
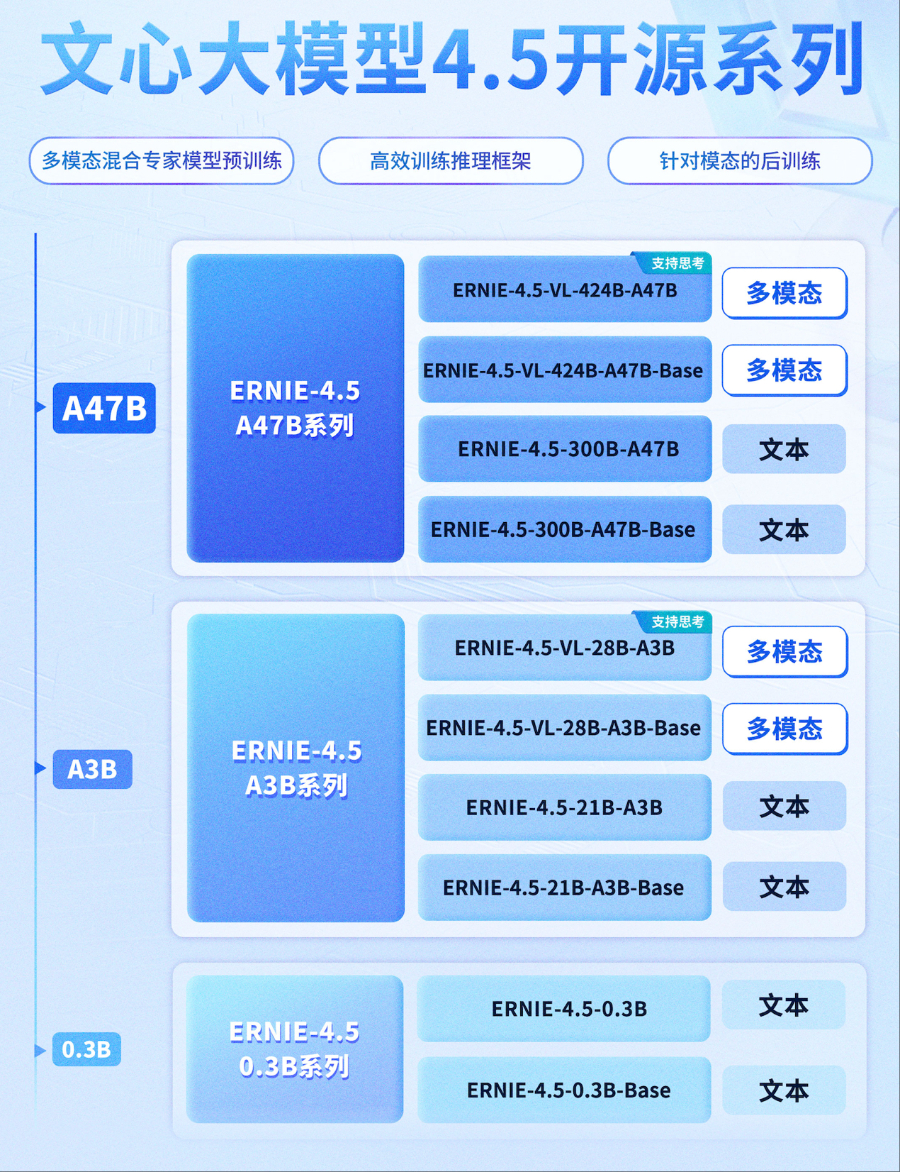
6月30日,百度正式开源文心大模型4.5系列模型,涵盖47B、3B激活参数的混合专家(MoE)模型,与0.3B参数的稠密型模型等10款模型,并实现预训练权重和推理代码的完全开源。目前,文心大模型4.5开源系列已可在飞桨星河社区、HuggingFace等平台下载部署使用,同时开源模型API服务也可在百度智能云千帆大模型平台使用。

百度文心大模型4.5系列正式开源-新华网
我看了下Github上发布详情,发现这次百度这次的开源模型反而不是重点,它的胃口主要在于生态。
简单来说,AI大模型必定会有一代更比一代强,但是生态基础不一样,它更像是挖金矿的铲子,用户忠诚度极高。
文心4.5的Github链接:https://github.com/PaddlePaddle/ERNIE
文心Ernie4.5,这次一共发布了10款大模型,但实际上涵盖了三个品类:
- LLM:传统的大语言模型,也就是纯文字的那种,主流的MoE混合专家模型,有两个size,一个大的300B,一个小的21B,跨度很大。
- VLM:视觉语言模型,也就是现在主流的多模态模型,可以无缝的处理文字/图片/视频,但是目前只能输出文字,比如让它描述个图片视频什么的。
- Dense Model:这个是跟MoE相对的稠密模型,也就是这种模型每推理一次,就会用到所有的参数,代价就是消耗的计算量大,所以这个类目只有0.3B的模型,非常适合跑在端侧。

单纯从发布的10个大模型来看,可以很清晰地看到百度在尽可能的探索AI大模型的所有主流方向,Reasoning推理,MoE,Dense,端侧等等。
但是它这个MoE有亮点,那就是Multimodal Heterogeneous MoE Pre-Training,MoE我们大文心一言 ERNIE Bot 教程家应该都不陌生,像DeepSeek R1就是一个MoE的混合专家模型,也就是大模型,但是推理的时候只执行一部分,所以兼备了质量和速度。
而Ernie的这个MoE,首先它是多模态的,可以处理除了文本之外的图片和视频,这就要求在训练的时候适配多模态,其次更重要的是Heterogeneous异构这个词,一般来说,之前的多模态大模型,训练的时候就像是一口“大熔炉”,所有的内容进行都先encoding,换句话说,各种模型的数据最终都会转换成数学里面的向量。
再简单一点儿,那就是不管你是普通话还是什么方言,最终都要转换成英文表达。
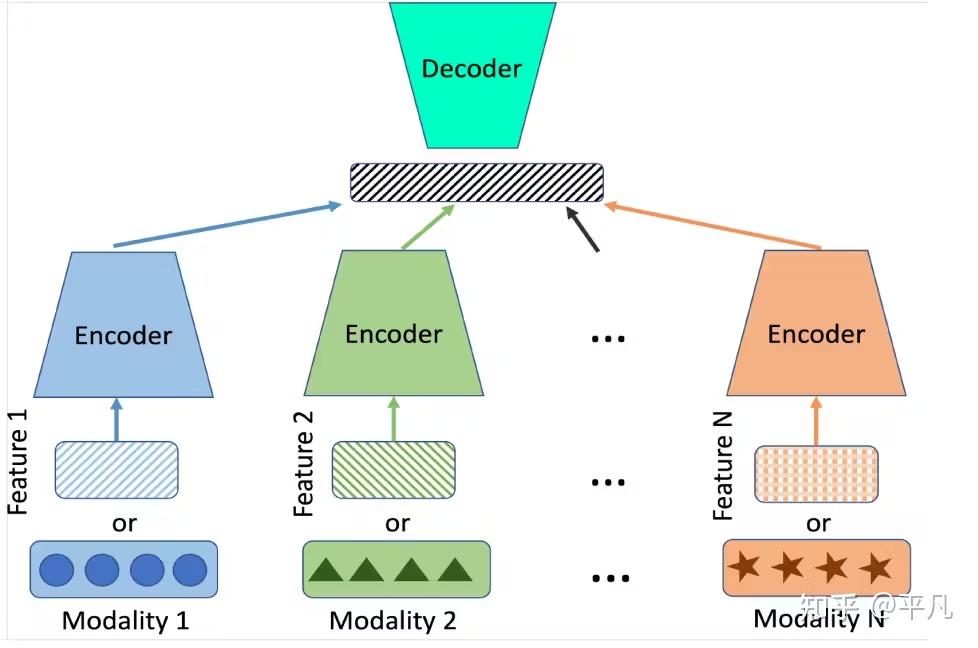
这里面就有问题了,因为图像和文字本来就是两种不同的表达方式,那么用这种“一锅烩”的方式,为了学好图像,可能会牺牲一些语言的精细度;为了更好地理解语法,可能会忽略图像的细节。最终得到的可能是一个“折中”的模型,而不是一个“双料冠军”。
文心4.5做的事其实直觉上很简单,它不再是简单地将图像和文本数据“搅拌”在一起喂给模型,而是设计了一个分工明确、调度智能、训练有方的“专家委员会”系统。通过异构结构实现物理隔离,通过隔离路由实现任务的精准分配,再通过两种特殊的损失函数从数学上保证了专家团队的专业性和学习过程的公平性。
最终达到的效果是 “相互促进 (mutual reinforcement)”,即文本知识的学习可以帮助模型更好地理解图像,反过来也一样。
性能大家可以自己去对比,毕竟都是些打榜的benchmark结果,不能当成使用效果来看,具体怎么样,得看自己的需求,没有什么模型十全十美。

我甚至觉得这部分才是大头,因为百度其实一直做的深度学习框架飞桨(PaddlePaddle),在国内还是挺有基础的,因为模型可能会过时,但是生态可是一个长期主义的典型代表。

这次随模型一同发布的,还有文心大模型开发套件ERNIEKit和高效部署套件FastDeploy。ERNIEKit覆盖了从微调(SFT)、对齐(DPO)到量化的全流程开发,而FastDeploy则解决了多硬件平台(如各种芯片)的高效推理部署问题。
这一整套“全家桶”式的解决方案,极大地降低了开发者使用文心大模型的门槛。
对于百度来说,我一直是跟Google对标的,毕竟大家都是做搜索引擎出身,再加上本身有的大量语料资源,计算资源,是可以下盘大棋的,如果一旦习惯了这套从开发到部署的流畅体验,就会自然而然地被留在飞桨的生态系统中。
短的结论:旧世界的老人轻敲新世界开源的大门
基本信息:
- ERNIE-4.5-300B-A47B
- 成本:3.2元每百万
- 平均长度:约3780字
- 速度:约47字每秒
- 平均耗时: 69秒(基于千帆部署版本)
- ERNIE-4.5-21B-A3B
- 成本:免费
- 平均长度:约7960字
- 速度:约120字每秒
- 平均耗时: 65秒(基于千帆部署版本)
逻辑成绩:
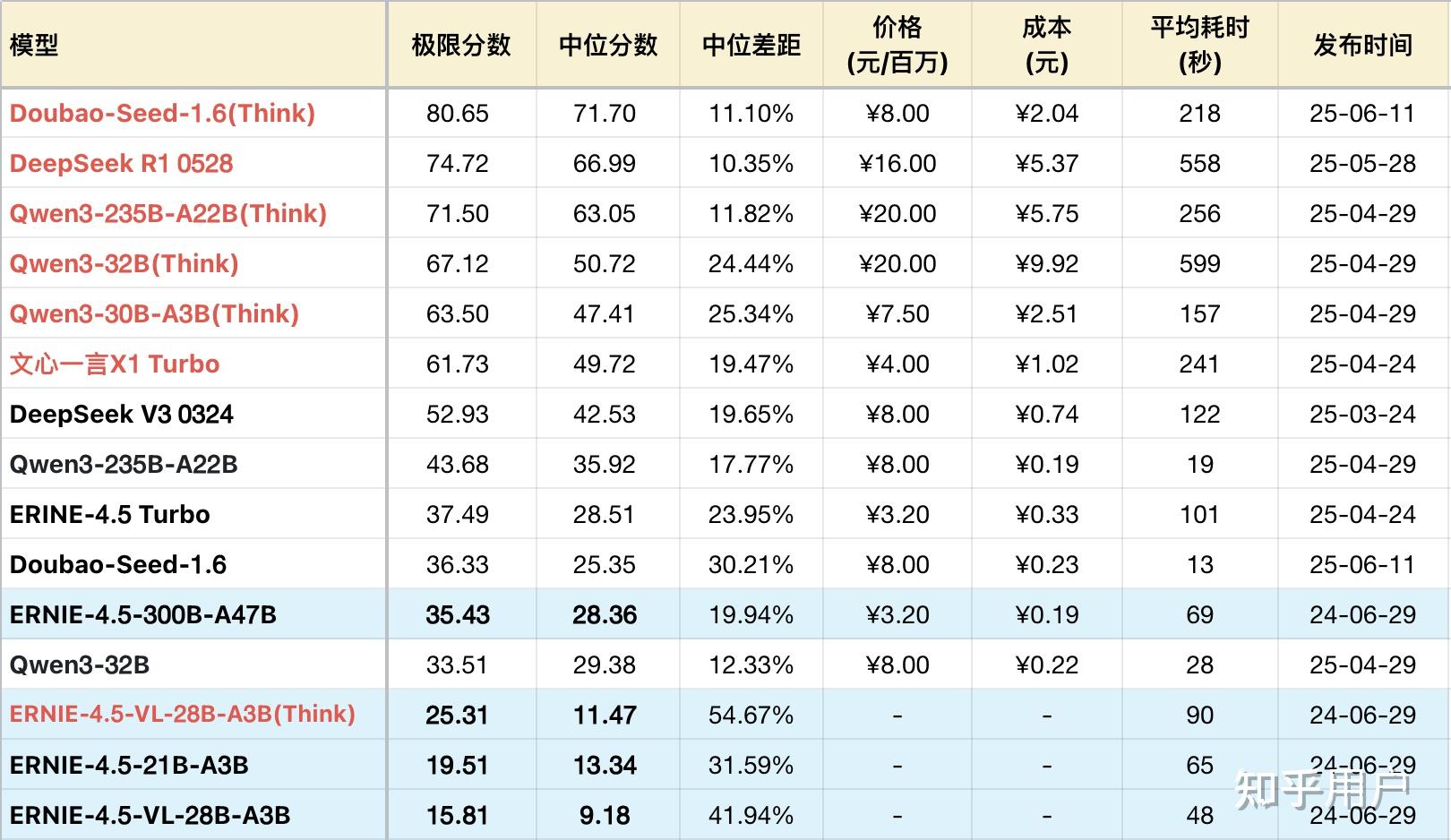
*表格为了突出对比关系,有一定裁剪,不是完整排序
测试方式:参见
大语言模型-逻辑能力横评 25-06月榜(R1/Gemini 2.5/Doubao-Seed-1.6…
*完整榜单更新在Github
进行战略转型之后的百度,选择了拥抱开源,在上半年的最后一周交出了自家首个开源大模型,尺寸齐全,还有多模态版本。但大语言模型不支持推理,仅多模态支持推理。上面给出的信息以大语言模型为主,也附带了中杯多模态模型28B-A3B的推理成绩作为参考。
旗舰款300B-A47B在千帆是当做ernie-4.5-turbo-128k-preview,作为自家128k模型的继任者。并且与4.5-turbo-32k差距不大,中位分数几乎一样。但A47B速度却要快得多,原因是A47B的输出Token开销只有4.5闭源版的60%,连带的使用成本也低了60%。
中杯的21B-A3B情况就不乐观了,各方面都较300B-A47B差距巨大。在百度官方的技术报告中,将A3B与Qwen3-30B-A3B对比,二者在各类榜上打的有来有回,胜负难分。笔者虽然没有直接测试过Qwen3-30B-A3B的逻辑成绩,但从Qwen3-32B和30B-A3B的推理版成绩对比来看,30B-A3B的非推理成绩大致也在极限分25分左右,与文心21B-A3B确实在同一档位。百度这次的报告还是很诚恳。
作为参考的多模态版本28B-A3B,其视觉理解表现在此按下不表,7月月中的视觉理解月榜会附上完整测试。仅看逻辑成绩表现,是不如语言模型的,巨大的中位分差距让其终端表现接近不可用。加上推理也只在部分中低难度题目上稍微拿到更多分数,积少成多,总体超过语言模型,但代价是不稳定性更高。
下面重点分析两个开源版本与自家闭源的4.5-turbo-32k的对比。旗舰模型简称为A47B,中杯模型简称为A3B。
优势:
- 稳定性:A47B输出稳定性控制较好,在17%的问题上,3pass可以输出高度相似的回答。其中位差距不到20%,甚至低于4.5闭源模型。
不足:
- 字符幻觉:A3B在字符问题上接近完全不可用,如#9单词缩写,#11岛屿面积,#18字符迷宫,#33洗牌分牌等,对同档位其他模型如Qwen3-32B来说不算难,能拿到部分分数。但A3B字符幻觉过重,几乎不得分。A47B情况改善很多,但幻觉情况也时有发生,概率不低。
- 计算缺陷:A3B和A47B在数学计算上均轻微落后于闭源版本,如#22连续计算,#38函数求交,开源版本在公式使用和计算误差上均存在缺陷,尤其A3B对稍复杂的乘除运算几乎无能为力。对于规则不明确,需要更多思维技巧的计算题,如#25算24点,
- 指令遵循:开源的2个版本与闭源版本存在诸多相同缺陷,尤其在指令遵循相关问题上,如#10水果热量,要求给出多组不同水果搭配,而3个模型都会将同一组搭配视作不同组,反复给出。#30日记整理,#40代码推导,3个模型虽然尺寸差异巨大,但回答几乎相同,不可用,分数低。指令遵循是4.5系列的固有缺陷,不能指望开源版本有差异表现。
- 暴力求解:受限于A3B最大8K的输出和A47B最大12K的输出,一些复杂问题无法完成作答,A3B受影响更大。但从其相关问题的推理过程来看,存在大量暴力穷举,遍历,因此即便提升输出长度限制,两个模型在相关问题可预料得分也会偏低。
- 英文输出:两个版本在少数问题上会偶现中途切到英文进行推理输出。甚至#30日记整理,A47B毫无理由的对日记进行了英文翻译。
赛博史官曰:
当年视开源为洪水猛兽的百度曾认为“最好的大模型一定是闭源”,一语成谶,如今的文心4.5开源版本一定程度上兑现了这个预言。
有Qwen3的珠玉在前,后来的开源模型难免要与之对比,文心团队毫不避讳的在报告中大量引用于Qwen3,Qwen2.5的对比数据,尽管这些数据显示文心4.5在各方面都占不到优势。但相比4.0时代连对比测试都不参加来说,敢于正视差距也是进步的开始。延伸阅读:
文心一言4.5 turbo & X1 turbo 测评
目前所有评测文章在公众号:大模型观测员 同步更新。

说实话,百度这个ERNIE 4.5 整得不如 “罗永浩数字人”给力。
国产现在又到了一条线上,就是Gemini 2.5 Flash Thinking 水平之下,除了DeepSeek,靠”偶发性暴击”能打穿Flash,其他都被Flash摁着头。
希望百度能带来更多直接落地产品,萝卜快跑,数字罗永浩,整得都挺好的,别家还不一定能做。
大模型不做SOTA,真的太无聊了,
我想要一个远远甩开Flash Thinking的日用模型。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/269908.html原文链接:https://javaforall.net


