
#1 前言
对于首次阅读视觉理解测评系列的读者,关于本测评的创立背景,请参考4月榜单
4月作为视觉理解系列的开篇,本身具有探路性质,题目仅有15题,其中一些题目各模型得分分布并不均匀,最终体现在分数上则是中腰部拉不开差距。各模型频繁暴露诸多问题,如模型能力偏重文字识别,物品和场景识别,但在空间想象,图像层次,空间逻辑等方面的能力捉襟见肘。
在题目设计上,将考察维度划分为3个层级:
1)第一级,考察大模型看到的能力,能准确完整识别图中出现的各种元素。
2)第二级,考察大模型看懂的能力,在看到的基础上,理解各个元素的现实内涵,能结合上下文对看不见的部分做合理推测。
3)第三级,考察大模型拟人的能力,以人类具备的视觉能力为基准,考察大模型在想象,联想,空间感,预测等方面与人类的接近程度。
目前题目偏重考察第一级和第二级,少量考察第三级。随着未来多模态模型的进步,将逐步提高第三级考察题目的占比。
#2 参赛选手
本月新增:
豆包1.6系列
Step-R1-V-Mini 0606
Claude Sonnet 4系列
Hunyuan-turbos-vision & t1-vision 0619
GLM-4.1V-Flash
出榜模型:
Doubao-1.5-thinking-vision-pro(后继1.6系列)
Sonnet3.7系列(后继Sonnet4)
Step R1 mini(后继0606)
#3 题目和打分
题目使用的输入图像全部由笔者本地创建,使用1024*1024分辨率(或等效像素面积的图形),使用矢量图形编辑器,输出无损PNG格式。
1、不同尺寸文字识别:只测试中文
2、不同尺寸手写体识别:只测试中文
4、菜单识别:基于图片菜单的多个子问题
5、国旗识别:大量无规则堆叠的国旗,确保露出关键特征
6、色盲测试:模拟色盲测试图,要求识别图中信息
7、面积计算:计算二维网格中若干多边形的面积
9、拼图:给若干有尺寸标注的拼图,要求拼成指定图案
10、移动规律:识别参考图中物件移动规律,求指定物件应用规律后的位置
12、物体着色:识别参考图中物件和颜色的关系,求指定物件的颜色
13、原型稿转静态HTML
14、App截图转静态HTML:要求复现所有UI细节
15、动效原型稿转HTML:要求实现所有动效
17、线段计数:识别不同粗细、间隔、颜色的线段数量
18、找不同:找出给定2幅图的所有不同之处
19、对角线长度:计算由若干正方形构成的不规则物体指定对角线长度
20、复杂设计图的HTML实现:提供充满设计细节的稿,要求准确还原布局,配色,样式等
21、图文混排问答:提供图文混排内容,回答多个推理问题
22、【New】表格识别:识别表格数据并进行综合理解
24、【New】图形变换规律:识别给定几组输入的图像变化规律
25、【New】综合文字识别:识别各种形式的文字
本月淘汰:
3、残缺文字识别(放进#25里)
11、无提示规律识别(放进#24里)
打分规则:
1、模型优先使用官方推荐的温度值(下文有备注),如果没有推荐,则使用默认温度0.1。推理模型限制思考长度30K,输出长度10K,无法分别设置的模型,设置总输出为40K。非推理模型设置输出长度10K。模型支持的MaxToken达不到上限,就按模型上限。其他参数按模型默认。
2、每道题有至少1个得分点/用例,回答每正确一点即得1分。最终得分是得分除以得分点总数,再乘以10。(即每道题满分10分)
3、部分题目有额外扣分项,通常是标注在图片上的额外要求,如果不遵守即扣分。
#4 成绩解析
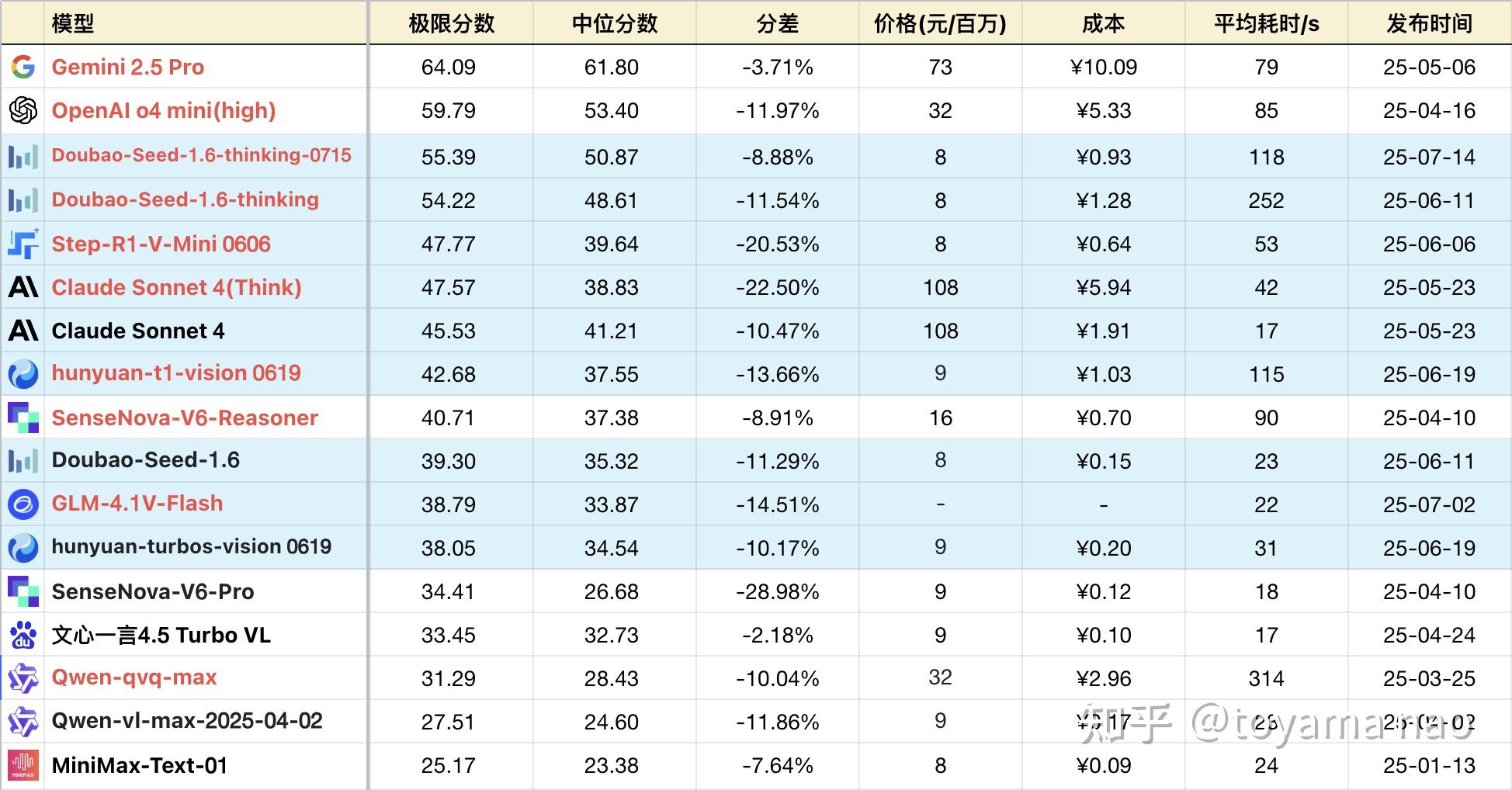

1-21题的解析可参阅4月和5月榜单,此处不赘述。下面是各模型在新增的#22、#24、#25三题上的表现。
1)#22表格识别是一道较为基础的题目,模拟真实使用场景,输入较模糊,但人能辨认的表格图。各模型在此场景有较为充分的训练,豆包1.6推理系列,o4 mini,Gemini 2.5 pro都是轻松满分。Sonnet4系列位列第二,识别错误一部分数字。智谱的新模型4.1V识别没问题,但智力较低,在后续的算数和推理上全部错误。腾讯的turbos错误较为意想不到,他将表格的行当做列,按行求平均,被当做按列求,并且计算也是错的。他家的T1推理版本也带着一些基础错误,无法满分。
2)#24是原先#11题的“降配版”,原#11题几乎只有o4 mini能少量得分,其他模型大面积交白卷。优化后的#24题核心仍是考察模型对抽象图形的空间位置规律的把握。需要在准确识别形状的基础上,基本图形推理能力。o4 mini对简化版自然是轻车熟路,拿到满分。Gemini 2.5 pro也基本看懂了图片,但在组织语言描述规律上吃了亏。以下的模型要么看不懂题目要求,要么看到的是“无规律”图形,找不到规律。
3)#25则是#3的“升配版”,原#3主要考察残缺文字识别,但实测发现各模型对这类场景训练充分,一些文字即便只剩偏旁,人也很难识别,大部分模型依然能轻松辨认。升级之后模型涵盖了几乎所有对汉字的变形处理,不限于翻转,旋转,镜像等。升级后的题目成为大部分国产模型的梦魇,勉强识别一半的字。而得分最高的是Gemini 2.5 pro,几乎满分, 除了漏掉一个充当背景颜色接近白色的单字。而Sonnet4系列对汉字识别属于知识盲区,相关问题得分都偏低,此题也不例外。而腾讯的turbos和t1虽然在图像推理方面表现差强人意,但文字识别意外的强,在此题上得分也不低。
#5 总结
时至25年年中,各类视觉理解模型的纯视觉推理能力还未出现能力跃升,属于视觉理解的o1时刻还未到来。不过这不代表当前的视觉模型没有用武之地,在特定任务领域,如图生HTML,国产模型也在快速追赶着国际一流水平,豆包1.6系列的HTML产物可用性已有较大提升。如果是图文混排,或是给图的同时,附加较为充足的文字说明,大模型也能图文结合,给出更好的输出。在一些PPT任务中,此项技能也可堪大用。
目前视觉理解月榜保持双月更新,下一次更新会在9月中旬。但如果期间有重磅模型更新,也会单独发评测文章。下一次更新计划继续调整题目,设计更多贴近实际的场景。
目前所有评测文章在公众号:大模型观测员 同步更新。
月榜的数据原始表格同步在Github
发布者:Ai探索者,转载请注明出处:https://javaforall.net/271591.html原文链接:https://javaforall.net


