
百度发了文心一言5.0的技术报告,趁着周末也是读了一下。
整体报告给我的感觉是“晦涩”,因为我大部分时间是在关注纯文本模型/LLava那种多模态
而文心一言专注于端到端的统一多模态,很多知识在读报告时也是有所了解。
原文链接:ERNIE 5.0 Technical Report
我认为该报告比较突出的工作:
- 端到端的多模态训练
- 弹性训练
我没想到这篇报告竟然没有提及Agentic RL,也许主打的就是统一多模态吧。
由于本文文字内容过多,我已经尽量言简意赅的进行了解释,其中凡是由“注:”开头的,均为笔者自己添加的文字,与原文无关。
ERNIE 5.0,这是一个下一代基础模型,旨在将文本,图像,音频和视频功能集成在统一的自回归框架下,用于多模态理解和生成。
其摒弃了在文本模型后“挂载”其他模态解码器的传统做法,而是从零开始将文本、图像、音频、视频全部映射到统一的 Token 空间。
是纯粹的端到端多模态模型,采用万亿参数规模的混合专家模型(MoE),其路由机制不根据模态(如“图像”)来分发 Token,而是基于 Token 的语义特征进行路由。
使用 FlashMask 处理视觉注意力,解耦分词器与主干网络的并行策略,并构建了大规模解耦强化学习训练平台。
ERNIE 5.0采用超稀疏混合专家架构,将语言、图像、视频和音频集成在单一自回归框架内,以实现多模态理解和生成。其架构如图1⬇️所示
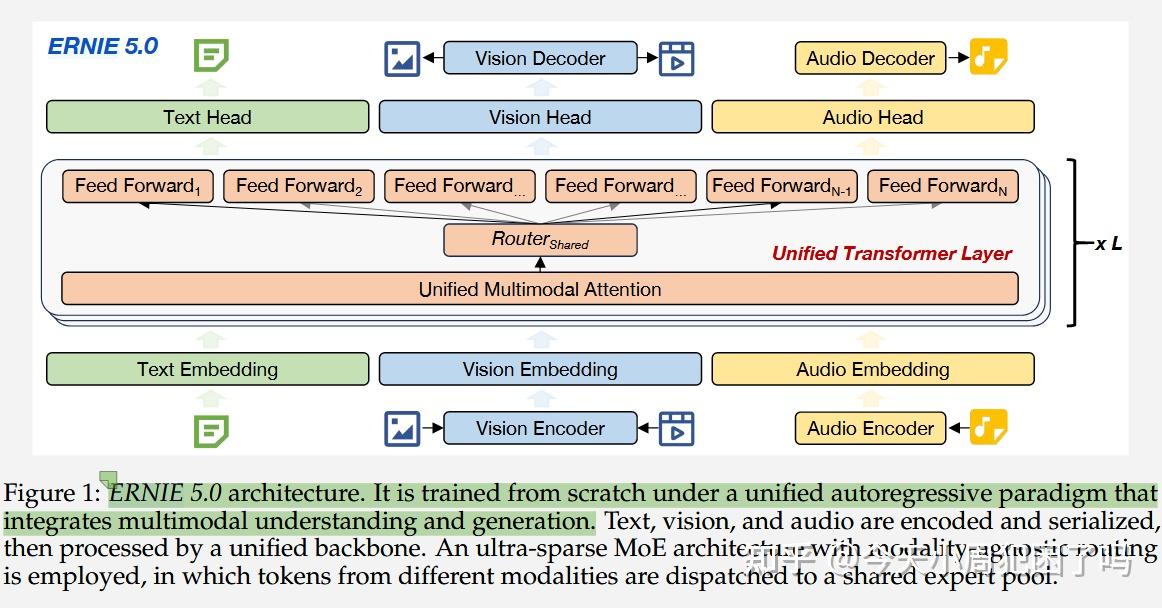

异构模态在 Token 语义、时间结构等方面存在显著差异,这使得简单的跨模态参数共享会很容易导致优化不稳定和性能下降。
为了应对这些挑战,ERNIE 5.0 设计为在一个统一的自回归框架下从零开始训练。包括文本、图像、视频和音频在内的多模态输入被投影到一个共享的 Token 空间,序列化为一个统一的序列,并根据“下一组 Token 预测”(Next-Group-of-Tokens Prediction)目标进行优化。
具体而言:
- 文本生成:遵循标准的“下一 Token 预测”(NTP)范式,并辅以“多 Token 预测”(MTP)机制,以增强输出质量和推理效率。
- 视觉与音频生成:被表述为“一组 Token 预测”任务,从而将其生成过程与文本自回归目标对齐。
- 视觉生成:采用“下一帧与比例预测”(Next-Frame-and-Scale Prediction, NFSP),以捕捉空间和时间维度。
- 音频生成:利用“下一编解码预测”(Next-Codec Prediction, NCP)来捕捉时间及频谱结构。
注:MTP就是
Multi-Token Prediction(多 Token 预测),与传统的NTP下一个token的主要区别在于,一次可以输出多个token。
为了让模型学习到各个模态的知识,ERNIE 5.0 采用了MOE架构。
- 模态无关的专家路由:即路由决策是基于统一的 Token 表示,而非显式的模态标识符。这意味着,所有模态的token会共享参数。
- 稀疏架构:使用了无辅助损失的负载均衡,每个 Token 经过模型时,只有不到 3% 的参数会被激活。
- 理解与生成任务的互补性:多模态理解侧重于抽象和语义层面的概念,而生成则需要对细粒度的感知细节进行精确建模。采用用同一个 Backbone ,语义信号引导生成,而生成训练反过来又加强了细粒度的感知和对细节敏感的推理。
在ERNIE 5.0中,图像被视为视频的特殊情况(例如,单帧视频)。
视觉分词
为了支持跨空间和时间维度的自回归视觉建模,ERNIE 5.0 提出了下一帧与比例预测(Next-Frame-and-Scale Prediction, NFSP)。
在该范式中,图像生成被表述为“下一比例(scale)预测”问题,而视频生成则在此基础上进一步扩展了“下一帧预测”的维度。
注:这里经常做NLP的同学可能会有些疑惑。这里的比例(scale)指的是一段token,这段token是一个完整的图像,而下一帧预测也很好理解了,实际就是多段scale,加了个时间维度而已。
为此,我们首先训练了一个针对图像的因果 2D 多尺度分词器(causal 2D multi-scale tokenizer ),在此图像分词器的基础上,我们通过膨胀操作将其扩展为因果 3D 卷积分词器(causal 3D convolutional tokenizer),从而在单个模型中统一了图像和视频的分词过程。
注:
1. 分词器 (Tokenizer):这个好理解,就是把图片切成一小块一小块(Token)。
2. 多尺度 (Multi-scale):模型不是一次性看清所有细节,是类似先看缩略图(粗糙),再看局部放大图(精细)。对于生成,也同理,先画轮廓,再逐渐完善。
3. 因果 (Causal):它在处理图片像素时,只能看到之前生成的块。
4. 膨胀(inflate):即2D->3D,2D卷积只是图像,而膨胀相当于加了个时间的维度,这样就能处理图像了。
在分词器训练期间,我们引入了辅助监督信号以增强表示质量和训练稳定性。具体而言,我们利用基于 GAN 的判别器的对抗损失来提高分布保真度。
同时应用来自大规模视觉基础模型的语义正则化损失,以保持高级语义的一致性。
注:首先要明白,这个分词器,并非传统的文本分词器,有固定词表那种,而是要自己进行训练,寻找到一个合适的词表大小n(下面会有介绍),训练过程则是图片→token→图片这样的范式。其目的是如果该分词器,分为了m(m取自于n)个token后,还能靠m个token还原,代表分词器效果很好。
- 对抗损失:这是GAN(生成对抗网络)中的思想,即当分词器把图片变成 Token 再变回图片,会有一个“判别器”在旁边盯着,看它还原的的质量如何
- 语义正则化:是拿一个已经懂语义的大模型(如 CLIP)来校准,避免还原的效果虽然图像细节好,但含义改变。
采用按位量化(bit-wise quantization)策略,将统一的视觉潜变量表示量化为一组位代码,其中位的数量直接对应于离散词表的大小。
在 ERNIE 5.0 的训练过程中,我们采用了渐进式分词器切换策略:从低位分词器(即小词表)开始,逐渐过渡到高位变体(即大词表)。通过先学习小词表下的粗粒度低位表示,再逐步引入细粒度的高位分词器,有效缓解了早期训练的不稳定性,并提升了视觉生成的质量。
注:即初始时词表大小比较小,例如训练前期(低位,比如 4-bit)词表大小
具体结构图2⬇️所示
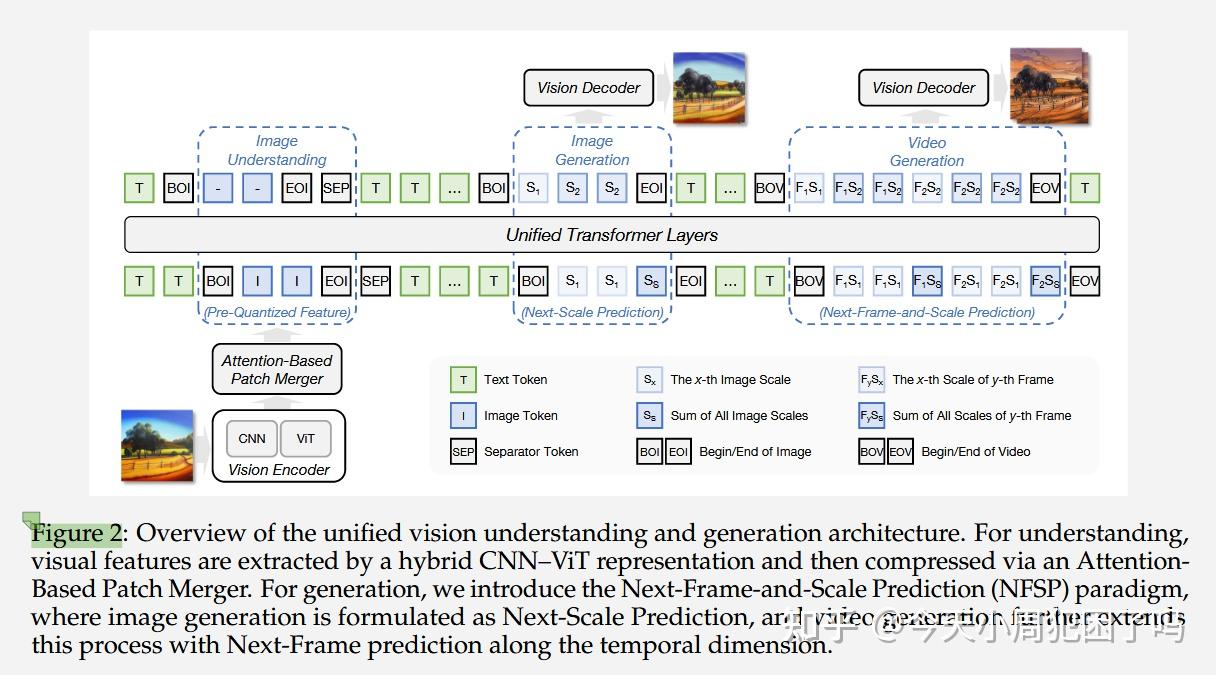
- 图像生成(中间部分):遵循 Next-Scale Prediction。图中的 分别代表图像的不同尺度(Scale)。模型不是一次性生成整张图,而是从粗糙到精细地预测不同比例的特征。
- 视频生成(右测):遵循 Next-Frame Prediction。图中标记为 ,表示第 帧的第 个尺度。每个帧相当于一个图像。
- 标记位:使用特殊的 Token(如
[BOI]/[EOI]代表图像开始/结束,[BOV]/[EOV]代表视频开始/结束)来界定视觉内容的边界。
视觉理解与双路径混合表示
由于经过了量化压缩,即图片转为token的词表大小是有限的,由于限制了此大小,图片转为token,会丢失一些细节,这会影响对图片的语义理解。
为了解决这一问题,ERNIE 5.0 直接利用量化前的双路径视觉特征。
我们整合了由卷积神经网络(CNN)提取的感知特征和由视觉 Transformer(ViT)编码的语义特征。由于这两条路径的维度不同,我们的研究表明,通过基于 MLP融合 CNN 和 ViT 特征,会引入表示干扰,导致理解性能下降。
这促使我们开发了接下来的基于注意力的补丁合并器(Attention-based Patch Merger)。
对于图像中的空间 Token 或视频中的时空 Token,我们提取两组特征:
和
其中 是最终输入到模型视觉 Token 的数量, 是每个 Token 的patch的数量, 和 是特征维度。
- 在图像理解任务中,我们将 个空间相邻的patch组合在一起。
- 在视频理解任务中,我们将跨越 4 个相邻帧的 个patch组合在一起。
在特征融合之前,我们先将 CNN 特征投影到 ViT 的维度,沿patch维度拼接,得到 。
接着,对拼接后的patch Token 应用多头自注意力机制:,输出保持相同的形状 。
最后在patch维度上进行均值池化,得到的表示 ,随后将其投影以对齐统一主干网络的嵌入维度。
注:这里是为了增强图像的理解能力,生成时仍然时是下一帧与比例预测,而对于图像的输入,则采用Vit和CNN特征融合的办法。
而由于输入的是patch(这里的patch和token均没有词表的概念,纯粹是vit和cnn的结果),模型需要token输入,输入的token数则为N,N*K其实是原始vit和cnn输入后得到的结果,拆成了N *K大小
基于下一帧与比例预测(NFSP)的视觉生成
模型在图像生成时预测每张图像(或每帧)内的多个空间比例(Scale)的视觉 Token;在视频生成时,则沿时间维度进行逐帧预测。
注:
组间自回归:模型先画Scale 1,再画Scale 2,以此类推。画 Scale 2 必须看 Scale 1,这就是因果。
组内并行:在画同一个 Scale时,这一层的所有 Token 是同时吐出来的,彼此之间能互相看见(双向可见)。
我们引入了统一时空旋转位置嵌入(Uni-RoPE),并将其应用于 ERNIE 5.0 中的所有 Token。
对于长度为 的统一序列,第 个 Token 的位置编码定义为 。
对于文本和音频 Token,我们设置 ,比较简单,就是一维序列,所以 序号。
对于视觉 Token, 用于帧索引(单调递增以保持时间顺序),而 对应于每帧内的空间位置。为了确保跨多比例的空间一致性,我们采用了中心对齐坐标策略,即不同比例的 Token 基于该比例的几何中心进行对齐。
注:为了让scale1里的具体图像(例如铅笔)和后续scale里的铅笔在同一个位置,把不同分辨率的图强行按中心对齐,防止模型画歪。
自回归模型最怕误差累积(一步错步步错),为了缓解这一问题,我们在训练期间通过随机翻转历史 Token 的位(bits)来破坏它们,同时监督模型向当前比例的Ground-truth Token 进行自我纠正。这种基于破坏的训练策略提高了模型对生成中对误差的鲁棒性。
注:Token 的位即上述提到的按位量化,假设词表大小为1024,每一个视觉 Token ID 都可以写成一个 10 位的二进制数(比如 )
自回归+扩散
在基于 Token 的建模范式中,提高视觉分辨率会增加序列长度,进而减小有效训练Batch Size并降低优化稳定性。为了应对这一挑战,我们在自回归主干之上采用了级联扩散精修器(Cascaded Diffusion Refiner)。
主干网络生成具有精确语义和结构布局的低分辨率样本,而精修器则专注于增强高分辨率下的细粒度视觉细节。
扩散精修器与主干网络分开训练,使用缩略图和高分辨图进行训练,实现了高保真度的精修,并避免了两个组合损失的训练冲突。
与视觉模态类似,ERNIE 5.0 中的音频建模也被表述在一个统一的、基于 Token 的自回归框架下。
音频信号被表示为层次化的离散编解码器 Token(Hierarchical Discrete Codec Tokens)
音频分词
给定输入波形,我们首先使用编解码器风格的分词器(Codec-style Tokenizer)将连续音频信号映射为离散 Token 序列,其 Token 频率为 12.5 Hz。(注:即1 秒钟的音频,最后只变成了 12.5 个 Token)
音频量化模块遵循残差向量量化(RVQ)设计,将信号分解为不同粒度的多个 Token,第一个 Token 被明确指定用于编码高层音频语义,而其余 Token 则编码具有逐层递进细节的残差声学信息。
注:高层音频语义指的就是音频的内容,它只存最核心的信息:说了哪些字、词的顺序、基本的发音。
为了确保第一个 Token 能够捕捉音频-文本建模的丰富语义信息,我们从预训练的 Whisper 模型中进行知识蒸馏。
具体而言,我们将第一个音频 Token 的表示与 Whisper 的编码器输出进行对齐。我们对 Whisper 的表示应用了均值池化,以匹配我们音频分词器的 Token 频率。
而其余残差Token 保留了音频信号的细粒度特征,如音色和韵律。通过这种层次化的分词过程,语义内容与声学实现得以解耦,并提供了一种紧凑的音频表示。
基于下一编解码预测(NCP)的音频理解与生成
基于上述音频分词,我们利用深度自回归架构对音频 Token 进行理解和生成建模,这借鉴了视觉生成中开发的从粗到精的预测范式。
ERNIE 5.0 并没有将所有残差音频 Token 展平为单一的长序列,而是将残差代码的预测分发到不同的 Transformer 层中。每一层都在特定的粒度级别上建模音频信息,这使得多级音频表示能够在统一框架内得到高效处理。
在音频理解任务中,文本 Token 使用标准文本嵌入层进行嵌入,而音频 Token 则通过深度加法嵌入机制进行表示。每个音频 Token 由对应不同残差级别的多个离散代码(codes)组成。在每个级别,代码通过该级别特有的嵌入矩阵映射为嵌入向量(embedding),然后将所有级别的嵌入向量相加,形成最终的编解码表示。
注:
这里的音频token,指的是由多个code组成,我们以一个token=8个code为例,这里说的是,将这8个code的嵌入向量,直接相加,当成一个token。这中code和文本的 Embedding 非常像,都是提前训练好的。
而不同残差级别指的是音频的细节程度,级别越高,信息细节越丰富,类似压缩率,一开始压缩率高,没那么多细节,之后压缩率越来越低
在音频生成任务中,ERNIE 5.0 引入了下一编解码预测(Next-Codec Prediction, NCP),以从粗到精的方式生成层次化音频 Token。我们在顶层的 Transformer 层中插入了多个音频头,以支持深度预测。模型首先预测第一个语义代码,然后顺次为后续的残差级别生成代码。
每次预测后,生成的代码被映射到其对应的嵌入向量,并加回到隐藏状态中,进而引导下一个级别的预测。对于语音合成,会插入一个说话人嵌入(Speaker Embedding)作为上下文的一部分,以实现可控的音色,在不改变深层语义内容或深度预测结构的情况下引导声学实现。
注:由于是8个code当作一个token,那么预测时,也是预测8个code,当作一个token,如果8个一起猜,模型很难学会,这里是分层猜,某个层取一个,取完后将嵌入向量加到隐层状态,到最后一层就取完了,输出token。而说话人嵌入也是一段向量,类似于音色风格,当你克隆音色时,每此生成语音,都会加入这段向量作为上下文。
训练时采用教师强制的方法,反馈信号是真实数值。
注:什么是教师强制?
由于生成时,后面的预测依赖于前面层的预测,一步错容易步步错。而教师强制则是,每次预测后就告诉它该层输出的标准答案,拿着答案去进行下一次预测。
其架构如图3所示⬇️
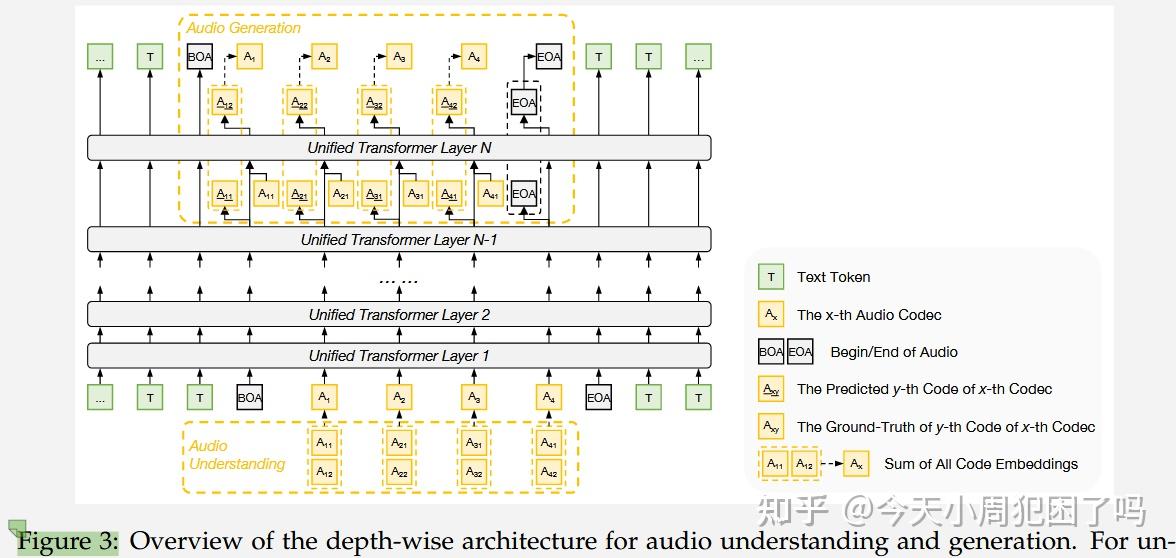
- 每一列代表一个时间点的音频 Token(比如 )。
- 注意看 下面挂着两个黄色实线方框 和 。
- 是第 1 层 Code
- 是第 2 层 Code
- 右下角图例写着:。这就是上面提到的累加为一个。
对于中间层的Token流向,即灰色的 Unified Transformer Layer:
- 最底下的输入行:
[T][T][BOA][A1][A2][A3][A4][EOA][T][T]。 [T]是文本。[BOA]是“音频开始”。[EOA]是“音频结束”。- 文本和音频 Token 在同一序列上。对于 Transformer 层来说,它不管是文字还是声音,统统当成向量来算注意力(Attention)。
音频生成,即上面标着 Audio Generation 的黄色虚线框,体现了分层预测的思想
先输出的,并作为输入进入了下一层,进而输出,最终成为一个token在最后一层输出。
ERNIE 5.0 在一个大规模、高质量的多模态数据集上进行训练,它从训练伊始就同时接触文本、图像、视频和音频。
为了管理这些多样化的数据,我们构建了一个标准化平台,并根据其输入和输出模态组织所有数据。基于此组织形式,预训练数据大致分为两类:文本数据和多模态数据。
文本数据: 文本组件涵盖了大量的多语言网页抓取、精选语料库、书籍、科学出版物、代码仓库和结构化知识源。我们采用 UTF-16BE 对文本进行编码,从而提高多语言训练中的数据吞吐量,同时使用 BPE dropout 来减少对频繁组合的过拟合。
多模态数据: 对于视觉和音频模态,我们策划了一个数据集,包含成对的图像-文本、视频-文本、音频-文本,以及多样的交错多模态序列(其中文本与图像、视频和音频集成在一起),所有数据均配有元数据和说明文字。
注:
UTF-16BE:统一字节,utf-8中文三个字节,英文一个。而
UTF-16BE 均为2字节,长度固定。当模型遇到不认识的字符时,它不需要纠结,直接按 2 字节一组去处理就行。
BPE dropout:将固定组合进行拆分。例如BPE分词对学习是一个词,而BPE Dropout有时会拆违学和习。
ERNIE 5.0 训练遵循多阶段预训练策略,旨在逐步扩展上下文长度,同时保持稳定的优化。
第一阶段:8K 预训练 初始阶段使用 8K Token 的最大上下文长度。在此阶段,我们采用了预热-稳定-衰减(WSD)学习率调度策略。
学习率在 2,000 步内从零线性预热到峰值 ,剩余时间内保持不变。
我们还采用了批大小(Batch Size)调度策略,全局批大小在训练早期从 14M Token 逐渐增加到 56M Token。
从 8K 阶段开始,RoPE 基数(Base)被设置为 1,000,000。这一设计选择避免了后续扩展上下文长度时进行重参数化或插值的需要,确保了无损且稳定的长上下文训练。
第二阶段:32K & 128K 中期训练 在训练中期,我们将上下文长度逐步扩展到 32K 和 128K Token,同时保持全局批大小不变。在此阶段,我们切换到余弦(Cosine)学习率调度,并将学习率从 退火至 。
MTP(多 Token 预测)的损失权重从 8K 阶段的 0.3 降低到中期训练的 0.1,以确保模型在向更长上下文过渡时能够稳定适配。
此外,我们引入了一种基于后验的损失重权化策略,将不同模态的自回归损失缩放到相同的区间,从而提高训练稳定性并防止模态间失衡。
虽然万亿参数模型很强,但是有时环境只允许部署小模型。
传统方法通常遵循“先训练后压缩”,采用剪枝、知识蒸馏等方法提炼小模型。
模型压缩需要一个专门的剪枝或蒸馏阶段,会产生巨大的计算开销。此外,一旦模型被压缩,其架构就固定了。创建其他尺寸的模型需要重复完整的压缩过程,从而限制了部署灵活性。
为了解决这些问题,我们提出了一种新型的弹性训练策略,并首次将其应用于 ERNIE 5.0。
弹性训练是在预训练期间同时优化一个子网络家族,使得单一的大模型能够根据需求高效产出较小的、可部署的变体。它将“一劳永逸(Once-For-All)”的设计哲学扩展到了预训练阶段,具有不同深度、宽度和稀疏度的子网络配置与全规模模型一起接受训练。
注:这里说的很像Matryoshka Representation Learning,embedding中的俄罗斯套娃训练。在训练过程中,除了总体参数训练,还会在某些step中随机只用其中一部分参数训练,等训练结束,这个模型就像一个俄罗斯套娃。想要小模型,拿出其中一部分参数即可。
弹性训练如图 4 ⬇️所示,它在三个互相独立的维度(深度、宽度、稀疏度)上引入了结构灵活性:
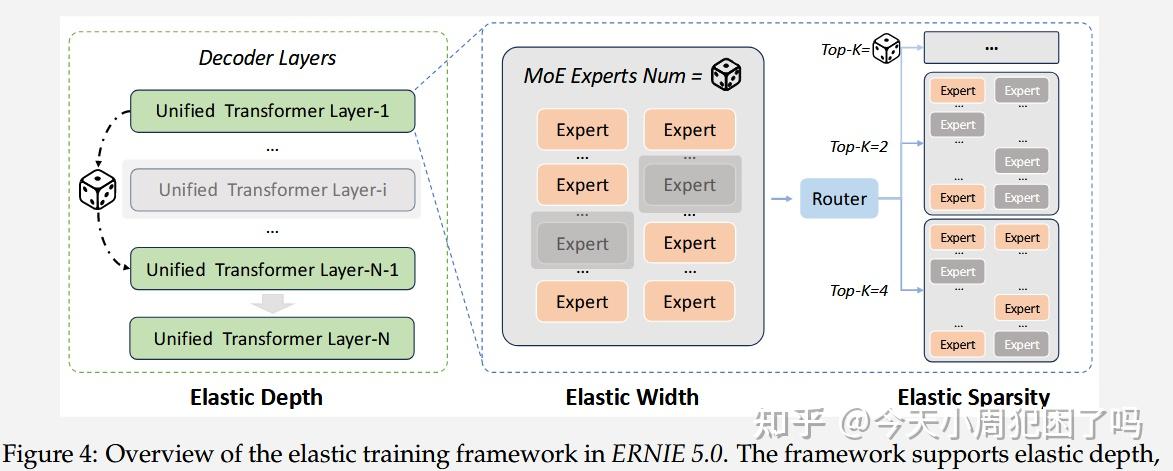
弹性深度(Elastic Depth) 为了支持弹性深度,ERNIE 5.0 在训练期间随机改变激活的 Transformer 层数,从而能够提取出具有不同深度的子网络。大多数时间(75% 的概率)使用全深度网络以确保所有层都得到充分优化;而有时(25% 的概率)会采样较浅的子网络,以培养模型对“层移除”的适应力。
弹性宽度(Elastic Width) 作为深度的补充,ERNIE 5.0 通过改变每个MoE层中的专家总数来支持弹性宽度。训练过程在两种模式间切换,而非总是激活全部专家池:以 80% 的概率让所有专家参与路由(全宽度);剩余 20% 的情况下,路由被限制在随机采样的专家子集中(窄宽度)
弹性稀疏度(Elastic Sparsity) 为了在不改变部署模型大小的情况下提高推理效率,我们引入了弹性稀疏度,即改变每个 Token 激活的专家数量。训练期间 80% 的概率应用默认路由配置,20% 的概率从预定义范围内随机采样 Top- 值( 小于标准配置)。
通过训练一个弹性“超级网络”,ERNIE 5.0 能够通过在层数、专家总数和激活专家数三个维度选择参数子集,产出各种配置的小型模型。隐藏层维度(即宽度)的弹性是未来可扩展的方向。
我们遵循与 ERNIE 4.5 相同的后训练流水线来获得最终的 ERNIE 5.0,这包括两个阶段:监督微调(SFT)和统一多模态强化学习(UM-RL)。
ERNIE 5.0 的 RL 训练面临几个挑战:
- 计算极其昂贵,ERNIE 5.0 的巨大规模进一步放大了这一问题。
- 超稀疏 MoE 架构加剧了训练与推理之间的差异,破坏了稳定性。
- 与数学推理或代码生成等单项 RL 任务相比,训练一个同时支持多种场景和模态的模型,复杂度显著更高。 针对这些瓶颈,我们实施了一套协同的工程和算法优化。
在 RL 中,Rollout占总训练时间的 90% 以上,其效率通常受限于响应长度的长尾分布。
注:这确实是各大技术报告都在解决的一个问题,目前RL只有两个问题,1是采样,2是环境。
U-RB:无偏重放缓存生成 我们引入了 U-RB,如图 5 ⬇️所示,U-RB 构建了两个模块:
- 高吞吐推理池 ():容量为训练批次的 倍。
- 训练池 ():收集完成的轨迹用于 RL 训练。
在迭代 时,推理引擎并行生成采样。推理一直持续到当前数据组 中最长的那个采样输出完。
此时, 相关的所有采样从推理池移至训练池,由训练引擎更新参数。通过这种动态划分,U-RB 既防止了因个别长样本导致的计算空闲,又保持了无偏的数据分布。
注:这里是减少GPU的等待时间,
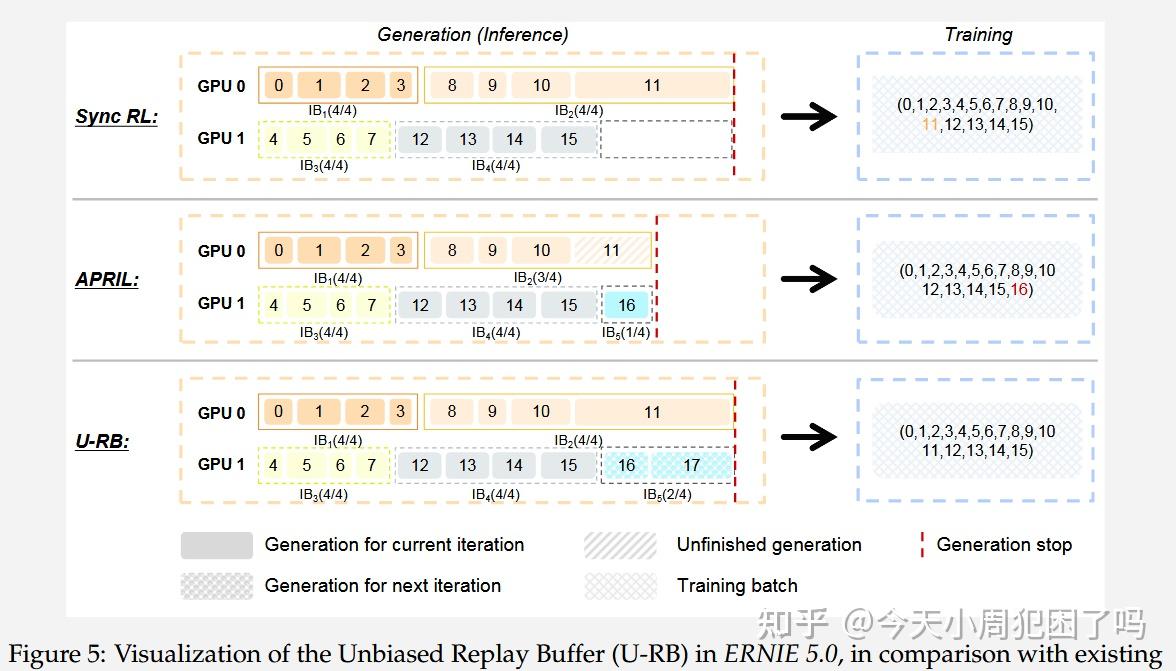
这张图对比了三种强化学习(RL)采样的策略,核心是解决快显卡等慢显卡的算力浪费问题。
- Sync RL:
- 显卡 1 很快采样完,但显卡 0 还在采样长的回答,显卡 1 只能等待。图中白色方框即为文心一言 ERNIE Bot 教程等待时间。
2. APRIL:
- 显卡 1 发现显卡 0 太慢,就不等了,直接把长题目(11号)扔了,拉了一个新题(16号)进来。 虽然显卡没闲着,但它逃避难题,模型永远在练简单的短题目。
3. U-RB :
- 它规定必须等长题目(11号)写完。但在等待期间,显卡 1 并不闲着,而是提前去写下一轮的作业(16、17号,图中蓝色块)。
多模态模型容易出现熵崩溃现象,表现为在 RL 早期阶段策略熵的剧烈波动,并表现出明显的模态偏好。
近期研究将熵崩溃归结为两个因素:
- 数值不一致:现代 RL 框架依赖独立的训练引擎和推理引擎,这引入了数值计算的不一致性,导致策略优化不稳定。对于 MoE 模型,动态路由进一步放大了这种数值失配。
- 过拟合简单查询:在训练早期,模型往往会过拟合简单的请求,这加速了熵崩溃并限制了模型发现其他推理路径的能力。
注:熵代表可能”或多样性。熵崩溃就是模型变傻了,输出比较死板
训练和采样的框架差异,以及off-policy路由专家的差异,均是目前RL的主要问题。
为了解决这些问题,我们引入了多粒度重要性采样裁剪(MISC)和已掌握正样本掩码(WPSM)。
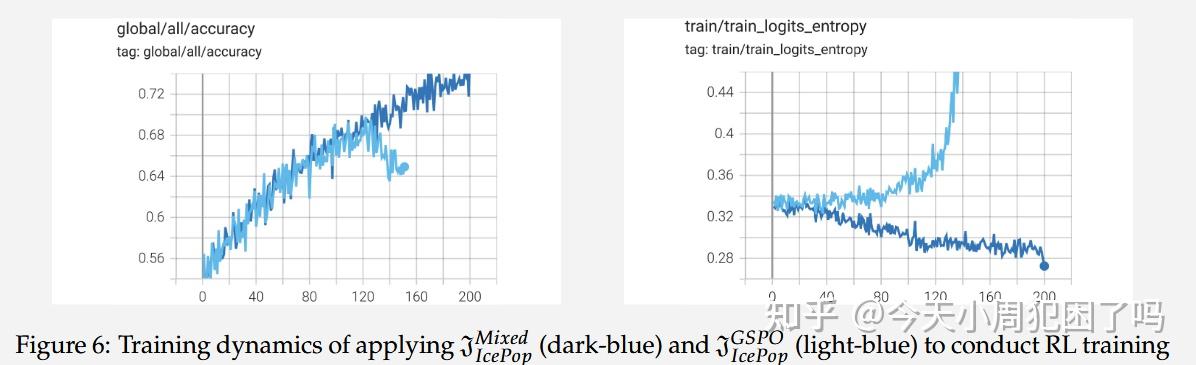
MISC:多粒度重要性采样裁剪
IcePop(Ling-Team et al., 2025)通过在 GRPO上进行双边掩码校准来抑制训练-推理失配:
注:什么是双边掩码校准?
即如果两个引擎算出来的概率差别太大,我就认为这个样本不好,直接不练了。
双边指的就是那个区间
其中 控制上下限。我们将此技术应用于 GSPO(注:LongCat-Flash-Thinking-2601 Technical Report中使用了GSPO):
但在 ERNIE 5.0 的 RL 训练中直接应用 会导致策略熵迅速崩塌(如图6中浅蓝色线所示)。
这一现象是由序列级阶段性重要性采样引起的,它会因为训练-推理失配而剪除大量低熵响应。为了解决这个问题,我们将 修改为 :
注:阶段性重要性采样是什么?
首先你需要知道GSPO的思想,它不是一个词一个词地算奖励,而是把一整句话(序列)作为一个整体,并且进行归一化处理。详细思想我会出一个论文讲解。假如GSPO使用双边,会出现大量样本丢失的问题,因为只要一个token偏离了区间,整个序列都会丢掉。
将一组样本丢弃的策略改为了单个token
注:其核心更改在于
WPSM:已学优样本掩码
我们引入了一种样本掩码策略,以防止模型在已经掌握的查询上过度优化,其中查询的熟练程度通过维护每个查询的胜率来跟踪。
对于给定查询 及其采样组 ,如果在迭代 中平均准确率 超过阈值 ,且当某个响应 的策略熵 低于稳定边界 时,我们将其标记为“已学优”响应。
在训练期间,“已学优”响应按如下方式掩码:
在这种设计下,梯度预算被转移到更难的样本上,例如具有稀疏奖励或多样化推理路径的样本。
注:其实就是对于已经学会的问题,没必要再分配很多算力去学了。
当所有采样收到的奖励均为零时(即全做错了),GRPO 无法为优化提供有效的梯度信号。在这种情况下,针对难题的 RL 训练往往进展缓慢,因为稀疏奖励(sparse rewards)和有限的样本效率阻碍了学习。
为了应对这一挑战,我们提出了自适应基于提示的强化学习(AHRL),这是一种缓解难题上稀疏奖励问题的方法。
如图 7 所示⬇️,AHRL 引入了部分提示(partial hints),将复杂问题分解为中间步骤,并逐步提高训练模型的性能。具体机制描述如下。

AHRL:自适应基于提示的强化学习
AHRL 是在 RL 训练期间向查询(queries)中注入了思考引导,将问题分解为多个步骤,AHRL 增加了模型生成正确响应的可能性。
对于给定的查询 ,其响应由思考轨迹和最终解决方案组成,表示为 。
AHRL 将 增强为 ,方法是将思考轨迹的前 个token加到原始查询中。
表示给出的思考引导token占整个思考过程的比例, 的概率遵循退火策:
其中 是训练迭代次数, 是衰减率, 是在 SFT 模型上评估的查询 的 pass@k 分数。
随着训练的进行和模型性能的提升,揭示提示的比例逐渐减少,使模型过渡到完全的自主探索。
注:假如
图7演示了一个困难问题的引导过程:
- 问题:一个关于正 24 边形的复杂几何组合题
- 为了让模型能起步,在题目后面人为地加了一截思考过程(Think Skeleton)
- 黄色高亮部分:在
<think>标签里,系统预先写好了推理的开头几步: - “题目要求是……”
- “我需要找到……”
- “既然是正 24 边形,所有顶点在圆上是均匀分布的……
ERNIE 5.0 的训练基于 PaddlePaddle(飞桨) 深度学习框架。
在 ERNIE 4.5 的基础设施基础上,我们进一步解决了由原生多模态训练、超稀疏 MoE(专家混合)模型以及大规模强化学习(RL)管线带来的独特挑战。
注:这部分内容均是一些张量并行的优化,我个人认为大部分人很难去训练这么大参数的模型,TP,PP,EP,CP,zero-1全用了,这太复杂,加上原文这部分比较简略。故第五章和第六章均略。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/270100.html原文链接:https://javaforall.net


