
例如,一些主流的文本转图像模型如DALL·E 2,stable-diffusion和Imagen采用了扩散模型(Diffusion Model)作为图像生成模型。那么Midjourney用的是什么模型?
应该是调优后的stable-diffusion
MidJourney是一款基于深度学习技术的AI绘图软件,其底层模型采用了变形注意力GAN(Deformable Attention GAN, DAGAN)和针对线稿生成的改进型条件变分自编码器(Improved Variational Autoencoder for Line Art),并结合了前沿的计算机视觉技术和图像处理算法。
其中,DAGAN是一种在生成对抗网络中引入变形注意力机制的模型,它可以生成更加丰富、真实的图像,并保留了原始线稿的细节和特征。而改进型条件变分自编码器则专注于处理线稿,通过线稿预测图像的方式生成图像,使得生成结果更加准确,还可以通过对输入线稿加噪声的方式实现风格化效果。
此外,MidJourney还采用了多尺度、多层次的网络结构,充分利用了GPU等硬件设备的优势,提高了训练和生成效率,在保证图像质量的同时实现了较快的反馈和响应速度。
总的来说,MidJourney采用了目前最先进、最优秀的深度学习模型,结合了多种图像处理和创作技术,可以实现高效、高质量的图像生成和绘画,为用户提供了全新的创作空间和体验。
先让我们欣赏一波MidJourney生成出来的各种类型震撼图片吧!(不用科学上网,直接使用国内接口站,然后按照各种公式模板,选择相应的变量词,纯中文简单快速的生成你内心中真正想要的图片。)








当下,国内为数不多的一款关于MidJourney的在线查询字典已经出来了,叫《MidJourney零基础教学:在线提示词查询字典》同样适合Stable Diffusion),分为中文提示词版本(只适合国内接口站),还有一个中英文提示词版,适合MidJourney官网和国内接口站。
哪怕就是1个10岁的孩子拿到这本在线字典,只要套入里面的公式,也能简单、快速的生成出他想要的各种类型图片。具体的可以看一下这个知乎文章。
互联网前沿资讯:MidJourney零基础教学:在线提示词查询字典(中文提示词版,同样适合Stable Diffusion)来了
Diffusion 是当前主流的图像生成算法内核,Mid-Journey, DALL.E2, Stable diffusion 的内核都是Diffusion 算法。
我们把近10年的图像生成算法做一个发展分析,大概下面的这样一张图,可以说在未来2-3年内,diffusion 算法仍然会占据主流的算法内核,把我们带向更广阔的领域。
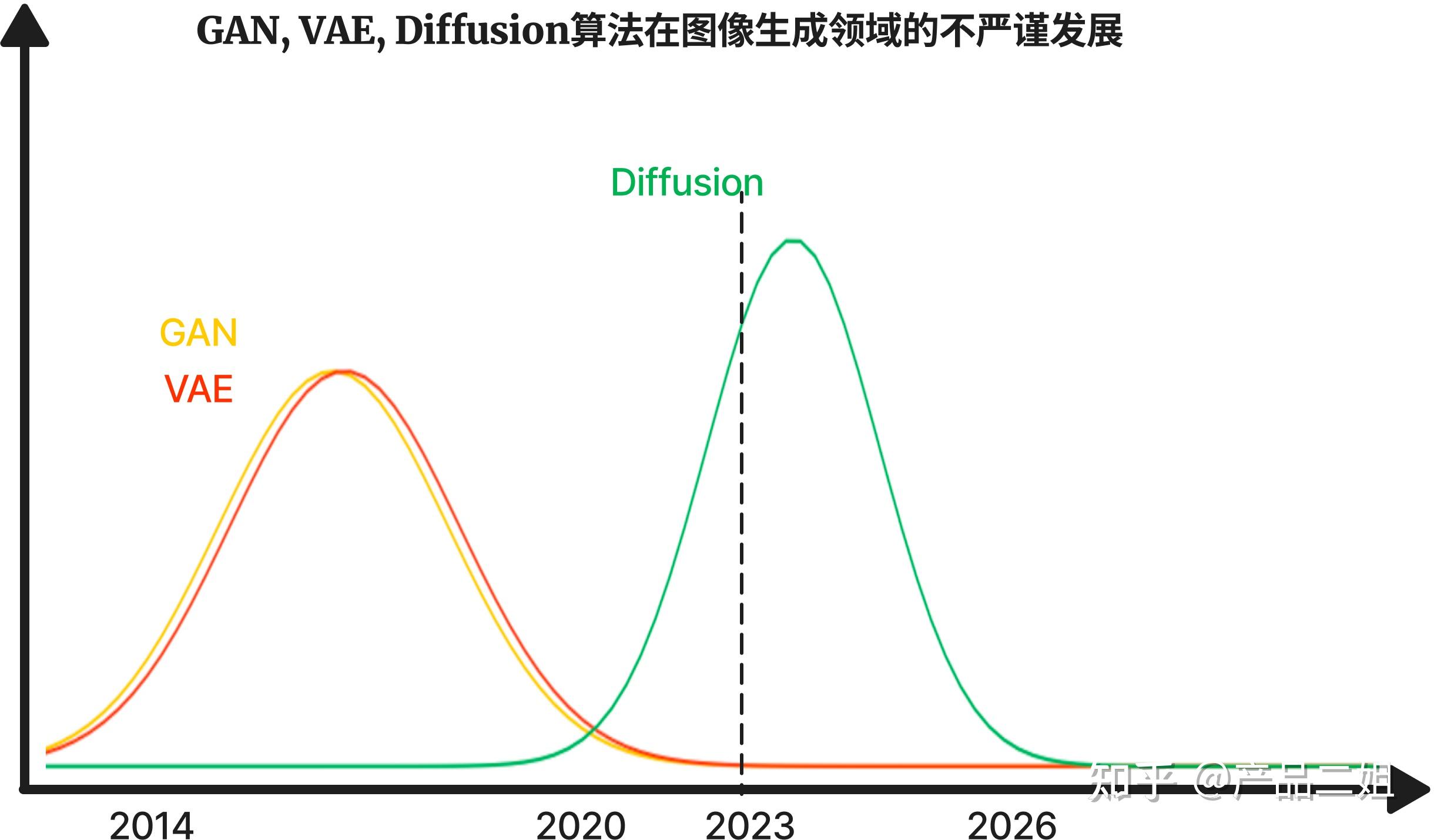
阶段1(2014-2020):
以GAN+ VAE 主导图片生成算法
- GAN: 参见上一篇文章中,GAN在2014年之后,吸引了众多学者的注意,对GAN进行了非常多次的改进。
- VAE: VAE 是也是在2014年提出来的,参见论文, 后来被多次改进,其改进版本VQ-VAE被用在Open AI的文生图产品DALL.E 1 当中。
阶段2: (2020年-至今)
在2020年左右,一篇论文《Diffusion Models Beat GANs on Image Synthesis》(在图像生成上Diffusion 打败GAN)发表,使得Diffusion 成为新宠。按照过去的发展来看,diffusion 模型还可以发展两三年。

Diffusion(扩散)概念源于非平衡统计物理学的概念,想象你把一颗糖块放进水里,随着时间流逝,冰糖会慢慢融入水中,“糖分子”会均匀分布在水中。那么如果我们学会了糖分子是如何扩散的,然后把这个过程反过来,让糖分子按照原来的方式再汇聚,就可以得到一块冰糖。
当然现实中,我们是无法让时间倒流,但是计算机却可以,这就是Diffusion 算法的原理:
先训练模型学会如何扩散,使用时给模型一杯糖水,让模型重构“糖块”,当然这个重构的糖块和原有的糖块并非一模一样,但也能表达出类似含义,所以扩散模型= 扩散 + 反扩散。
用更多的方式理解:
- 扩散算法也是:“编码” + “解码”的过程,通过编码训练好模型,解码的时候用训练好的模型解码。
- 扩散算法也阐释:“解铃还须系铃人”的道理。
那么扩散算法到底是如何进行“训练”和“重构”的呢,首先看看扩散算法的架构。
[注]需要申明的一点是,Diffusion model 在2015年就已经被提出来了(论文链接),但是由于种种原因并不能被应用的很好。直到2020年出来的论文《Denoising Diffusion Probabilistic Models》(直译就是《除噪扩散概率模型》,简称DDPM)出来之后才引起广泛关注,并且DDPM 对原始的Diffusion model确实有较大改进,所以本文中所说的diffusion model 特指DDPM.
我们还是拿糖分子举例,为了研究糖分子是怎么扩散的,我们把糖分子的扩散过程按照时间分为1000段,每段给糖分子拍一张照片,我们发现在T时刻,糖分子是以Xt-1时的糖分子为中心呈现正态分布(高斯分布)来扩散的。
 Midjourney 教程
Midjourney 教程当然这只是一颗糖颗粒的糖分子扩散过程,如果有很多个糖颗粒,在容器里的糖分子就是所有糖颗粒产生的糖分子的累加。这里的糖颗粒相当于图片中的像素,糖分子的扩散就相对于对这个像素进行扩散,怎么理解呢,假设我们有一张黑白照片,像素的值在[0,255]之间,这张图上有一个像素的值为0,每一次扩散之后,这个像素就会像糖分子一样把自己的“溶解”到周围环境中,像素的值会从以0为中心的值按照正态分布的概率采样一个值成为新的值。大家可以注意到每次的正态分布都不一样,这一点我们会在稍后做出解释。

这种溶解过程称为“正向扩散”,也是模型的训练过程。如果我们要从随机噪声图片中重构图像,就要“反向扩散”。
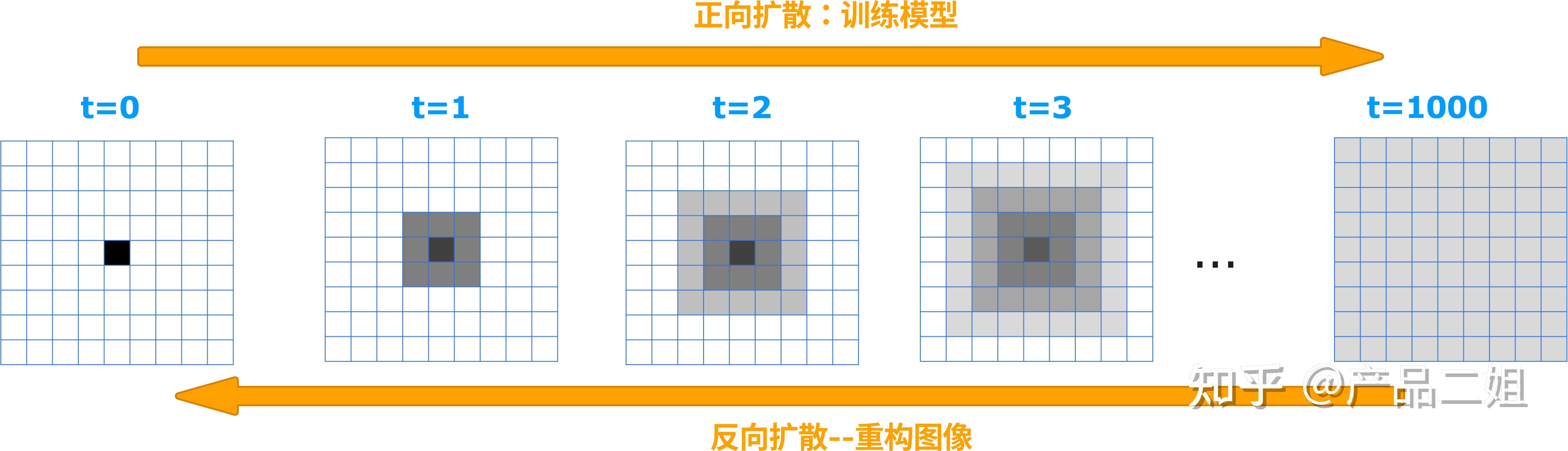
我们把上述过程用数学计算流程来表示就是下图,如此简单以至于我第一次接触的时候以为是我理解错了。

[注]当然后续把Diffusion运用在图像生成中还需要加上CLIP模型,AE模型等等,要注意的是diffusion 模型并不等于DALL.E, Mid-journey等工具使用的唯一模型。
不过,虽然架构简单,但训练步骤是非常繁杂的,在原论文中,t=1000, 也就是说,无论正向还是反向,需要计算1000次,这也是diffusion 算法目前最大的不足。
第一步:确定每一步的高斯噪声强度。
我们的目标是,最后一步加噪声之后的图像是随机分布的像素点,即服从整体分布N(0-1)。那我们能不能一步到位呢,显然不行 ,因为我们没有办法通过一个随机分布而重构出一个原始图像的。
如果有多步,比如1000(我个人觉得这是个经验数值),那么需要每一步均匀加噪声呢,还是开头的步数添加大噪声,后面的步数添加小噪声呢?我们知道正态分布是由均值,方差决定的。如下图,如果均值越大,方差越大,说明噪声强度也越大。

我们可以设想,我们的最终目标是要从随机噪声重构到细节高清,那么刚开始重构只需要关注轮廓,不需要关注细节,而越到最后,越要注重细节。也就是:
- 从 倒推 ,我们可以粗略一点,那么从 到 就可以多加些噪声。
- 相反,从 预测 ,我们需要高清细节,那么从 到 加的噪声就需要小一点。
这里的大小指的就是高斯分布的均值和方差。为了达到上述要求,
- t越小,我们希望噪声小一些,即均值越接近于 , 方差越小。
- t越大,我们希望噪声大一些,即均值与 相差较远, 方差也可以大一点。
这就是我们为什么在【图2:正向扩散】中采用了不同的高斯分布来添加噪声。我们观察Mid-journey 生成图片时也是由轮廓逐渐清晰。

根据上述要求,我们也就可以理解为什么要用下面的公式计算
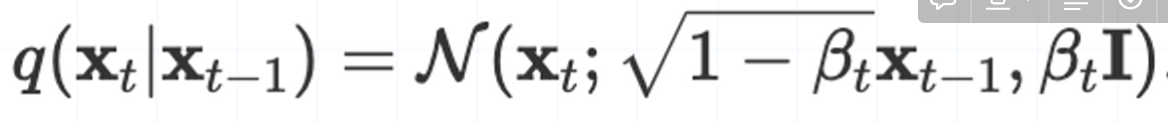
其中 是随t变换的一个值,是我们预先设定好的值,它的设定需要遵循一下规则:
- 是0~1之间的值,
- 且t越大,也越大。即:
实际应用中,我们可以将与t的关系设置为线性的、二次的、余弦的等。
确定好噪声之后,相当于我们有了与之间的关系,就可以训练出一个神经网络用于重构图像。
理论上来讲,在已知神经网络参数的情况下,我么就可以根据倒推。但这样的计算比较复杂,于是DDPM中就想到了一个简单的方法,与其预测,到不如预测 到的噪声 ,要知道噪声分布是一个已知条件,只是在反向扩散时,在同样的分布中采样不同的值而已。那么 就可以通过以下公式计算出来:
同时,DDPM还采用了Unet 方法让计算量降低,即把Xt-1降低到一个低维空间后(可以理解为把高分辨率的图片压缩为低分辨率图片)进行计算推理低维空间的Noise,然后在把低维空间的Noise 升高到高维空间,这也是图像处理中常见的一种解决方法。
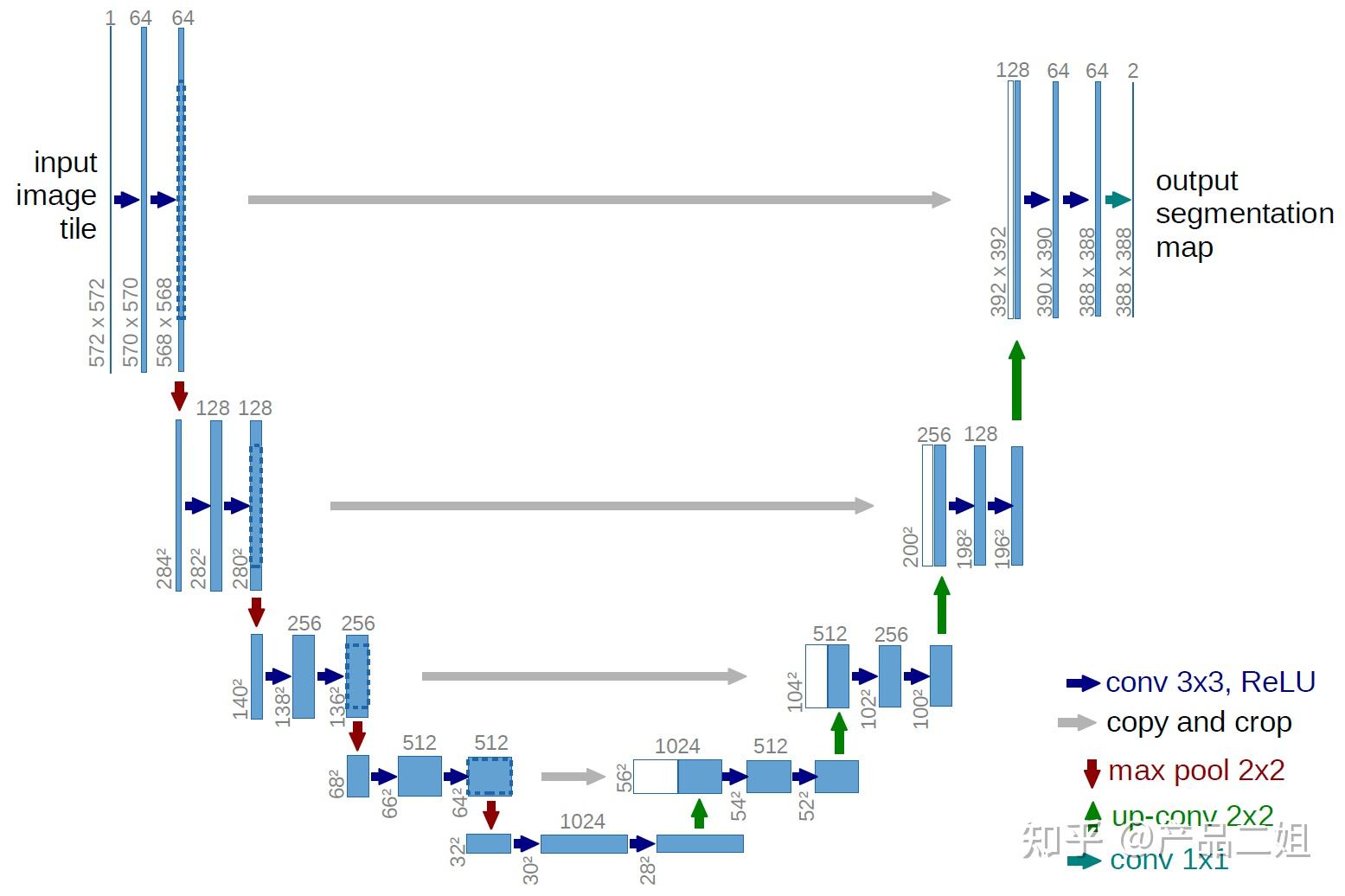
Unet本质是还是因为图像信息中存在着大量冗余信息。举例来说,给你看一个32*32像素的图片,和 的图片,信息含量大了1024倍,但视觉感受可远远没有1024倍扩大。
Diffusion 为什么在当前的情况下备受青睐,主要有两个原因:
- 在上篇文章中我们提到GAN有一个缺陷就是生成图片缺乏创造性,因为GAN从原理上来讲就是要和真实图像对比生成逼真的图像。而对于Diffusion模型,生成的图像既逼真,又有多样性。这是因为diffusion 模型在重构图像是从一个噪声分布中采样从而得到新的图片,这个“采样”就为多样性提供了可能。
- Diffusion模型数学原理上非常优美。对于学术界来讲,“数学优美”是一种追求,所以这也进一步激发了更多的学者对diffusion 模型进行改进。
2015年最初提出diffusion model的学者是Jascha Sohl-Dickstein,本科康奈尔,博士在加州伯克利大学,主要职业生涯在谷歌大脑和Google Deep mind 工作。他有自己的博客网站。

而在2020年真正把扩散模型拉到聚光灯下的人是Jonathan Ho,相关论文也是他在UC Berkeley 读博期间发表的,主要职业生涯在谷歌。
目前主要看了diffusion在DALL.E.2中应用的论文《Hierarchical Text-Conditional Image Generation with CLIP Latents》,跟着沐神的B站视频看的。
DALL·E 2(内含扩散模型介绍)【论文精读】_哔哩哔哩_bilibili
还没有完全看懂,所以简要概述一下就是DALL.E.2综合使用了CLIP和Diffusion 模型来实现图像生成的。
[注]CLIP全称是Contrastive Language–Image Pre-training,通过文本和图像对来训练出来的模型,详见Open AI官网
Improved DDPM是Open AI的研究者发表的论文,参考论文链接
其他有待更新,也可以侧面看出来Diffusion Model的潜力还没有被完全挖掘出来。最近DALL.E.3 刚刚发布,发布后不久一般我们会看到相应的论文发表,后续再跟进。
前文其实有提到Diffusion最大的不足在于训练次数复杂,想象T=1000,相信这也会成为大家争相改进的地方,期待后续改进。
算法改变技术,技术改变生活,在AI时代,拥抱它是唯一的选择!码字不易,欢迎点赞,收藏,转发。
发布者:Ai探索者,转载请注明出处:https://javaforall.net/274216.html原文链接:https://javaforall.net


