
大模型时代已经到来,作为前端同学如何在业务中切入模型的调用,我认为组件库是一个非常好的着手点。接下来就跟着我一起来完成一个基于Langchain的AI助手吧。
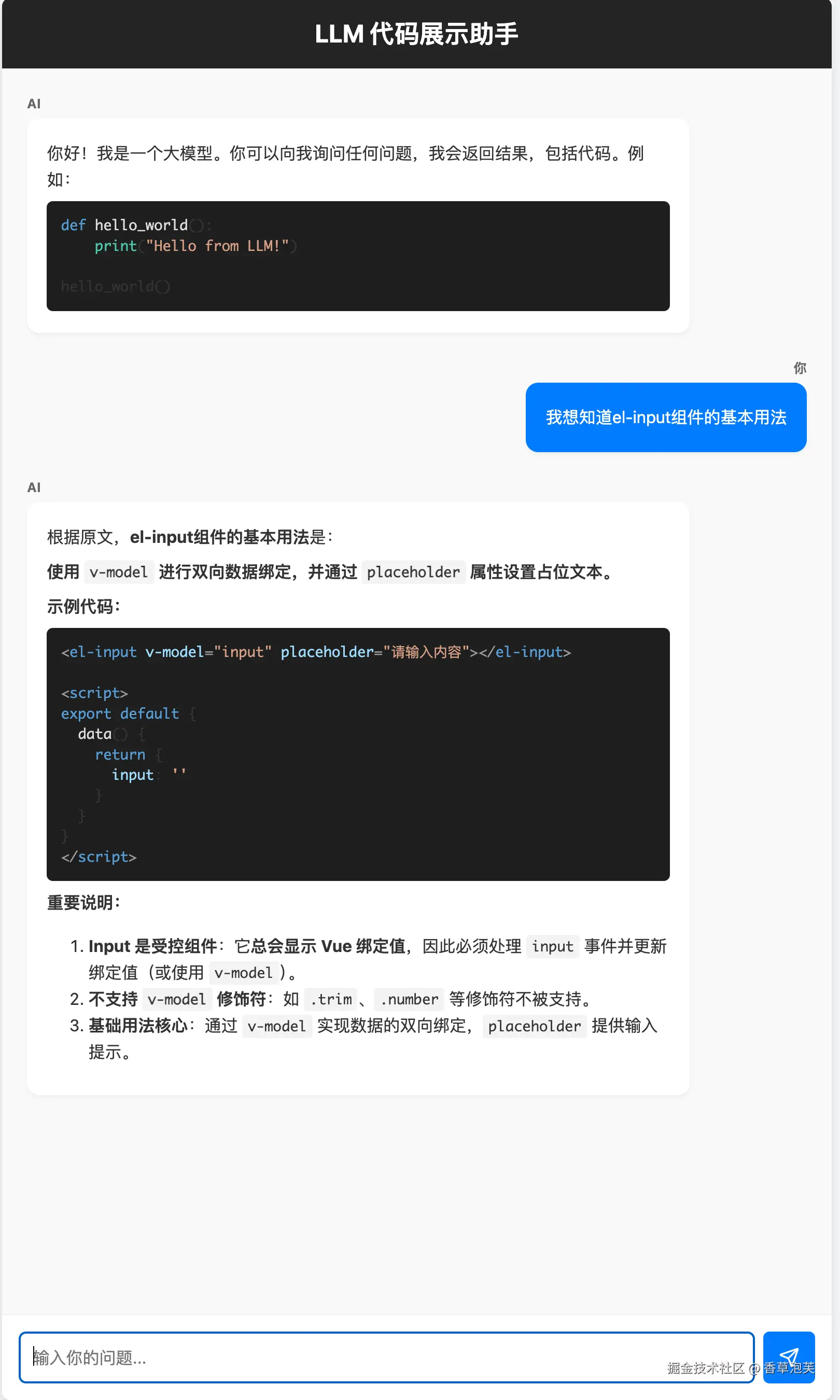
 最终效果就是通过自然语言询问AI助手某个组件属性和用法,这比通过查文档快得多,当然也可以直接接入到MCP中,在代码中直接使用AI助手来完成代码补全。
最终效果就是通过自然语言询问AI助手某个组件属性和用法,这比通过查文档快得多,当然也可以直接接入到MCP中,在代码中直接使用AI助手来完成代码补全。
先大体展示一下助手的整个流程设计
上面有两条工作流,第一条是向量存储的过程,首先需要组件库的文档说明示例,再将文档读取转化为字符串,接着使用Langchain框架自带的进行片段分割,最后使用进行向量化存储。
第二条工作流为共同工作给出回答,首先服务端接受用户输入的问题,然后根据用户提问在向量存储库中进行RAG检索,最终结合LLM大模型给出答案。
首先实现第一条工作流中的第一步,创建一个服务端项目,这里我使用的是框架。项目目录如下:
别担心我们会一步一步实现所有代码。
在目录下创建文件
这里只是简单的通过了创建了一个服务,并且创建了一个接口,用于接收前端返回的用户提问。使用postman调用试试:
在目录下创建文件。这里我们先使用实现一个简单的智能体,在开始之前我们先安装一下依赖:
接着需要去deepseek官网申请一下,这里简单演示一下:
1.第一步:选择API开放平台
2.第二步:注册完成后进行充值
3.第三步:生成
4.第四步:在项目根目录创建并写入
在完成以上步骤后,在新创建的文件中,写入如下代码:
以上实现的是一个翻译助手的,将原语言翻译为目标语言。实现过程是通过方法组合模型、提示词和输出解释器 为,最终导出给外部使用。如果不太懂这几个方法的作用,可以先去Langchain文档中查阅对应的说明。
接着在app目录index.js中新增调用chain的代码:
这里新增了接收和,会自动传递给作为参数。这里贴出调用参数:
然后我们使用postman调用试试看: 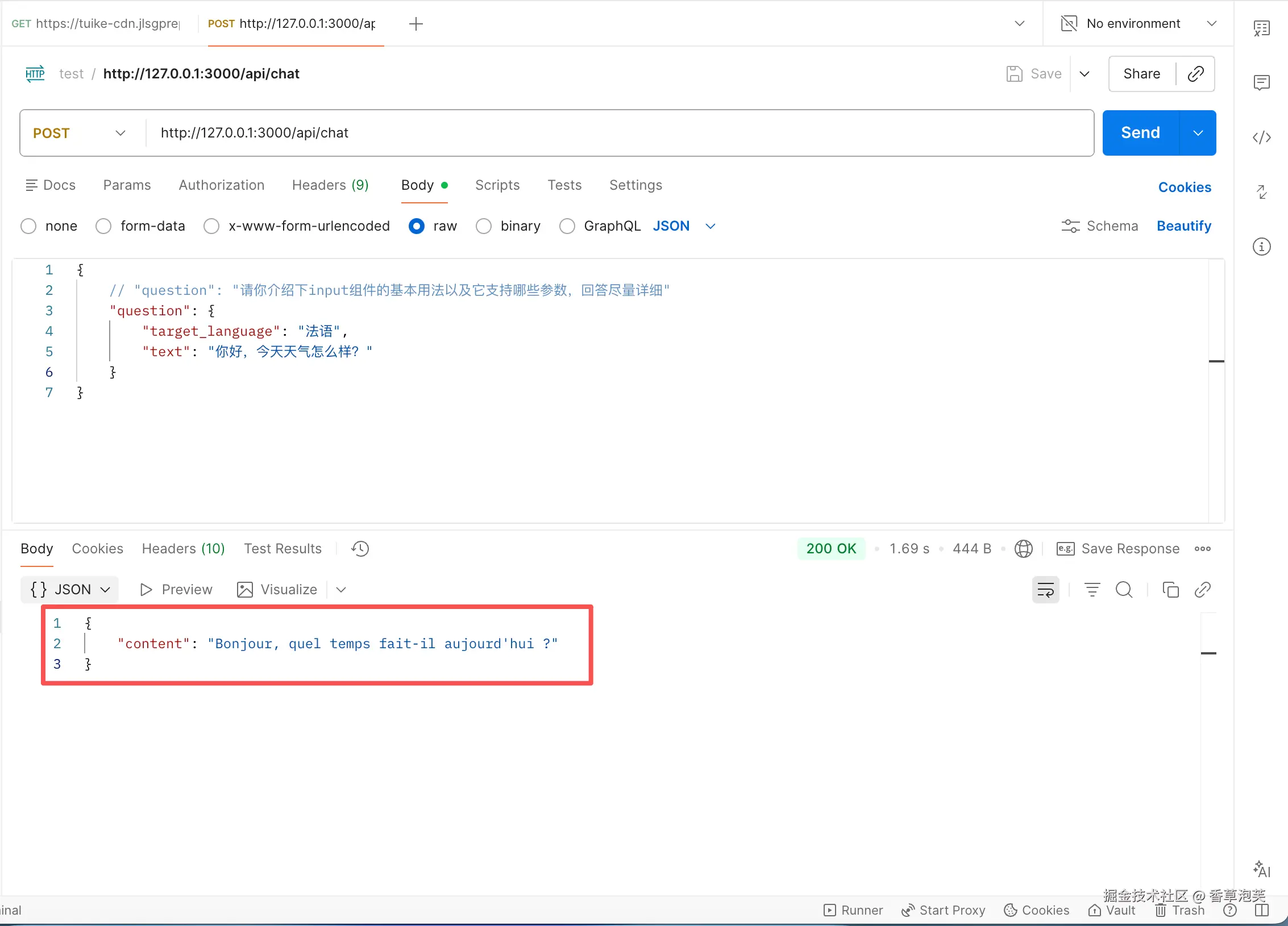
成功输出了大模型给出的结果,将中文翻译为法语。
接下来正式进入到第一个工作流的搭建过程,目的是给大语言模型提供组件库的上下文信息。
首先我们需要有组件库的说明文档,我使用了element-ui的button组件和input组件,并且做了将el前缀替换为fl前缀的操作,因为想和elment-ui官网做个区别。这里给出替换后的文件地址:github.com/boyzzy1995/…
然后开始文档的切片操作。
这里首先提出一个问题,为什么要做切片,直接使用完整的文档不可以吗?这里先不做回答,先看切片怎么做。
3.1.1.创建文本分割器
在agent目录的index.js文件中新增方法:
第三行代码为读取docs目录下的md文件,并转为字符串格式,这个方法不做过多介绍。重点在这是Langchain框架提供的递归字符文本分割器。
简单说明一下两个参数:
- chunkSize
- 含义 :每个文本片段最多包含 500 个字符
- 目的 :
- 控制输入 LLM 的文本长度,避免超出上下文窗口
- 让检索更精准(小块比大块更容易匹配)
- 减少无关信息干扰,提高回答质量
- chunkOverlap
- 含义 :相邻两个文本块之间有 20 个字符的重叠
- 目的 :
- 保持上下文连贯性,避免在边界处丢失语义
- 防止关键信息被切分到两个不连续的块中
- 提高检索召回率(重叠部分会在多个块中出现)
工作原理(递归分割过程): 使用多级分隔符列表,按优先级逐步分割:
假设有 1000 字符的文档,使用 :
重叠的作用:
- Chunk 1 末尾 和 Chunk 2 开头 有 20 字符相同
- 即使关键词恰好在边界,也能在两个块中都找到
这里的和并不是固定的,需要根据当前的使用环境来决定,可以进行适当的调整来确定检索的正确率。
3.1.2.分割文档
接着用分割器进行文档分割:
这里新增了三行代码。
第一行是将多个组件文档通过特殊换行符进行连接,上文的会识别特殊分隔符进行分割切片。
第二行通过对象进行包装,Document对象可以理解成对所有类型的数据的一个统一抽象,其中包含
- 文本内容,即文档对象对应的文本数据
- 元数据,文本数据对应的元数据,例如 原始文档的标题、页数等信息,可以用于后面 基于此进行筛选。
第三行通过分割器对文档进行分割,打印一下结果看一下:
取数组下标0看一下第一个Document对象:
可以看到pageContent已经分割完成了,并且metadata标识了段落在文档中开始行和结束行。
再来看下标为1的Document对象:
输出结果为:
嗯?不是说设置了chunkOverlap会有重叠部分吗,怎么没有呢?
原因分析: 从文档和输出结果来看:
- 文档0长度380,文档1长度305 – 两个文档都远小于
- 分割点 : 会优先按语义边界 (如段落 、代码块等)分割
button.md 的内容,它包含多个 包裹的代码块(demo 块), 会在这些语义边界处分割,而不是强制按字符数切割。
关键点:
- 只在强制切割(当文本超过 chunkSize 时)才会生效
- 当文本按语义边界分割后,如果每个块都小于 ,就不会触发重叠逻辑
所以要看到重叠效果只要调小chunkSize即可。例如我这里将chunkSize改为100,效果如下:
可以看到前后两个Document对象中的pageContent出现了重叠部分。至此切片部分就已经完成了。
向量化工程需要借助模型的embedding能力。
3.2.1 embedding处理
Langchain中的核心embedding方式有两种:
- 第三方大模型 Embedding(最常用):这是实际开发中使用最多的类型,对接主流 AI 厂商的嵌入接口,需要 API Key,优点是效果好、开箱即用。
- OpenAI Embeddings :(包括 GPT-3.5/4 系列的 text-embedding-ada-002 等)
- Anthropic Embeddings :(Claude 系列的嵌入模型)
- Google Vertex AI Embeddings :(Google PaLM/CGemini 嵌入)
- Cohere Embeddings :(专注文本嵌入的专用模型)
- Azure OpenAI Embeddings :(微软 Azure 部署的 OpenAI 嵌入)
- 百度 / 阿里 / 腾讯国内厂商 :如 (文心一言嵌入)、(智谱清言)等(需安装 langchain-community 扩展)
代码示例:
- 本地运行的 Embedding(无 API 依赖):无需联网、无调用成本,适合隐私敏感或离线场景,缺点是需要本地部署模型,效果略逊于云端模型。
- Hugging Face 本地模型 :(需安装 @xenova/transformers)
- Sentence Transformers Agent 智能体 :基于 封装的轻量版
- LLaMA/Alpaca 本地嵌入:需结合本地大模型框架(如 llama.cpp)
代码示例(本地 HuggingFace Embedding):
这里我们只是为了教学,就使用ollama方式本地使用一个小模型。
- 首先下载ollama
 2. 在ollama界面中输入直接下载即可
2. 在ollama界面中输入直接下载即可
这样本地就部署了一个用于embedding的小模型,然后我们进入编码阶段。
在agent/index.js文件中新增如下代码:
这段代码新增了embedding初始化模型使用,并且baseUrl指定为本地ollama运行模型的地址。
最后一行使用embedDocuments对文档片段进行向量化。
log看看向量化后的是什么东西
可以看到是一串number类型的数组,有正有负。那么这些数字有什么含义呢?也就是向量的含义。
这是一个 1024 维的向量(显示 100 个,还有 924 个),每个数字代表文本在一个高维空间中的坐标位置。
简单说:把文字变成了计算机能理解的数字坐标。原来计算机不懂我们所说文字的含义,但是通过转成向量,可以通过进行数学计算,比如计算距离(余弦相似度)来判断文字含义的相似度。如果不使用向量,只能通过文字匹配来进行检索。准确度会远不如向量检索。
至此已经完成了文档向量化。
3.2.1.为什么要做切片
现在可以回答这个问题了,但我们换个问题,如果不做切片会怎么样?
假设直接把整个 + (可能几万字)一起向量化:
问题1:检索精度极差
用户问: “Button 组件怎么设置禁用状态?”
没有切片时:
- 向量库中只有 1 个大向量(包含 Button + Input 所有内容)
- 检索返回的是这个”大杂烩”向量
- 结果:找回整篇文档,混杂大量无关信息(Input 用法、其他组件等)
有切片后:
- 向量库中有 N 个精准向量(每个都是独立知识点)
- 检索直接定位到 “Button 禁用属性” 相关的那一小块
- 结果:精确返回相关内容,无干扰信息
问题 2:LLM 上下文窗口限制
即使检索到了,LLM 也处理不了:
切片的好处:
总结:切片带来的核心优势
接下来需要对向量进行持久化,因为如果文档数量过多,每次运行都需要进行embedding会非常耗时。所以这里我们使用facebook开源的faiss-node进行本地化存储。
安装依赖
1.1.8以上已经自带了faiss,可以简化部分操作。
最后两行新增代码,使用内置方法来向量化文档。然后保存到db文件夹目录中。
如果运行成功,将会在工作目录里创建db和db目录里的两个文件。
– 向量索引文件
- 格式:二进制文件(FAISS 原生格式)
- 作用 :存储文档的向量数据 和索引结构
- 内容:高维向量 + 用于快速相似度搜索的索引结构(如 IVF、HNSW 等)
- 特点:只能被 FAISS 库读取,人类无法直接阅读
– 文档存储文件
- 格式:JSON 文件
- 作用 :存储原始文档内容(pageContent 和 metadata)
- 内容:每个文档的 ID、文本内容、元数据(如来源行号等)
- 特点:人类可读,可以看到分割后的文本片段
搜索流程:
- 用户输入查询 → 转成向量
- faiss.index → 快速找到最相似的向量(返回文档ID)
- docstore.json → 根据ID获取原始文本内容
- 返回给用户
在这一小节中,会使用问题去向量数据库中检索最相关内容进行返回。
在agent/index.js文件中新增方法getChain并将该方法导出,因为在app中会使用:
这里判断db目录是否存在,不存在则执行创建向量化操作,存在则通过Faiss加载向量库。然后asRetriever(10)只加载前10个最相关的片段。再通过RunnableSequence.from创建chain,chain做的操作就是将input.question传入给retriever,由retriever去做向量检索,然后将返回的片段转化为字符串返回。
在app/index.js中引入刚刚导出的getChain:
使用postman调用一下chat接口:
检索返回了和我们提问相关的文档片段。
上面返回了检索结果,但是还有一些相关的内容,因此后面我们还需要使用LLM进行总结,也就是增强。
我们使用上面提到的DeepseekV3的模型,来创建一下model:
然后就需要声明我们给LLM的提示词了。提示词可以分为系统提示词和用户提示词,我们来写一下:
系统提示词是基本原则,我们要让LLM根据原文进行回答,如果原文内容没有则直接回答没有,减少LLM幻觉问题。
最后再构建一个chain来整合一下完成的RAG流程:
这里将检索chain产生的结果作为上下文,以及声明的系统提示词和用户提示词一起传递给LLM,最终将LLM产生的结果转换为JSON字符串。
我们来试试:
至此RAG基础的流程都已经完成了。
本章暂时只完成基础的RAG部分,后续会继续补充记忆、搜索和前端交互界面。如果觉得写的还不错,可以点点赞收藏一下。当然写的不好的地方也可以指出,在评论区进行交流哈。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/279749.html原文链接:https://javaforall.net


