
文章转载自「智东西」
今日,百度正式开源文心大模型4.5系列模型。
文心4.5系列开源模型共10款,涵盖了激活参数规模分别为47B和3B的混合专家(MoE)模型(最大的模型总参数量为424B),以及0.3B的稠密参数模型。预训练权重和推理代码完全开源。
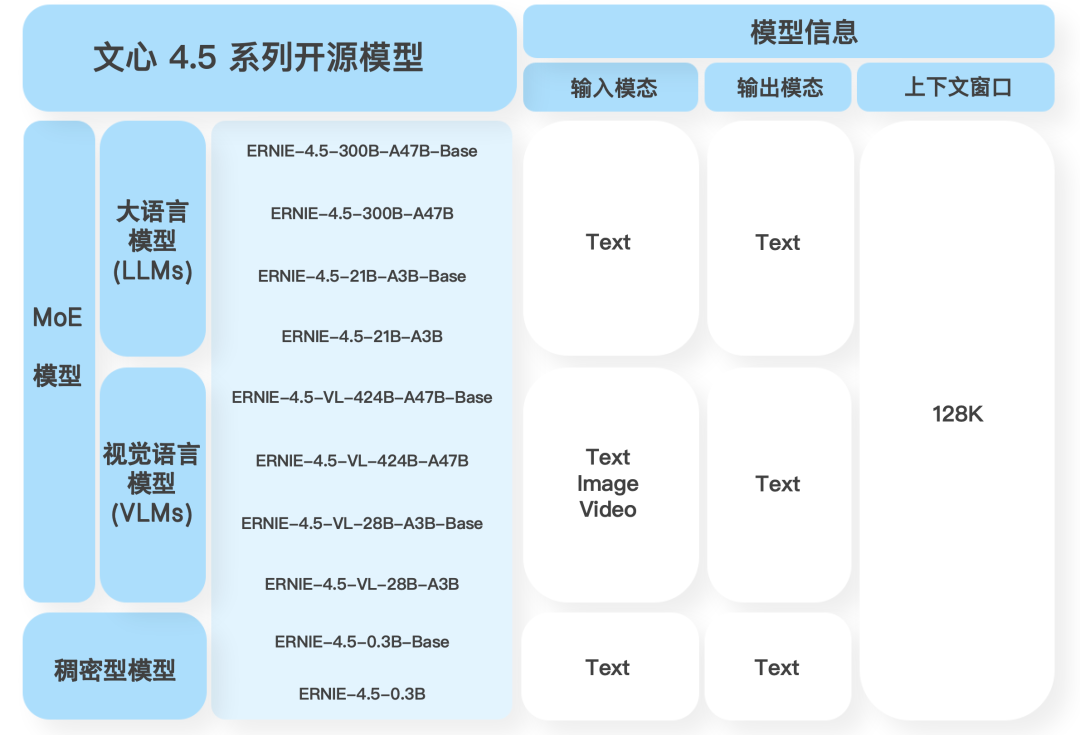

目前,文心大模型4.5开源系列已可在飞桨星河社区、Hugging Face等平台下载部署使用,同时开源模型API服务也可在百度智能云千帆大模型平台使用。
用户可在文心一言(https://yiyan.baidu.com)即刻体验最新开源能力。
Hugging Face:https://huggingface.co/baidu/models
飞桨星河社区:https://aistudio.baidu.com/modelsoverview
GitHub:https://github.com/PaddlePaddle/ERNIE
技术报告:https://yiyan.baidu.com/blog/posts/ernie4.5
超 8000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。
邀请从业者、开发人员和创业者,飞书扫码加群:
https://applink.feishu.cn/client/chat/chatter/add_by_link?link_token=da9v6868-6a14-44ea-95ff-f4b6cff44809&qr_code=true (二维码自动识别)
- 最新、最值得关注的 AI 新品资讯;
- 不定期赠送热门新品的邀请码、会员码;
- 最精准的AI产品曝光渠道
多项评测超 Qwen3、DeepSeek-V3
文心大模型4.5于3月16日发布,是百度自研新一代原生多模态基础大模型,其图片理解涵盖照片、电影截图、网络梗图、漫画、图标等多种形态,也能理解音视频中的场景、画面、人物等特征,并且在生成名人、物品等方面更具真实性。
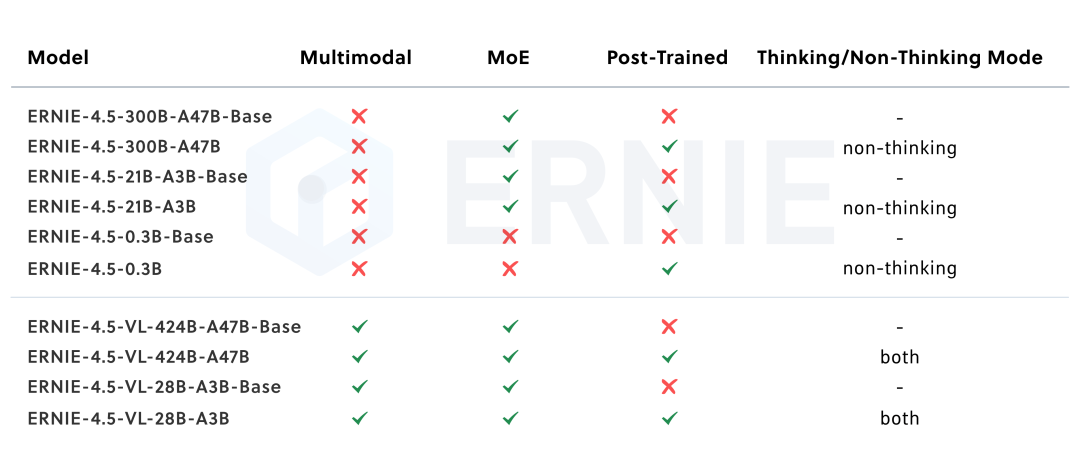
文心4.5系列模型能力盘点
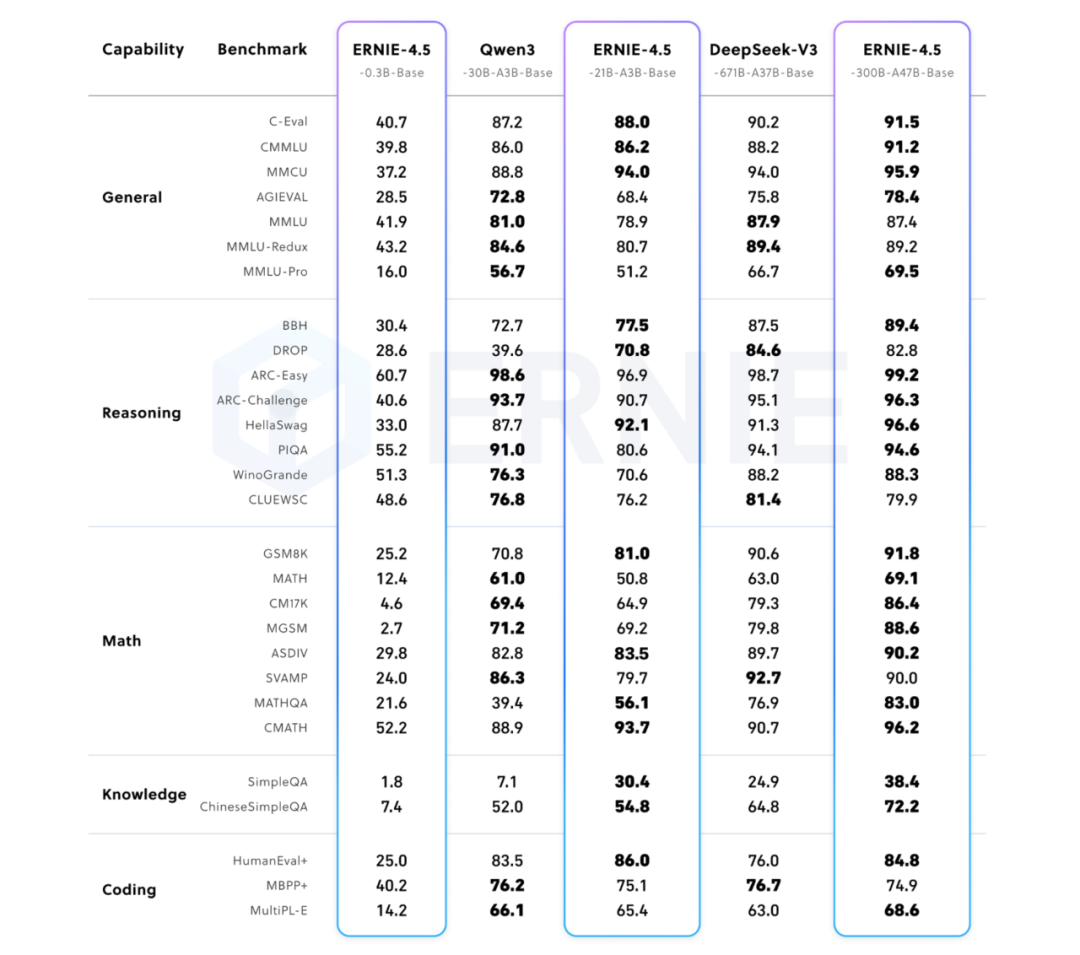
文心4.5系列模型与Qwen3、DeepSeek-V3基准测试比较
模型权重按照Apache 2.0协议开源,支持开展学术研究和产业应用。此外,基于飞桨提供开源的产业级开发套件,广泛兼容多种芯片,降低后训练和部署门槛。
对于原生多模态大模型,3月初,百度创始人、CEO李彦宏在人民网发表的署名文章就提到:“原生多模态大模型,打破之前先训练单模态模型再拼接的方式,通过统一架构实现文本、图像、音频、视频等多模态数据的原生级融合,实现对复杂世界的统一理解,这是迈向通用人工智能(AGI)的重要一步。”
文心一言 ERNIE Bot 教程
三大关键创新
文心大模型4.5系列背后的关键技术创新包括:
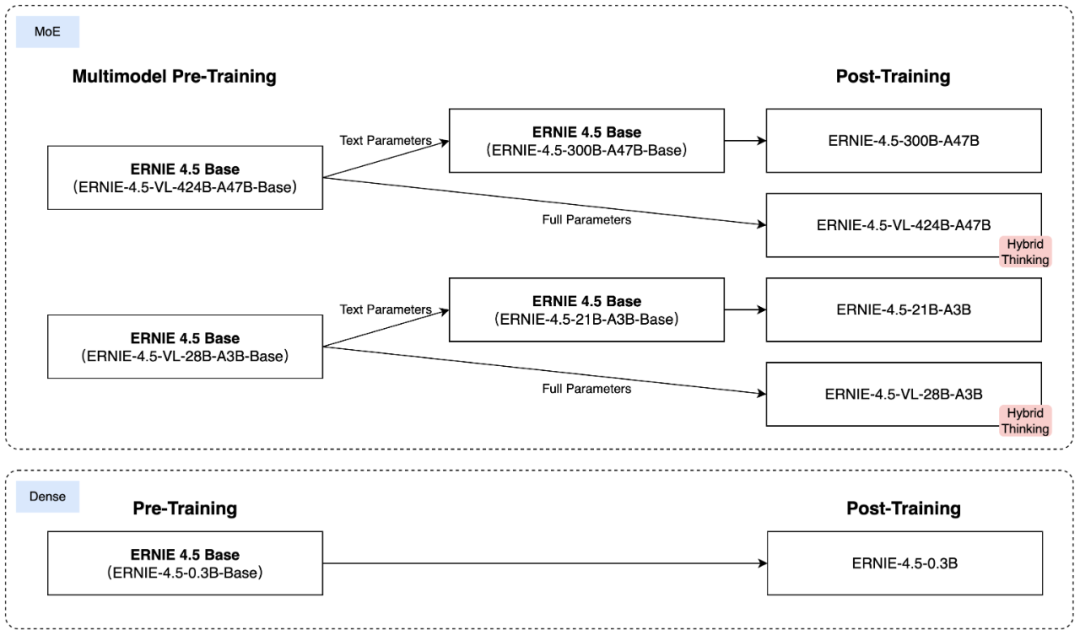
1、多模态异构MoE预训练:其模型基于文本和视觉模态进行联合训练,可捕捉多模态信息的细微差别,并提升文本理解与生成、图像理解以及跨模态推理等任务的性能。
为了实现这一目标,避免一种模态阻碍另一种模态的学习,百度研究人员设计了一种异构MoE结构,并引入了模态隔离路由,采用了路由器正交损失和多模态标记平衡损失。这些架构选择可以确保两种模态都得到有效表示,从而在训练过程中实现相互强化。
2、可扩展、高效的基础设施:百度提出异构混合并行和分层负载均衡策略,以实现ERNIE 4.5模型的高效训练。研究人员通过采用节点内专家并行、内存高效的流水线调度、FP8混合精度训练和细粒度重计算方法,实现了预训练吞吐量提升。
在推理方面,研究人员提出多专家并行协作方法和卷积码量化算法,以实现4位/2位无损量化。此外还引入具有动态角色切换的PD分解,提升ERNIE 4.5 MoE模型的推理性能。基于PaddlePaddle构建的ERNIE 4.5可在各种硬件平台上提供高性能推理。
3、针对特定模态的后训练:为了满足实际应用的多样化需求,百度针对特定模态对预训练模型的变体进行了微调。其大模型针对通用语言理解和生成进行了优化。
VLM专注于视觉语言理解,并支持思考和非思考模式,每个模型都结合使用了监督微调(SFT)、直接偏好优化(DPO)或统一偏好优化(UPO)的改进强化学习方法进行后训练。
在视觉-语言模型的微调阶段,视觉与语言的深度融合对模型在理解、推理和生成等复杂任务中的表现起着决定性的作用。为了提升模型在多模态任务上的泛化能力和适应性,研究人员围绕图像理解、任务定向微调和多模态思路推理三大核心能力,进行了系统性的数据构建和训练策略优化。此外,其利用可验证奖励强化学习(RLVR)进一步提升模型对齐和性能。
点名文心大模型4.5 Turbo开源
Reddit上的开发者认为,百度此次开源的模型中小参数的版本对内存受限的配置是不错的选择,他还认为300B可以和DeepSeek V3 671B战斗,21B可以与阿里Qwen 30B战斗。
也有开发者指出,百度此次开源的模型中,28B模型在基础文本能力上增加了视觉功能很酷。

开发者也在期待百度文心大模型4.5 Turbo的开源:

更多阅读
TRAE 如何思考 AI Coding :未来的 AI IDE,是构建真正的「AI 工程师」
聊过 200 个团队后的暴论:不要拿 AI 造工具,要建设「新关系」
罗永浩:梁文锋建议我「靠嘴吃饭」,我想做个播客帮助科技创业者
发布者:Ai探索者,转载请注明出处:https://javaforall.net/269473.html原文链接:https://javaforall.net


