
在25年的当下,大模型中一个技术关键词正变得越来越火:MoE(Mixture of Experts,混合专家)。Moe的显著优势时所需的计算资源远少于Dense模型,有着更快的预训练速度和推理速度。MoE 就像“组团打怪”的AI结构,让超大模型又强又省!
随着 Meta 发布 Llama 4-MoE、DeepSeek 推出 DeepSeek-V3-MoE,以及阿里开源的 Qwen 3-MoE,几乎所有主流 AI 实验室都在将 MoE 作为新一代大模型的核心架构。月之暗面的 Kimi K2 也凭借其 1 万亿参数 MoE 架构强势出圈,成功挑战了 GPT-4 等闭源旗舰模型。
kimi k2总参月之暗面 Kimi 教程数量为1T,实际激活参数量为32B。模型层数共有61层,其中1层Dense,60层Moe层,每一层moe层有384个路由专家,1个共享专家。上下文长度128K。
关键特点:
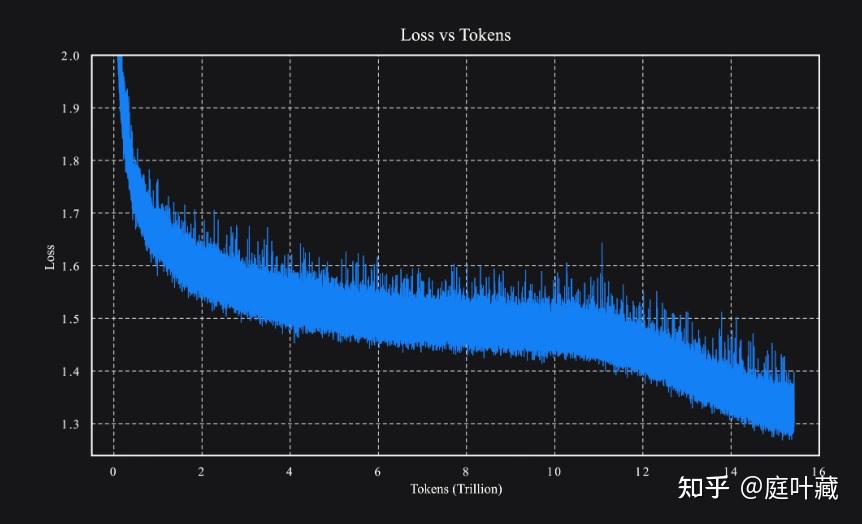
- Large-Scale Training:使用了15.5T的token数据量稳定训练了1T参数量规模的Moe大模型
- MuonClip 优化器:使用了MuonClip优化器代替现在广泛使用的Adam优化器
- Agentic Intelligence:目标成为工具调用,任务完成的Agent智能助手
官方已开源模型至huggingface社区,提供了两种模型。模型权重链接为:https://huggingface.co/collections/moonshotai/kimi-k2-b990f2af5ba60617d
- Kimi-K2-Base:基础模型,可供研究者等进行细分领域的微调等任务
- Kimi-K2-Instruct:后训练模型,适用于对话等任务
kimi k2模型使用了MuonClip优化器,支撑了15.5T token数据量的1T参数量大模型稳定训练,关于优化器可参考https://kellerjordan.github.io/posts/muon/。

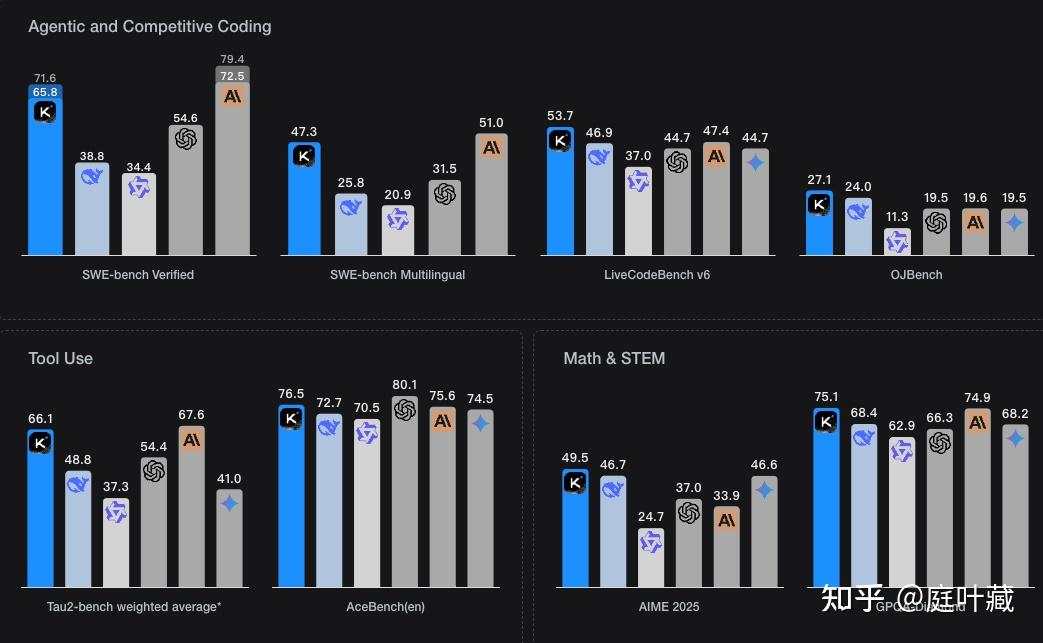
kimi k2在数学、编程和工具使用等领域内,性能优异,超越Deepseek、Qwen3等开源模型,在某些任务上性能接近Claude 4,GPT4等闭源大模型。
在多项Benchmark中也取得了优异成绩,列举如下。
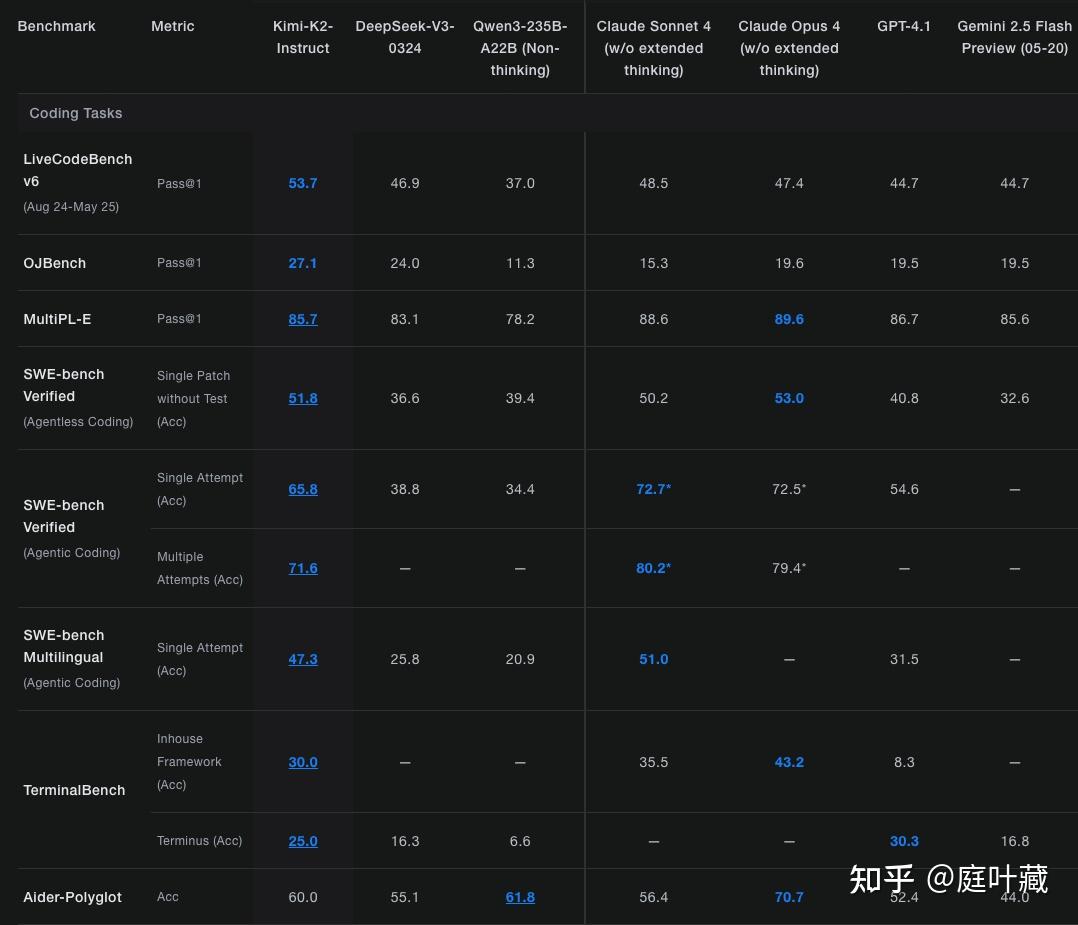
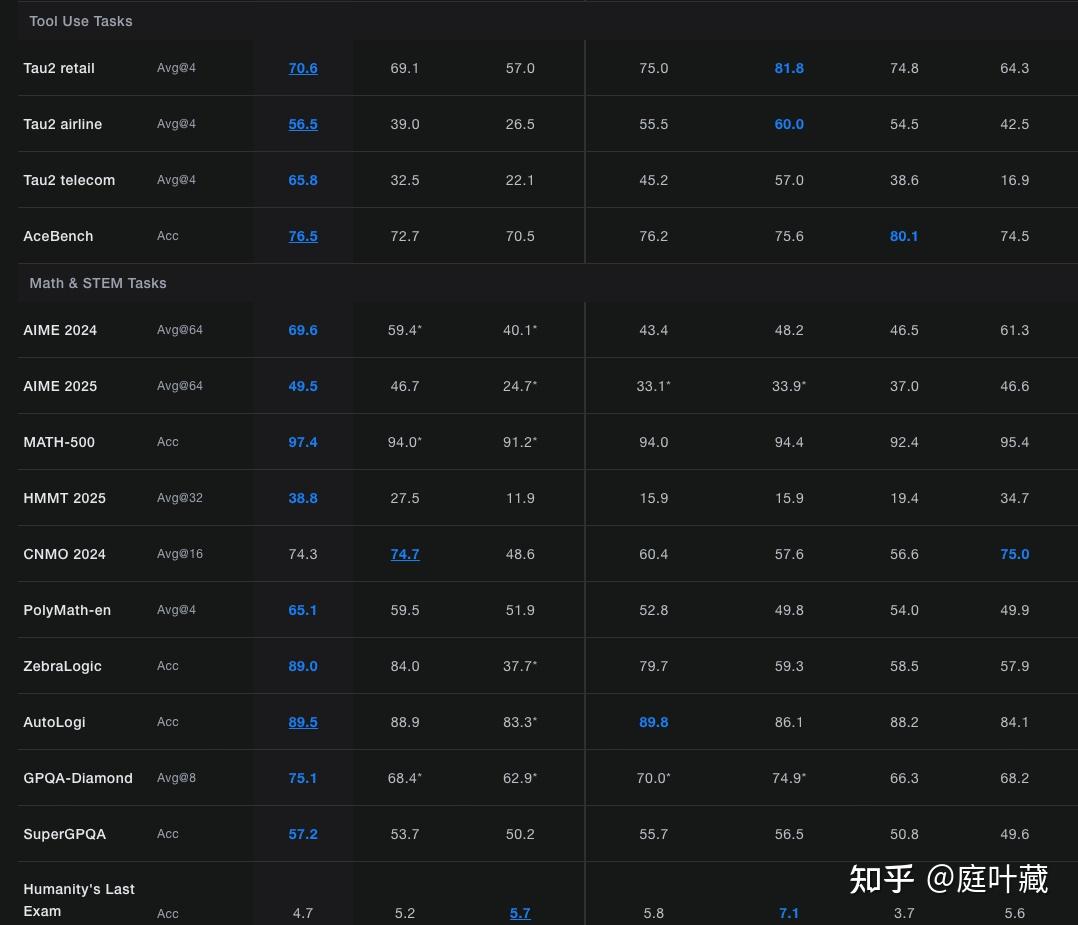
详细数据在k2技术报告中,技术报告链接:https://moonshotai.github.io/Kimi-K2/
技术报告中也给出了agent智能的使用case,分析数据的案例部分如下,流程较多,具体的可以查看技术报告。
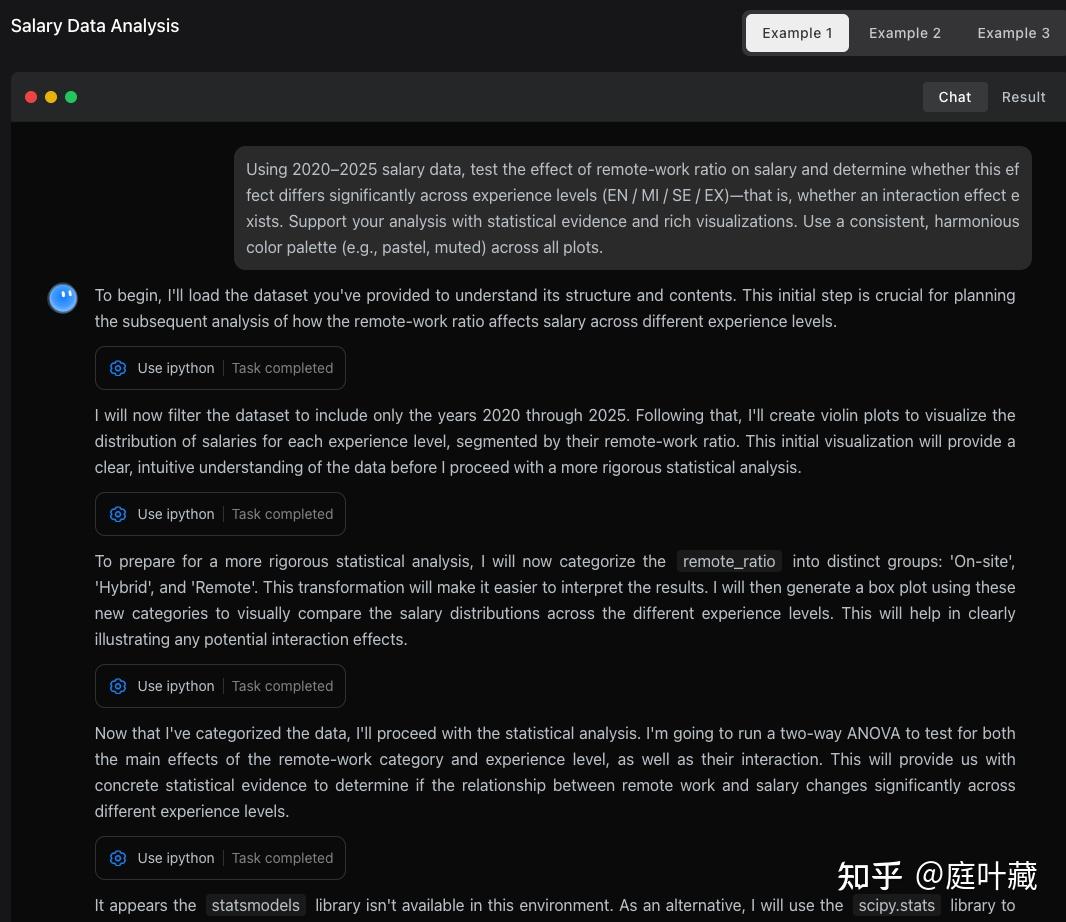
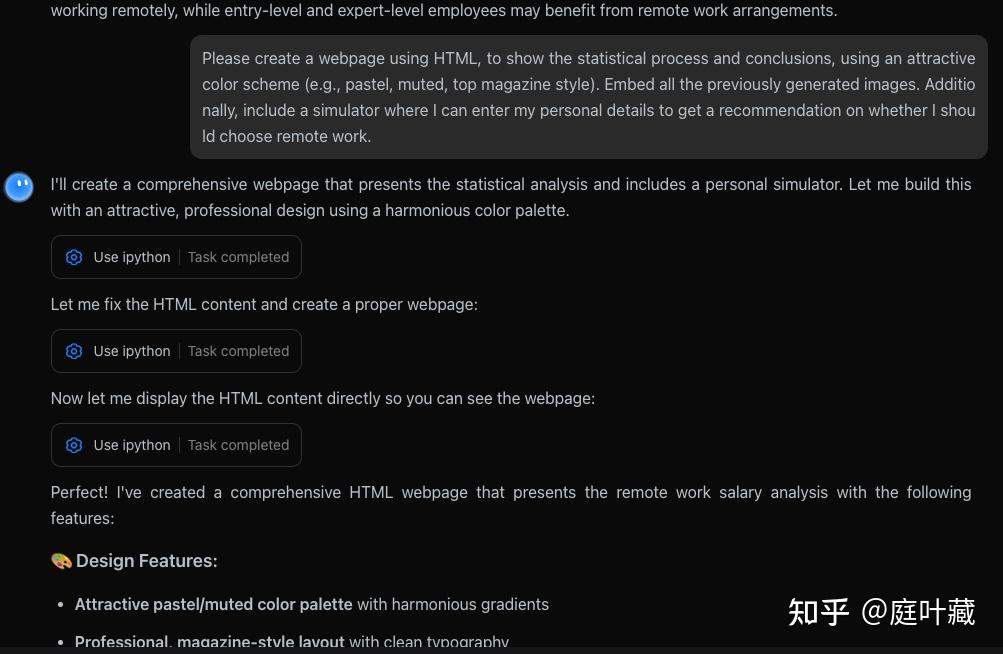
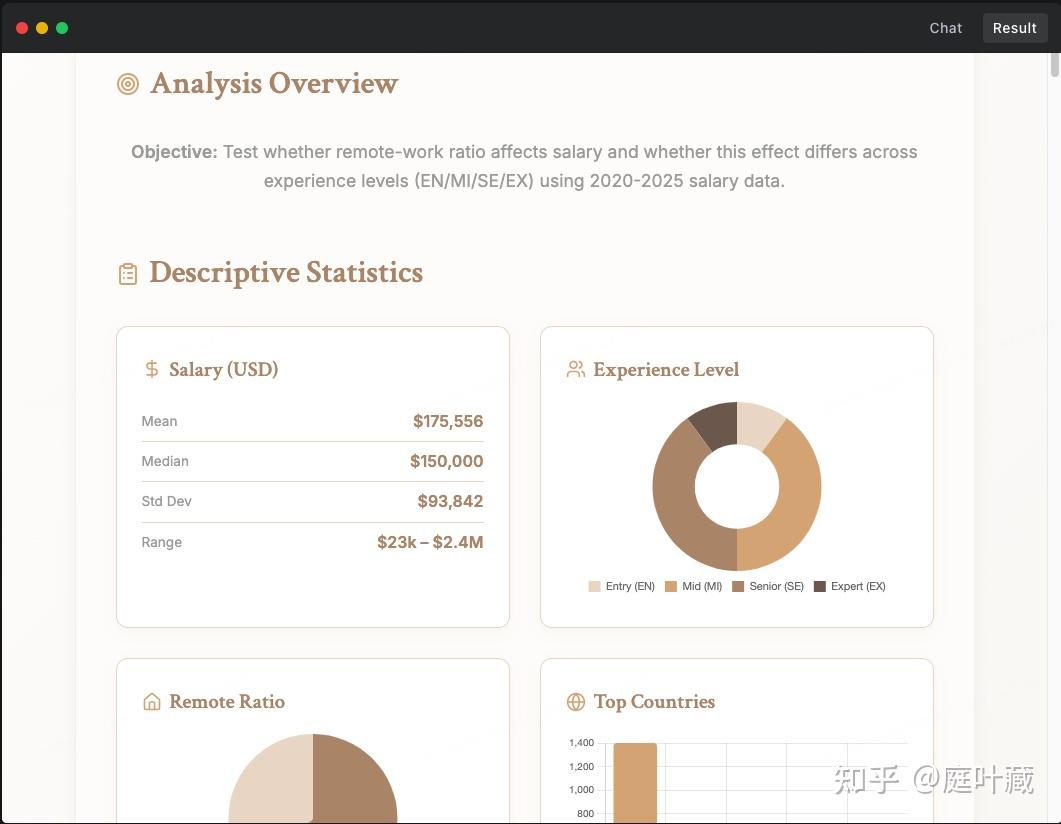
技术报告也显示了最终的结果html:
kimi k2支持主流推理框架:vLLM,SGLang,TensorRT-LLM等,部署可参考官方仓库https://github.com/MoonshotAI/Kimi-K2?tab=readme-ov-file#4-deployment
同时kimi k2在技术报告中指出,仍存在不足。在处理困难的推理任务或者不明确的工具定义时,模型可能会生成过多的token,导致输出阶段或者工具调用不完整。以及,如果开启了工具使用,某些任务的性能会下降等,他们正在解决。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/270897.html原文链接:https://javaforall.net


