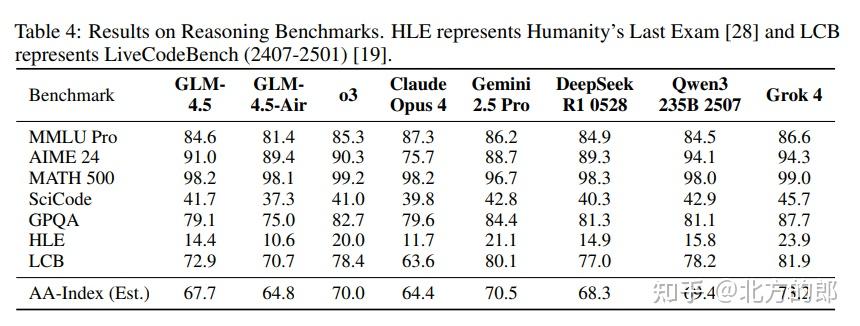
- 推理能力:在AIME 24(数学竞赛)和SciCode(科学编码)上均超越了OpenAI o3模型。在七个推理基准的综合指数上,与DeepSeek-R1-0528非常接近。
- 代码能力:在SWE-bench Verified(真实世界代码修复)上得分64.2%,优于GPT-4.1和Gemini 2.5 Pro。在Terminal-Bench(终端环境操作)上则优于Claude Sonnet 4。平均而言,它是Claude Sonnet 4在代码任务上最强劲的竞争者。
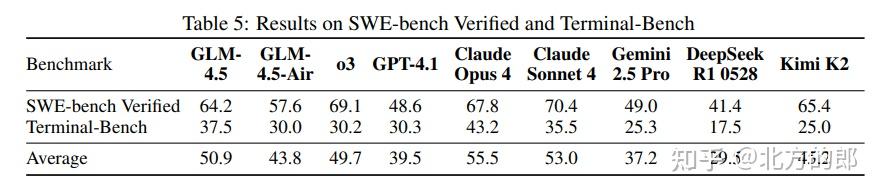
为了评估模型在真实场景下的体验,团队进行了手动评测。
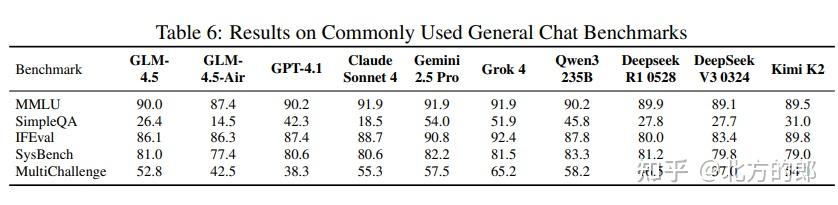
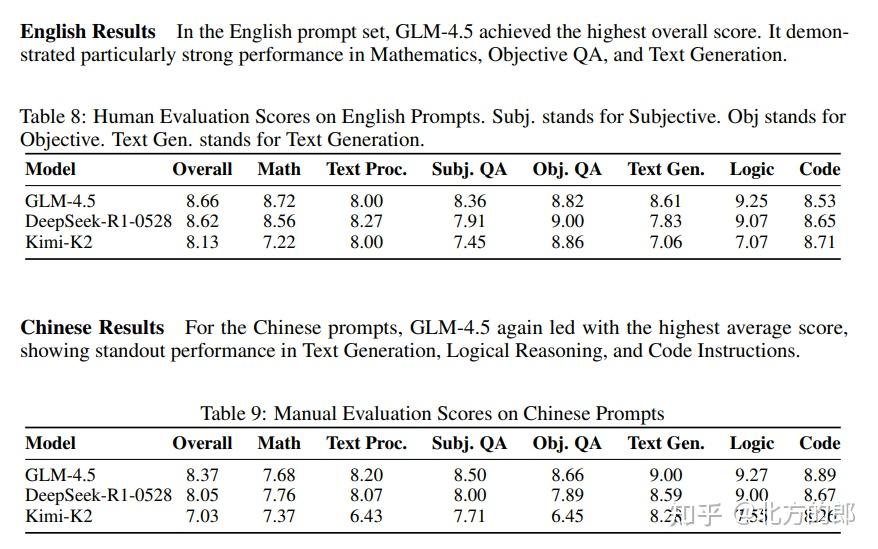
- 通用对话:在对660条覆盖多语言、多场景的真实用户提示词进行的人工盲评中,GLM-4.5在英语和中文上的综合得分均超越了DeepSeek-R1-0528和Kimi K2。
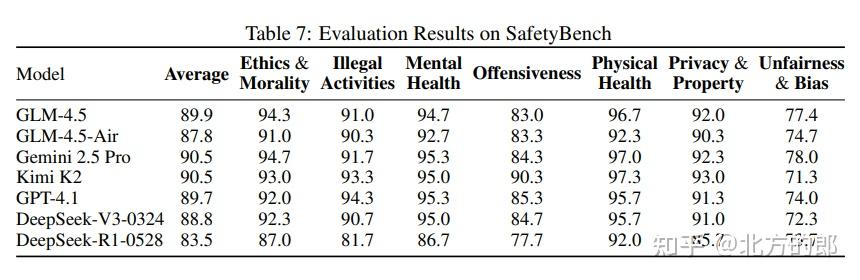
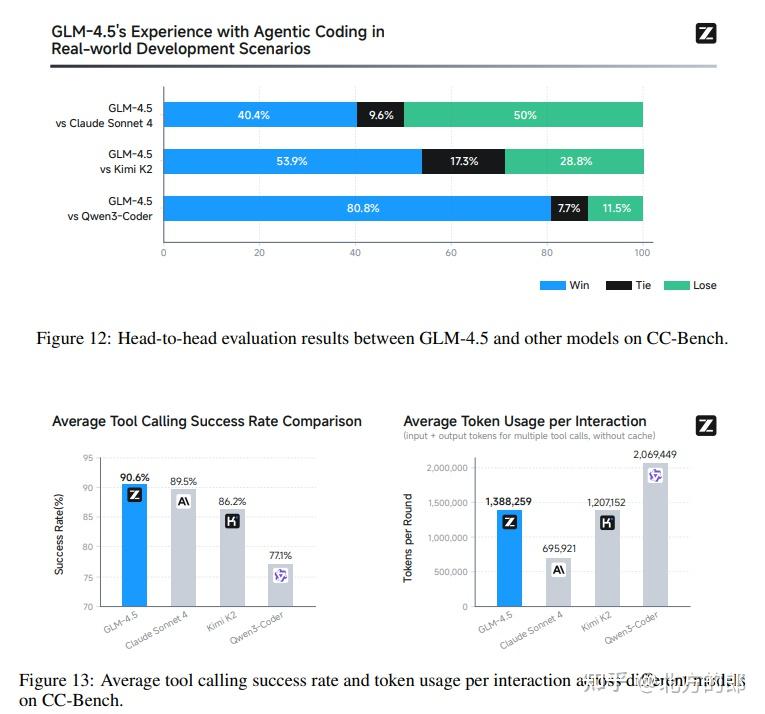
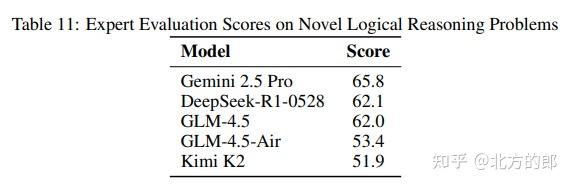
- 代码智能体:在一个名为CC-Bench的真实开发场景基准测试中,GLM-4.5在与Qwen3-Coder的头对头比较中,胜率高达80.8%。其工具调用成功率达到90.6%,在所有对比模型中最高,展现了极高的可靠性。
- 翻译能力:在100个专门挑选的、极具挑战性的翻译案例(包含网络流行语、文化符号、深层上下文)中,GLM-4.5的平均得分(1.71)显著优于多个专业的翻译模型(得分在0.38-0.65之间),展示了其强大的知识和文化理解能力。
论文最后总结道,GLM-4.5系列模型的发布,代表了在构建兼具推理、编码和智能体能力的通用模型方面迈出的重要一步。通过采用MoE架构和一套复杂而精密的多阶段训练与后训练方法,GLM-4.5在全球范围内展现了顶级的竞争力。通过开源模型权重,研究团队希望能够赋能更广泛的开发者和研究者,共同推动大型语言模型技术向着更通用、更强大的方向发展。
——完——
@北方的郎 · 专注模型与代码
喜欢的朋友,欢迎赞同、关注、分享三连 ^O^
发布者:Ai探索者,转载请注明出处:https://javaforall.net/268191.html原文链接:https://javaforall.net


