
一、项目背景
单一的健身 Agent 对于不同需求的问题会出现不同的问题。
比如用户问”我上周跑了多少公里?”——这需要查数据库,返回精确数字。
但用户又问”跑步后腿酸怎么办?”——这需要检索专业文档,返回知识性建议。
如果强行用一个 Agent 处理所有问题,要么数据查询不准,要么知识回答缺乏依据。
这就是 Multi-Agent 系统的价值所在:让不同的 Agent 各司其职,由一个协调层统一调度。
最终实现的效果如下:
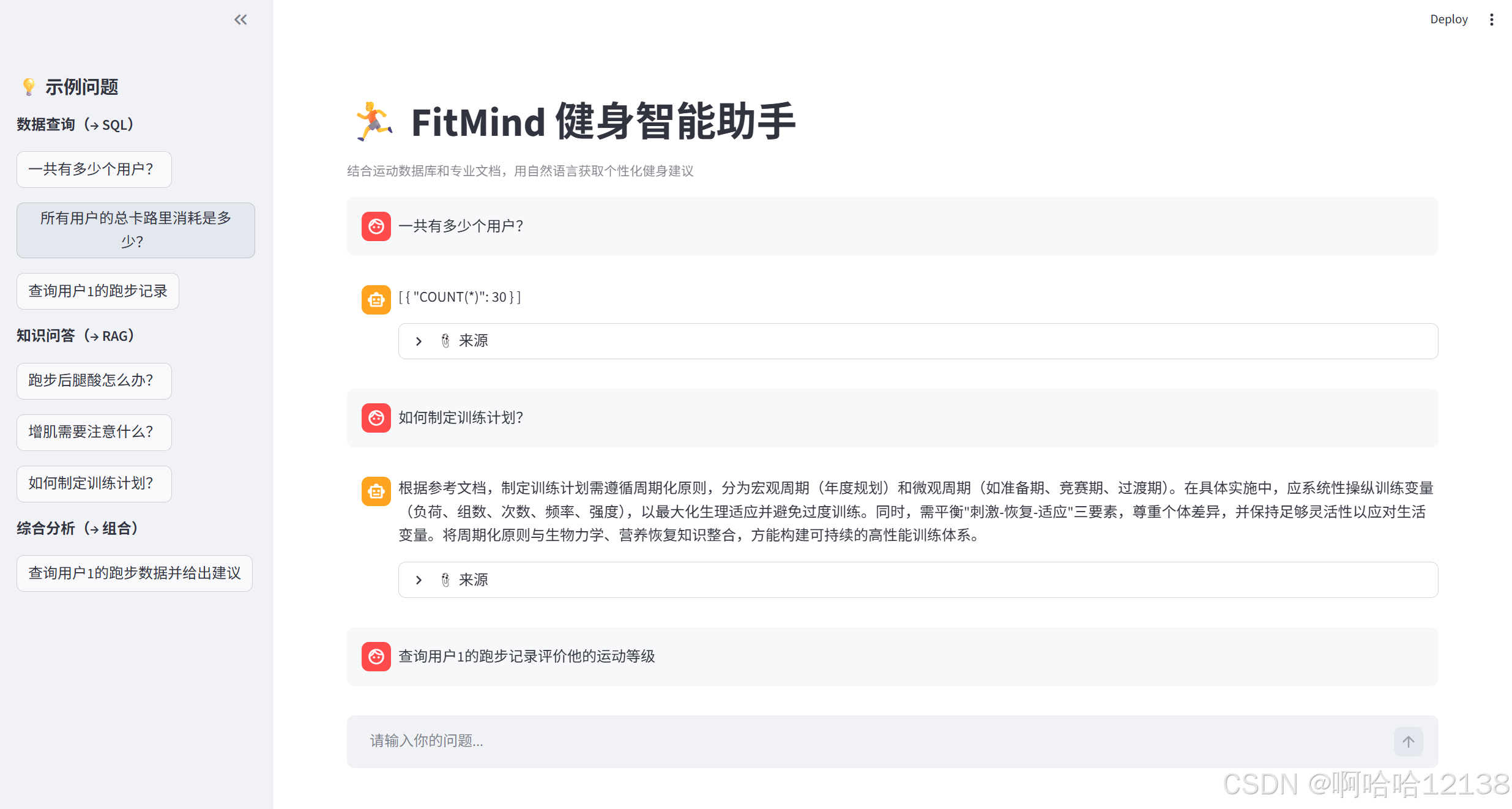

用户用自然语言提问,系统自动判断问题类型并路由:
- 数据类问题 → SQLAgent 查询 SQLite 数据库,返回精确结果
- 知识类问题 → RAGAgent 检索专业文档,返回有依据的建议
- 综合类问题 → 两者协同,数据 + 知识合并成完整回答
技术栈一览
二、系统架构设计
整体架构
先看整体架构,再逐层拆解:
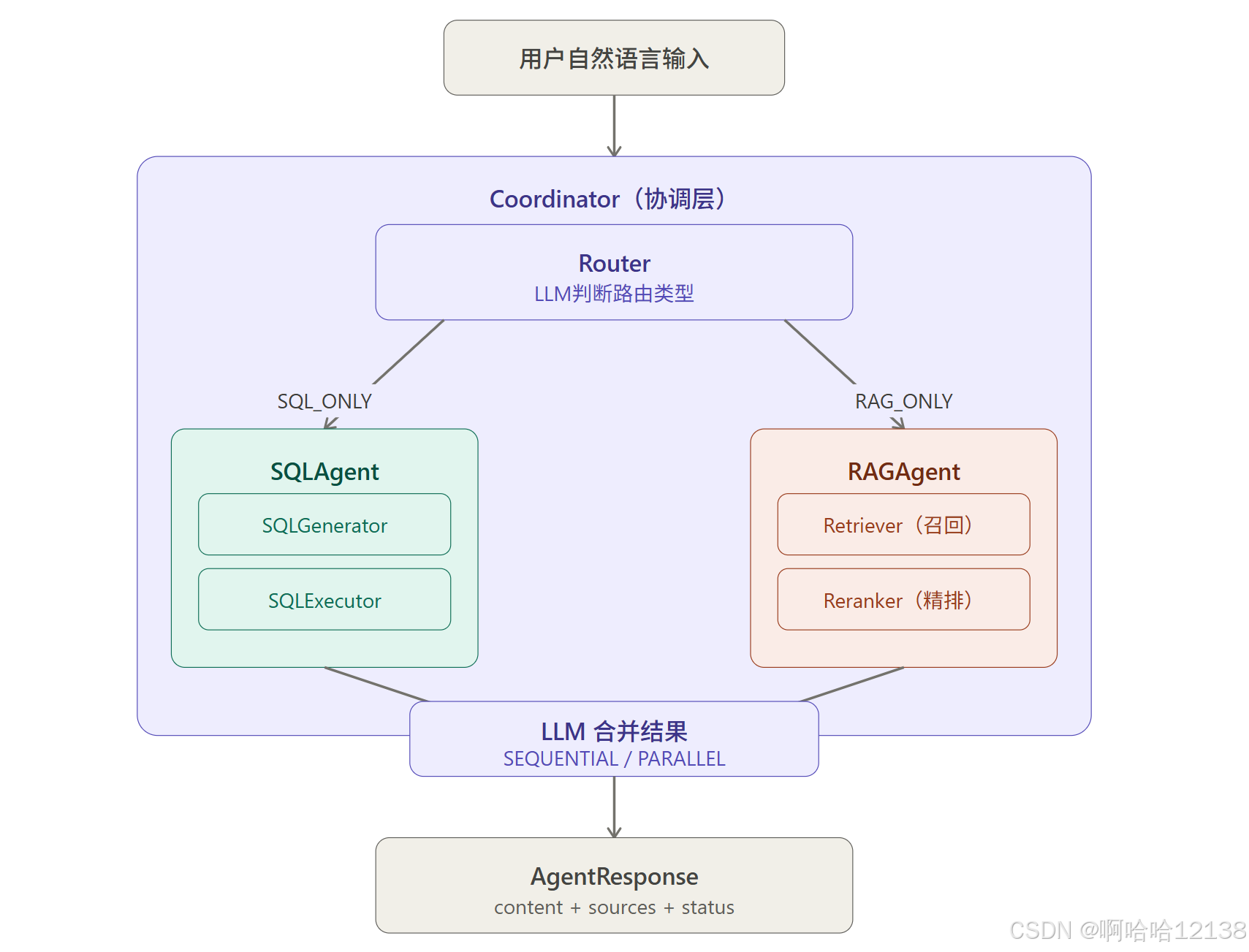
整个系统分三层:Agent 层、协调层、适配层,每层职责清晰,互不耦合。
设计决策一:模板方法模式(BaseAgent)
所有 Agent 都继承自 抽象基类:
这样设计的好处是:验证、计时、日志、错误处理由基类统一处理,子类只写业务逻辑。 新增一个 Agent 只需要继承 并实现 ,其他全部复用。
设计决策二:适配器模式(LLM 统一接口)
项目开发阶段用本地 Ollama 调试(零费用),上线切换千问云端 API,业务代码一行不改:
千问和 Ollama 都实现了 OpenAI 兼容接口,切换只需要改一行初始化代码。
设计决策三:依赖注入
所有组件从外部注入依赖,不在内部创建:
正是因为这个设计,测试时才能方便地注入 Mock 对象,30 个测试用例得以快速运行。
四种路由策略
Coordinator 支持四种调度模式:
三、SQLAgent:自然语言查数据库
SQLAgent 负责把用户的自然语言问题转换成 SQL 并执行,返回结构化数据。内部由两个模块组成:SQLGenerator(生成SQL)和 SQLExecutor(执行SQL)。
整体流程
Prompt 设计
Prompt 是 SQLAgent 的核心,设计得好坏直接决定生成 SQL 的质量。
最终版 prompt 包含四个关键要素:
易错点
这里有一个关键踩坑:最初 prompt 里写的是”必须包含 WHERE user_id 条件”,导致查询用户总数这种全局统计也被加上了 ,SQL 直接报错。
解决方案是根据是否传入有效 user_id,动态生成不同的约束:
三层 SQL 安全防御
即使 LLM 生成了危险 SQL,也无法对数据库造成破坏:
第一层:关键词黑名单
第二层:sqlparse 语句类型检查
第三层:数据库只读权限
即使前两层被绕过(比如通过注释混淆),数据库本身配置为只读,写操作直接被拒绝。
三层防御的逻辑是:拦截意图 → 拦截语法 → 拦截执行,层层兜底。
空结果 vs 执行错误的区分
SQLExecutor 有一个容易忽略但很重要的设计:
和 是两种完全不同的状态:
两者混淆会把系统故障当成”没有数据”处理,掩盖真实问题。
另一个踩坑:session_id 和 user_id 混用
开发过程中遇到过一个隐蔽的 bug:
根本原因是把 (UUID,用于追踪请求)当成了数据库的 (整数,用于过滤数据)传给了 LLM。
修复方案是在 里单独加一个 字段:
这个 bug 的教训:概念相似的字段一定要明确区分,不能混用。 标识”这次请求”, 标识”这个人”,两者生命周期和用途完全不同。
四、RAGAgent:两阶段文档检索
RAGAgent 负责从专业文档库里找到最相关的内容,结合 LLM 生成有依据的回答。核心设计是两阶段检索:向量召回 + 精排。
为什么需要两阶段?
很多教程直接用向量检索就结束了,但实际效果并不理想。原因在于:
向量检索只看”语义相似”,不理解”问题意图”。
比如用户问”跑步后腿酸怎么办?”,向量检索可能返回:
Reranker 的作用是对候选结果重新精排,从”语义相似”升级为”对回答最有帮助”:
但为什么不直接对全量文档做精排?
Retriever:向量召回
为什么用 而不是内存模式?
内存模式每次重启都要重新 Embedding 全部文档。32 个块还好,生产环境文档库可能有几万个块,每次重启重新 Embedding 要花几小时,还会产生大量 API 费用。持久化到磁盘,只需要第一次加载,后续直接检索。
Reranker:精排
注意 Reranker 返回的 越高越相关,和 Retriever 的 (越小越相关)方向相反。两者的本质区别:
RAGAgent 组装
五、Coordinator:智能调度层
Router:LLM 驱动的路由决策
Router 有两层容错机制:
为什么用 而不是直接用 ?
LLM 返回的 JSON 是外部不可控数据,可能缺少某个字段。 在 key 不存在时返回默认值, 索引则直接抛 。对外部数据始终用防御性编程。
SEQUENTIAL 的核心:上下文传递
SEQUENTIAL 最关键的逻辑是把 SQL 结果传给 RAG:
如果没有这步上下文传递,RAGAgent 不知道用户跑了多少公里,只能给出通用建议。有了数据支撑,回答才能真正个性化。
六、测试体系
测试金字塔
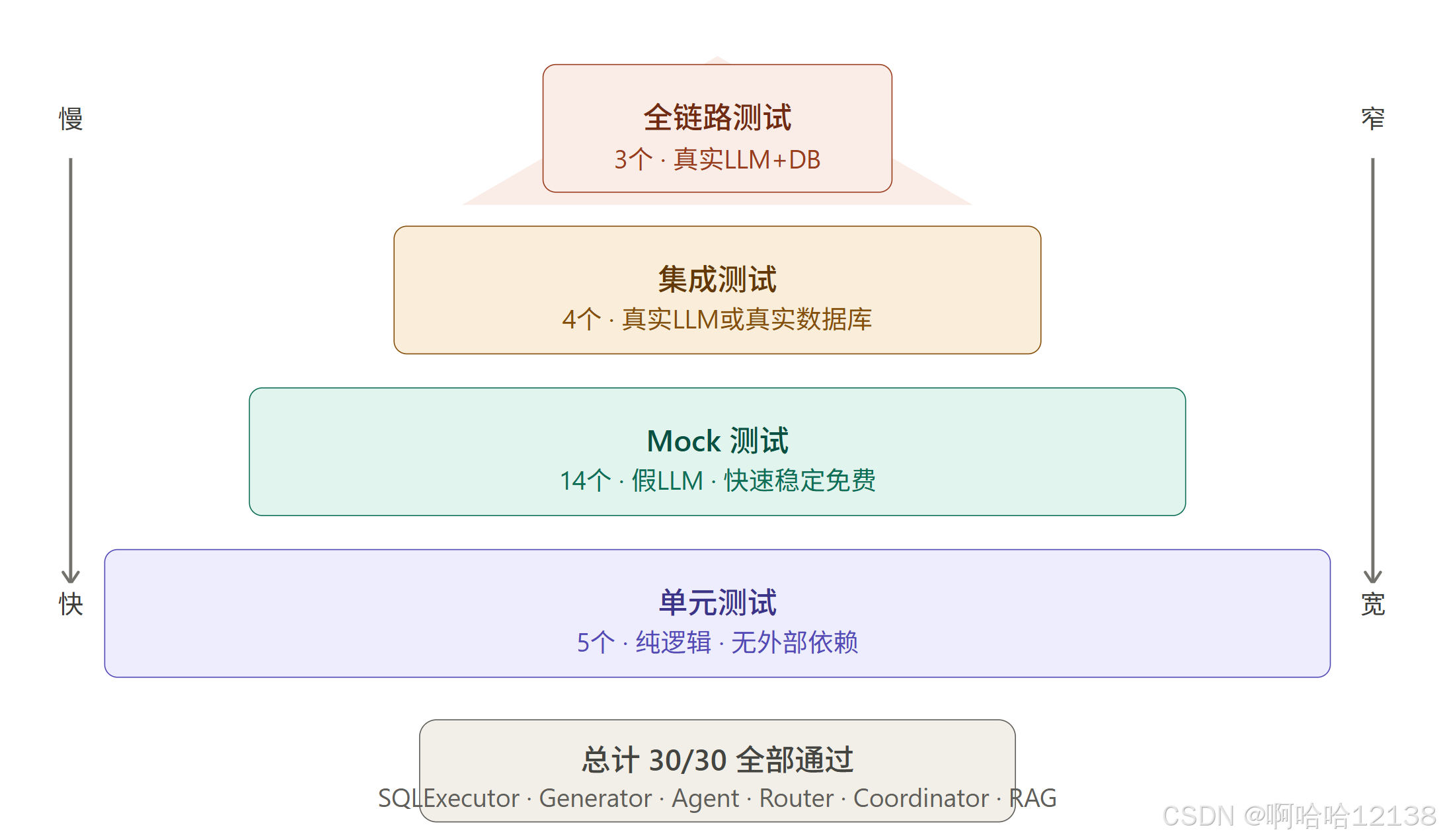
为什么大部分用 Mock?
Mock 测试的核心思想:测试的是”我的代码逻辑”,不是”LLM的能力”。LLM 返回什么是 LLM 厂商的责任,我们只需要测试拿到返回值后,自己的代码处理是否正确。
一个有价值的测试:验证 SEQUENTIAL 的上下文传递
这类行为验证测试在 Agent 开发里特别重要。数据传递错误不会报异常,只会让回答质量下降,很难靠人工发现。

七、踩坑总结
开发过程中遇到的坑,记录下来希望对你有用。
坑1: 位置不对
坑2:LangChain 和 OpenAI SDK 返回格式不同
坑3: 跳过 的风险
坑4:Prompt 约束导致的静默错误
坑5: 文件名拼错
八、总结与后续规划
项目地址
GitHub:
本地运行:
这个项目让我理解的几件事
Multi-Agent 的价值不是”多个AI”,而是”分工”。 每个 Agent 只做一件事,做好做精,比一个全能 Agent 效果好得多。
Prompt 工程和代码工程同等重要。 Prompt 写得不好,不会报错,只会让结果悄悄变差。需要像测试代码一样测试 Prompt。
分层测试是 Agent 开发的必要投入。 全链路失败时,能在30秒内定位到具体哪一层出了问题,这个能力值得花时间建立。
后续可以加的功能
全文完。如果对你有帮助,欢迎点赞收藏,有问题在评论区交流
发布者:Ai探索者,转载请注明出处:https://javaforall.net/282860.html原文链接:https://javaforall.net


