
短的结论:革命尚未成功,百度仍需努力
基本信息:
- 4.5 turbo
- 成本:3.2每百万
- 速度:约53字每秒
- 平均长度:约5500字
- 平均耗时:101秒
- X1 turbo
- 成本:4块每百万
- 速度:约58字每秒
- 平均长度:约13700字
- 平均耗时:241秒
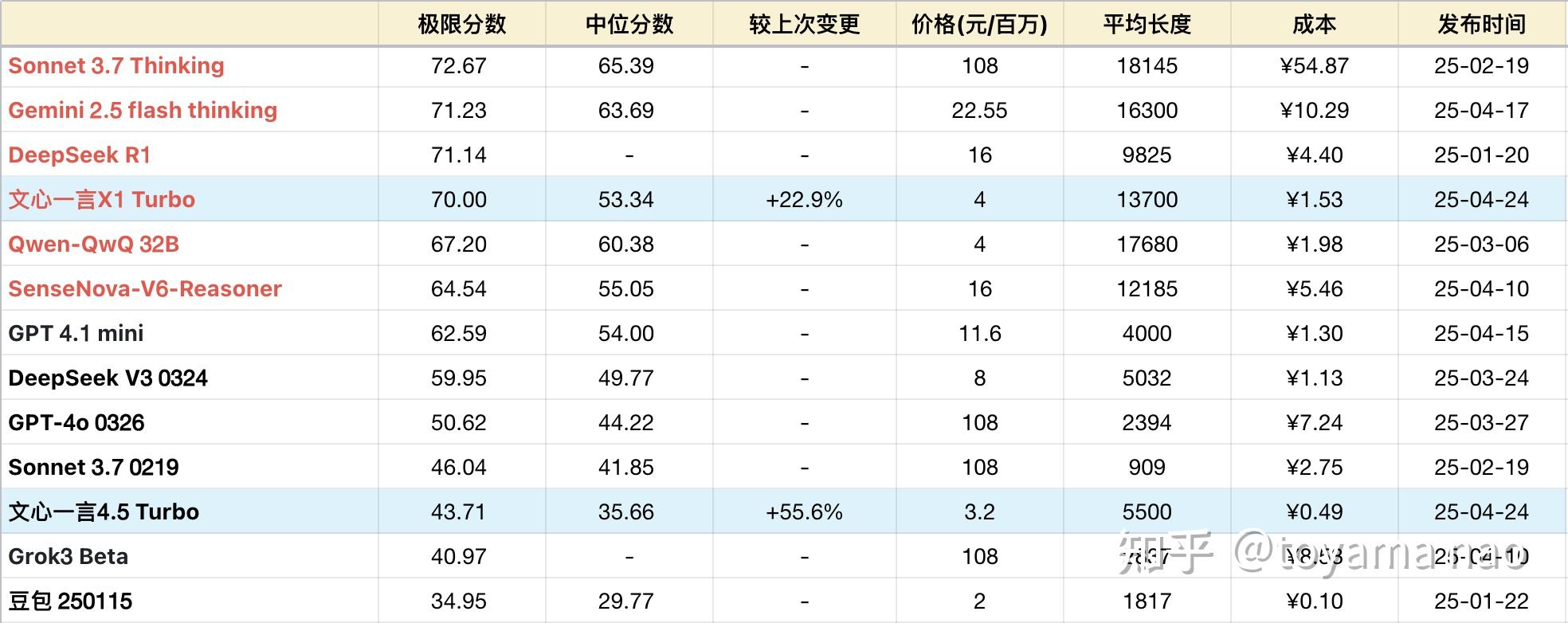

*表格为了突出对比关系,有一定裁剪,不是完整排序。
测试方式:参见https://zhuanlan.zhihu.com/p/32
*这次测试基于5月题目,已经增加#36题,所以所有模型的分数相比4月有变动。
在3月16日,文心4.5发布时,首轮测试成绩并不理想,参见https://zhuanlan.zhihu.com/p/32,其主要问题是较多幻觉问题,计算能力低下,上下文过短,疑似迫于发布日压力赶工的半成品。而本次turbo升级,则在许多问题上有大幅改善。
下面重点分析turbo相比原版各自提升和不足。
优势:
- 4.5turbo在规则明确的计算问题上改善明显。如#21线段交点,#22连续计算,计算思路明确,解题过程规整,正确率大幅提升,推理风格更接近新版X1 turbo。而旧版4.5和x1在数学计算上的思路较为凌乱,过程也潦草。可见百度在数学训练方面确实有新思路或者换了新的对齐。相比之下,x1turbo的数学提升就主要在于思路过程,正确率与旧版区别不大。
- 4.5turbo和x1turbo在程序方面有一定进步,从结果来看,4.5turbo表现堪用。输出稳定性也比旧版更好。但其有不小概率会使用英文作答,且大概率程序的注释全部用英文。使用角度来看无伤大雅,但可推知百度在提升编程能力的思路。
- x1turbo在人类直觉问题上有小突破,从旧版毫无头绪,盲目解答,进化到偶尔有一些正确思路,但思考深度仍不足。如#23解密问题,先前头部模型Gemini 2.5/o3/o4等3pass可稳定找到正确思路,而x1turbo只在一次测试中偶然找到思路并正确解出。另一次测试找到了思路,但惰于求解。从推理过程来看,x1turbo清楚自己的“猜测”成分过高,无法证实,因此作答小心谨慎。
劣势:
- 指令遵循问题上,4.5turbo表现不容乐观,许多badcase上承旧版。如#30日记整理问题,在多个条件约束里,4.5turbo多次输出都随机遵循其中部分约束。而难兄难弟的x1turbo有时会因为幻觉,将条件的应用范围搞错。#30本身不难,主要考察多个条件下模型如何遵循,遵循哪些。文心turbo系列当前表现泛化来看,在类似信息提取,资料整理等应用场景恐使用者多需费心。
- 4.5turbo在字符相关问题上没有改善,典型如#9单词缩写,错误与旧版如出一辙。
- 4.5turbo和x1turbo都存在大量死循环和中途切换到英文推理的现象。其中4.5turbo死循环率在10%,x1turbo略低,在9%。二者异常率都显著高于初版。疑似是过于激进的成本优化导致。
- x1turbo在高难度问题上,有不小概率响应超时(大于600秒)。而旧版在同样问题上表现为抓住一个简单但错误的思路进行推理。
赛博史官曰:
3月时,百度宣称4.5达到4o水平,当时实测离1月的4o确实较为接近,而4o在3月末更新后差距再次拉大。目前4.5turbo经过发力再次实现接近,而4o也进行了新一轮更新(目前还未测试),可以预见差距会扩大,可谓是“一代模型有一代模型的使文心一言 ERNIE Bot 教程命”。
尽管x1 turbo本次杀进推理模型第二梯队,但其稳定性显著劣于同档位模型。在用户缺乏重试耐心的前提下,未必会认为x1 turbo足够强大。
此外百度重点宣传的x1 turbo在写作方面的提升,虽然未直接测试写作能力。但从先前经验写作能力正比于推理能力来看,预计写作水平确实会有提升。但考虑其幻觉率偏高,写作输出的直接可用性存疑。
百度诸君请继续努力。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/269550.html原文链接:https://javaforall.net


