
2025年10月31日,月之暗面在著名社交媒体平台“X”的官方账号上宣布月之暗面正式上线了一个超有革命性的技术——“Kimi Linear”混合线性注意力架构。这一架构一经推出,就引发了行业内外的广泛关注,难道它真能颠覆传统的Attention机制吗?和传统全注意力方法相比,它在多个场景下都展现出了明显优势,这无疑是一场技术上的激烈碰撞。
在人工智能发展得如火如荼的当下,提升模型的处理能力和效率成了行业内的关键挑战。月之暗面此次上线的Kimi Linear架构,就像是一把钥匙,为解决这一难题带来了新的希望。

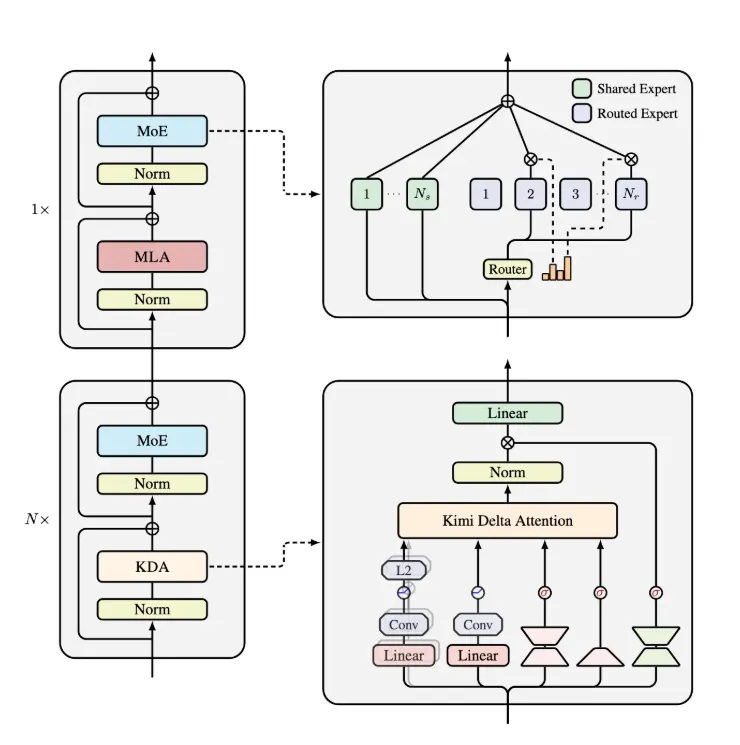
Kimi Linear架构的核心创新在于“Kimi Delta Attention”(KDA),它可是对Gated DeltaNet进行了升级至更优版本。它引入了更高效的门控机制,就好比给递归神经网络(RNN)的记忆装上了一个智能开关,能大大提升有限状态RNN记忆的使用效率。
有专家指出,这种高效的门控机制在处理复杂信息时,能够更精准地筛选和保留关键内容,避免无效信息的干扰,从而让模型更加“聪明”。
Kimi Linear的架构设计十分独特,它由三份Kimi Delta Attention和一份全局MLA(多层感知机)组成。通过对Gated DeltaNet的改良,KDA能通过细粒度的门控机制,显著压缩有限状态RNN的记忆使用。
这一设计带来的好处可不少,不仅提高了模型处理信息的速度,就像给汽车换上了更强劲的发动机,让它在信息高速公路上飞驰;还有效减少了内存占用,节省了宝贵的计算资源,具有更强的实用性。
官方给出的数据十分惊人,在处理1M token的场景下,Kimi Linear的KV cache占用量减少了75%。这意味着什么呢?就好比原来需要一个大仓库来存储物品,现在只需要一个小房间就够了,大大节省了空间。同时,解码吞吐量最高提升了6倍,处理信息的速度大幅提升。
在TPOT(训练速度)的提升上,相较于传统MLA,Kimi Linear实现了6.3倍的加速。以下是一组简单的对比数据:
月之暗面 Kimi 教程
这些显著的性能提升,预示着Kimi Linear在各类AI任务中有着广泛的适用性,尤其是在对速度和内存要求极高的应用场景,比如实时语音识别、大规模文本生成等。
随着人工智能技术的不断进步,像Kimi Linear这样的创新架构不断涌现。它为提升模型处理能力与效率提供了新的思路和方法,未来很有可能会成为新的行业标杆。
Kimi Linear技术报告的详细信息,可以通过官方的GitHub页面获取,感兴趣的读者可以深入了解其技术细节。说不定在研究的过程中,你还能发现更多隐藏的惊喜,为AI技术的发展贡献自己的一份力量。
技术报告链接:https://github.com/MoonshotAI/Kimi-Linear/blob/master/tech_report.pdf
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区
AITOP100平台官方交流社群二维码:

发布者:Ai探索者,转载请注明出处:https://javaforall.net/271395.html原文链接:https://javaforall.net


