
文章目录
- [LLM + Agent 是什么](#LLM + Agent 是什么)
-
- 信息流
-
- [LLM 本身是无状态的处理器和Agent 的”记忆”,怎么理解](#LLM 本身是无状态的处理器和Agent 的“记忆“,怎么理解)
-
- [网页版的 ChatGPT 或 Claude 本身就是一个封装好的 Agent 系统。](#网页版的 ChatGPT 或 Claude 本身就是一个封装好的 Agent 系统。)
- [如果真的”只有 LLM”会怎样?](#如果真的“只有 LLM”会怎样?)
- [agent 记忆](#agent 记忆)
-
- agent短期记忆和长期记忆
-
- agent记忆存在哪里
- [举例:假设你有一个包含 100 个文件的项目,你想让 AI 帮你改一个登录 Bug](#举例:假设你有一个包含 100 个文件的项目,你想让 AI 帮你改一个登录 Bug)
- [Agent 是如何被写出来的。记忆?自动拼接上下文?什么时候查询数据库?什么时候调用”LLM?什么时候不在调用llm?](#Agent 是如何被写出来的。记忆?自动拼接上下文?什么时候查询数据库?什么时候调用”LLM?什么时候不在调用llm?)
- [MCP(Model Context Protocol,模型上下文协议)](#MCP(Model Context Protocol,模型上下文协议))
-
- [MCP 的核心架构:mcp客户端,mcp服务器,资源](#MCP 的核心架构:mcp客户端,mcp服务器,资源)
- [MCP 实际上是一种基于 JSON-RPC 的通信协议](#MCP 实际上是一种基于 JSON-RPC 的通信协议)
-
- [JSON-RPC 是什么](#JSON-RPC 是什么)
- [API 和 JSON-RPC 是什么](#API 和 JSON-RPC 是什么)
- [JSON-RPC 数据包的”运输方式”:stdin/stdout 或 HTTP](#JSON-RPC 数据包的“运输方式”:stdin/stdout 或 HTTP)
- [SSE (Server-Sent Events) 是一种”单向常连”技术。它允许服务器在建立连接后,像源源不断的流水一样,主动把数据推送到客户端(Agent),而不需要客户端反复询问](#SSE (Server-Sent Events) 是一种“单向常连”技术。它允许服务器在建立连接后,像源源不断的流水一样,主动把数据推送到客户端(Agent),而不需要客户端反复询问)
- sse与普通http区别
- [流式(Streaming)是数据传输方式,SSE 是实现流式的一种技术](#流式(Streaming)是数据传输方式,SSE 是实现流式的一种技术)
- [判断是否是MCP 客户端 (如支持mcp的Agent):](#判断是否是MCP 客户端 (如支持mcp的Agent):)
- [判定一个服务器是否为 MCP 服务器的”三个标准”](#判定一个服务器是否为 MCP 服务器的“三个标准”)
-
- [MCP 服务器的作用:MCP 是 Agent 和外部工具之间的桥梁/调度中心。如果工具在 MCP 上:直接调用函数。如果工具在外部服务:通过 HTTP / gRPC / RPC 调用](#MCP 服务器的作用:MCP 是 Agent 和外部工具之间的桥梁/调度中心。如果工具在 MCP 上:直接调用函数。如果工具在外部服务:通过 HTTP / gRPC / RPC 调用)
- [为什么 MCP 可以统一调用工具](#为什么 MCP 可以统一调用工具)
- agent怎么知道有哪些工具?llm怎么知道有哪些工具
-
- agent调用工具怎么知道要输入哪些内容,哪些参数
-
- 例子
- [Agent 怎么知道发给哪个 LLM? 给agent配置哪个llm就用哪个](#Agent 怎么知道发给哪个 LLM? 给agent配置哪个llm就用哪个)
-
- [Agent 发送请求到llm,需要 配置LLM 的哪些参数?](#Agent 发送请求到llm,需要 配置LLM 的哪些参数?)
-
- 举例
-
- [messages 列表 = Prompt,只是格式化成多条消息。system role = 设定模型身份/行为规则。user role = 用户输入/任务。assistant role 也是 Prompt(messages)的一部分,模型自身的角色,主要用于记录 LLM 自己之前的输出,让模型理解上下文、保持连贯性](#messages 列表 = Prompt,只是格式化成多条消息。system role = 设定模型身份/行为规则。user role = 用户输入/任务。assistant role 也是 Prompt(messages)的一部分,模型自身的角色,主要用于记录 LLM 自己之前的输出,让模型理解上下文、保持连贯性)
- 怎么实现工具才能让agent调用
-
- [tool/list 返回的内容,是 Schema 还是工具列表,以及谁生成 Schem](#tool/list 返回的内容,是 Schema 还是工具列表,以及谁生成 Schem)
- [API 交互标准,OpenAI 定义了一套如何与大模型对话的接口规范(如 /v1/chat/completions)](#API 交互标准,OpenAI 定义了一套如何与大模型对话的接口规范(如 /v1/chat/completions))
-
- [messages 里的角色有哪些](#messages 里的角色有哪些)
-
- system
- user
- assistant
-
- [Function Call 的本质](#Function Call 的本质)
- [role: function(可选) → 标识这是工具调用结果](#role: function(可选) → 标识这是工具调用结果)
- [什么是 SDK Software Development Kit(开发工具包)](#什么是 SDK Software Development Kit(开发工具包))
- [什么叫 “兼容 OpenAI API”?使用与 OpenAI 兼容的 API 格式,什么意思?OpenAI API标准?](#什么叫 “兼容 OpenAI API”?使用与 OpenAI 兼容的 API 格式,什么意思?OpenAI API标准?)
-
- [“调用 API 不一定要写 URL”,URL 只是 HTTP REST 的形式;](#“调用 API 不一定要写 URL”,URL 只是 HTTP REST 的形式;)
-
- [API 本质上就是 函数的远程版本。远程的函数](#API 本质上就是 函数的远程版本。远程的函数)
- [调用 API 的形式。http api/grpc等都是rpc的实现方式](#调用 API 的形式。http api/grpc等都是rpc的实现方式)
-
- [http rest](#http rest)
- [gRPC / RPC / GraphQL / WebSocket 流式.也是调用远程函数,只是 协议不同](#gRPC / RPC / GraphQL / WebSocket 流式.也是调用远程函数,只是 协议不同)
- [为什么”写了 URL 就是调用 API”。属于http rest形式调取api](#为什么“写了 URL 就是调用 API”。属于http rest形式调取api)
-
- [http rest形式:API 调用的四个核心要素.models参数意义](#http rest形式:API 调用的四个核心要素.models参数意义)
- [API 的协议层、实现方式和调用方式](#API 的协议层、实现方式和调用方式)
-
-
- 详细解释
- [API 的实现方式和对应调用示例](#API 的实现方式和对应调用示例)
-
- [为什么 OpenAI SDK 可以换 URL 就调用别的 API?http rest形式调用api时,换url就是换api了。还可以使用openai sdk是因为别人的api的参数和返回结果与openai一样](#为什么 OpenAI SDK 可以换 URL 就调用别的 API?http rest形式调用api时,换url就是换api了。还可以使用openai sdk是因为别人的api的参数和返回结果与openai一样)
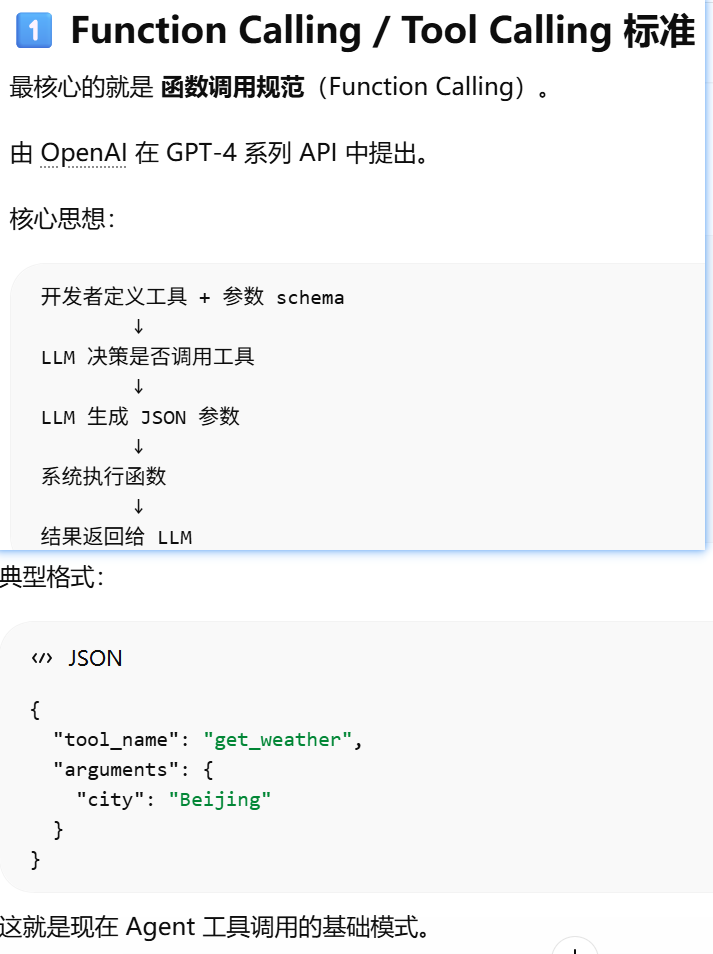
- [OpenAI 在 2023 年之后给 AI 应用开发定义了一套”事实标准(de-facto standard)”](#OpenAI 在 2023 年之后给 AI 应用开发定义了一套“事实标准(de-facto standard)”)
-
- [OpenAI 推动的”工具调用(Tool Calling / Function Calling)接口标准”](#OpenAI 推动的“工具调用(Tool Calling / Function Calling)接口标准”)
-
-
- [Function Calling / Tool Calling 标准](#Function Calling / Tool Calling 标准)
- [JSON Schema 作为工具参数标准](#JSON Schema 作为工具参数标准)
-
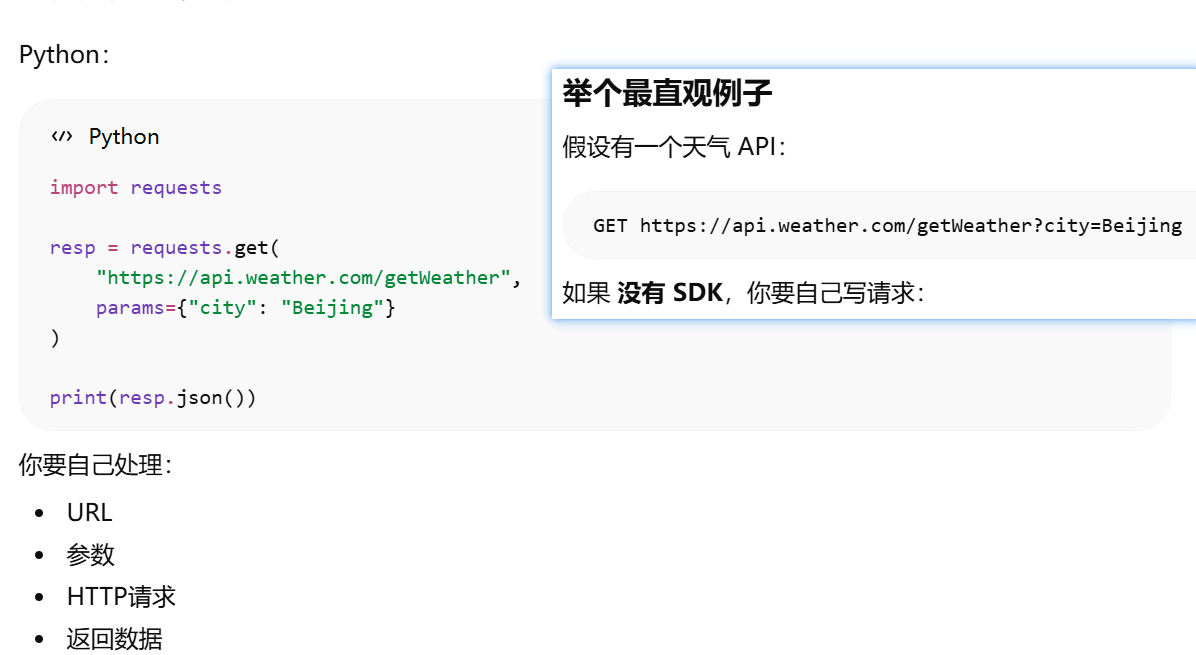
- [SDK = Software Development Kit(软件开发工具包)](#SDK = Software Development Kit(软件开发工具包))
- [Chat Message 协议,OpenAI 还定义了 对话消息结构标准](#Chat Message 协议,OpenAI 还定义了 对话消息结构标准)
-
- [后来 Anthropic 提出了 Model Context Protocol (MCP)。把 OpenAI Function Calling 的思想扩展成跨工具协议](#后来 Anthropic 提出了 Model Context Protocol (MCP)。把 OpenAI Function Calling 的思想扩展成跨工具协议)
- [OpenAI后来又加了一条标准:模型输出必须符合指定 JSON Schema](#OpenAI后来又加了一条标准:模型输出必须符合指定 JSON Schema)
-
- [现在 AI 行业的架构是什么样](#现在 AI 行业的架构是什么样)
-
- [目前 AI 行业形成了 两套标准体系:](#目前 AI 行业形成了 两套标准体系:)
- Agent框架:典型功能:工具调用,记忆,任务规划等
-
- [Agent 框架里的 任务规划(Planning)和任务拆分(Task Decomposition),核心其实不是复杂算法,而是 让 LLM 先当”规划器”再当”执行器”](#Agent 框架里的 任务规划(Planning)和任务拆分(Task Decomposition),核心其实不是复杂算法,而是 让 LLM 先当“规划器”再当“执行器”)
-
- [任务拆分实现方式:Prompt-based Planning(最常见)](#任务拆分实现方式:Prompt-based Agent 智能体 Planning(最常见))
- [任务拆分实现方式:ReAct(最经典 Agent 方法)。Thought → Action → Observation](#任务拆分实现方式:ReAct(最经典 Agent 方法)。Thought → Action → Observation)
-
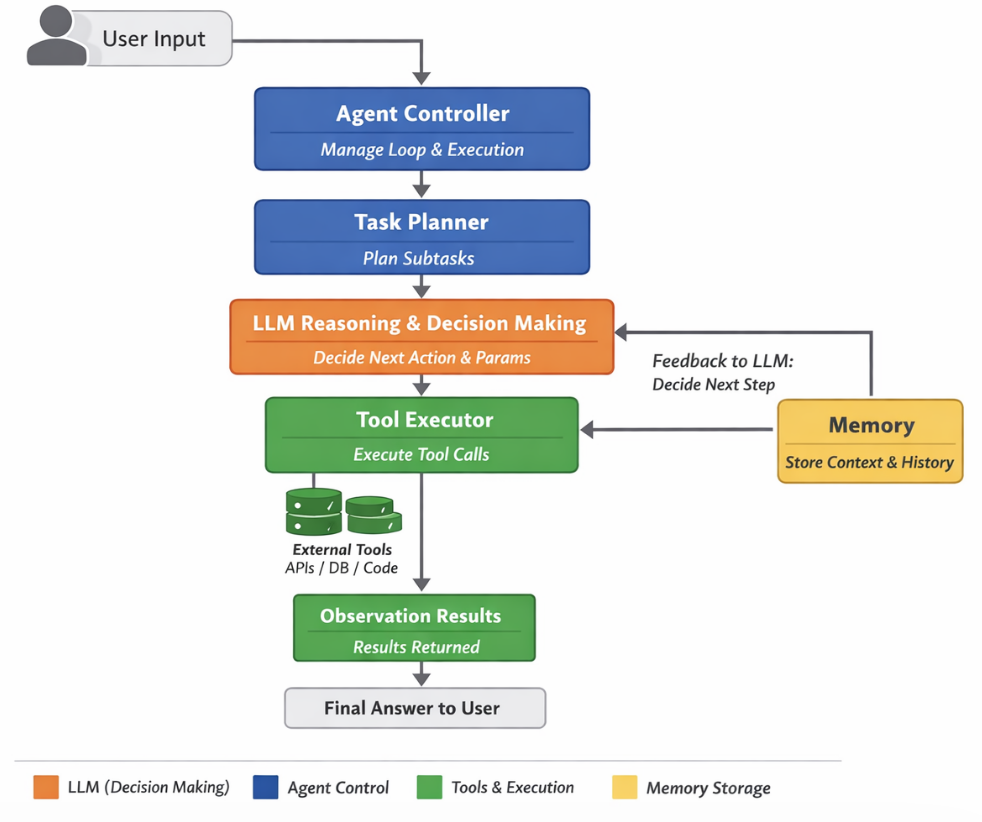
- [Agent 框架里的真实代码结构](#Agent 框架里的真实代码结构)
- 任务拆分方式:Plan-and-Execute(更稳定)




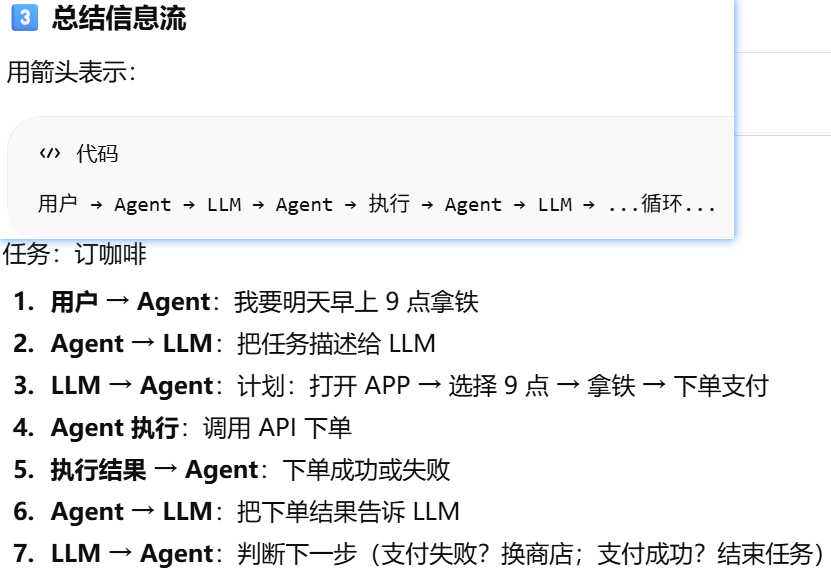
LLM 本身是无状态的处理器和Agent 的”记忆”,怎么理解



网页版的 ChatGPT 或 Claude 本身就是一个封装好的 Agent 系统。



如果真的”只有 LLM”会怎样?
agent 记忆


agent短期记忆和长期记忆


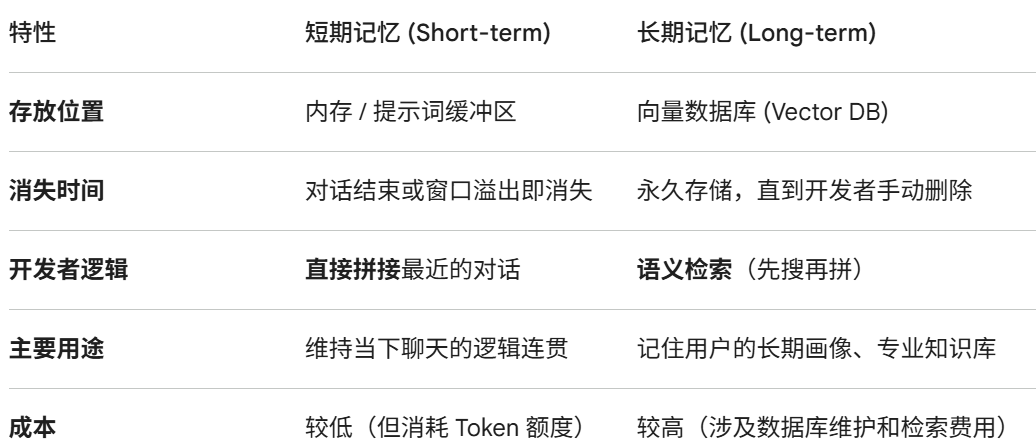


agent记忆存在哪里






举例:假设你有一个包含 100 个文件的项目,你想让 AI 帮你改一个登录 Bug




Agent 是如何被写出来的。记忆?自动拼接上下文?什么时候查询数据库?什么时候调用”LLM?什么时候不在调用llm?
记忆
拼接历史上下文
什么时候查询
什么时候调用llm



什么时候不在调用llm


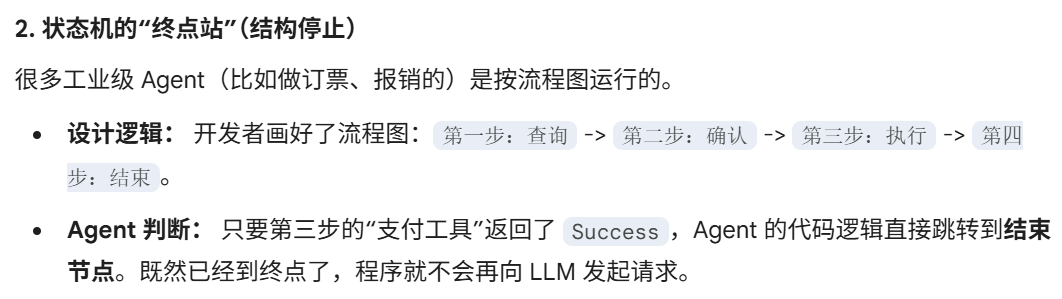



MCP(Model Context Protocol,模型上下文协议)





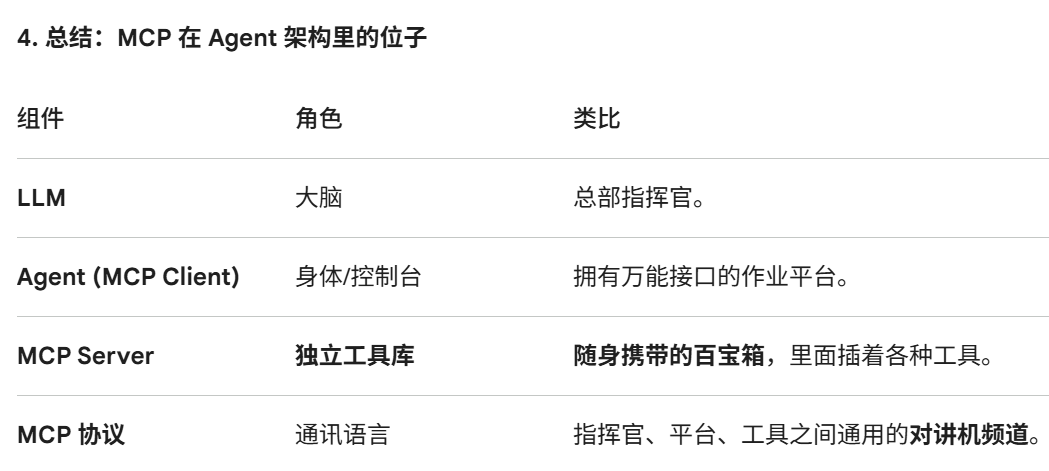
MCP 的核心架构:mcp客户端,mcp服务器,资源


MCP 实际上是一种基于 JSON-RPC 的通信协议


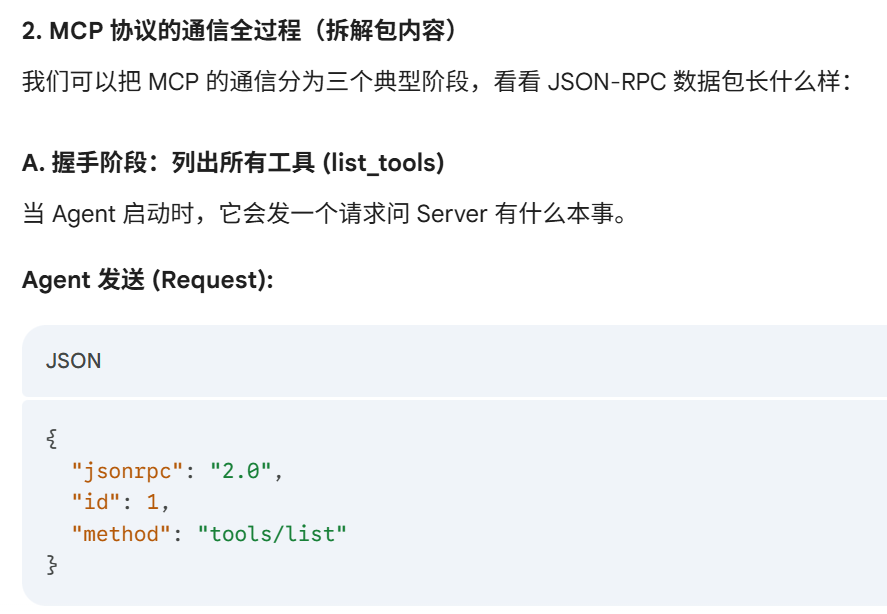
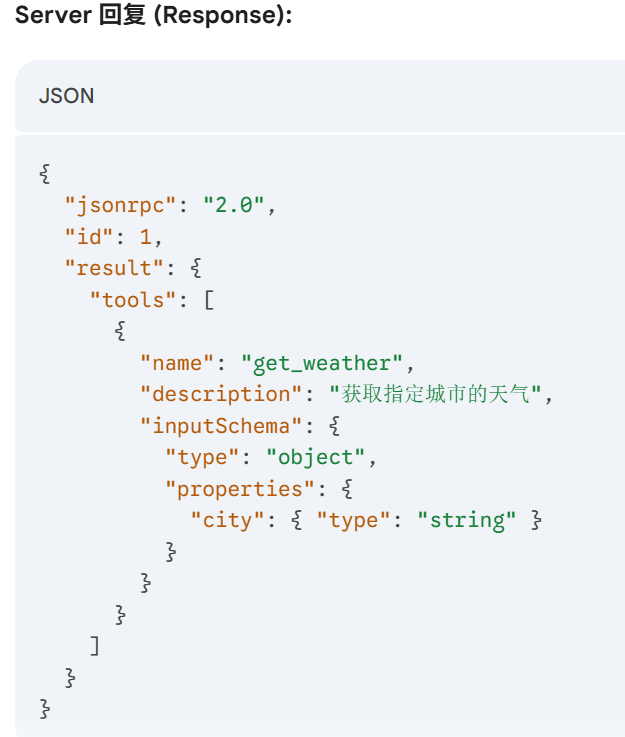
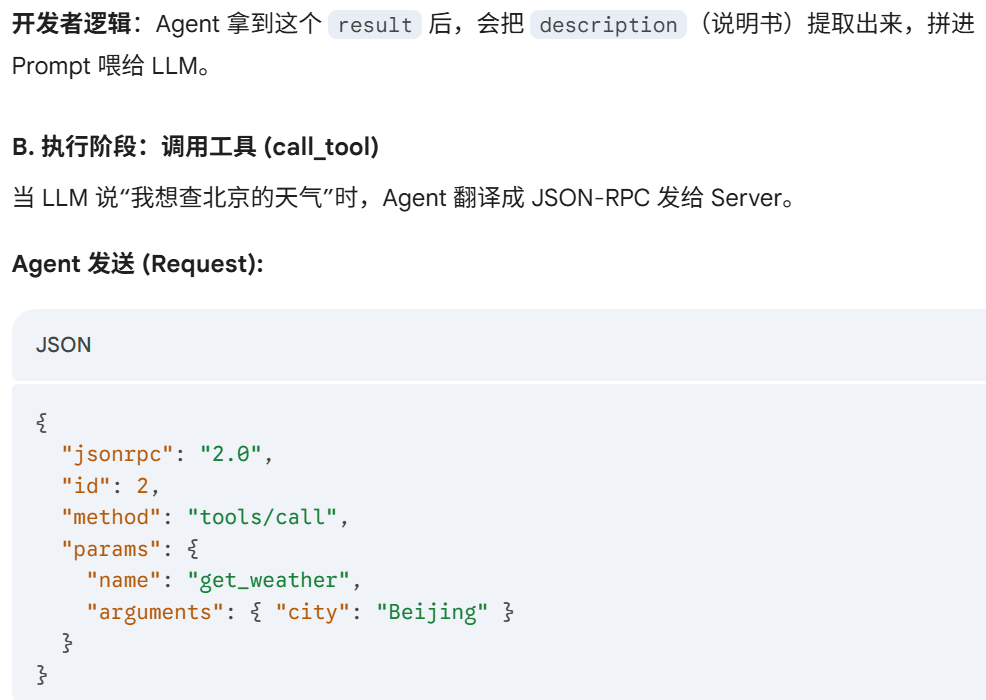



JSON-RPC 是什么




API 和 JSON-RPC 是什么


JSON-RPC 数据包的”运输方式”:stdin/stdout 或 HTTP










SSE (Server-Sent Events) 是一种”单向常连”技术。它允许服务器在建立连接后,像源源不断的流水一样,主动把数据推送到客户端(Agent),而不需要客户端反复询问






sse与普通http区别





流式(Streaming)是数据传输方式,SSE 是实现流式的一种技术









判断是否是MCP 客户端 (如支持mcp的Agent):







判定一个服务器是否为 MCP 服务器的”三个标准”



MCP 服务器的作用:MCP 是 Agent 和外部工具之间的桥梁/调度中心。如果工具在 MCP 上:直接调用函数。如果工具在外部服务:通过 HTTP / gRPC / RPC 调用
为什么 MCP 可以统一调用工具
统一注册:所有工具在 MCP 上注册,包含名字、接口类型、参数格式
统一调度:agent根据function_call,按照json_rpc格式,发送到mcp服务器,mcp服务器自动路由到对应工具
统一返回:把工具执行结果按照json_rpc的格式返回agent,agent解析后,把工具执行结果封装成 role=function 消息返回 LLM
安全与权限控制:MCP 可以限制哪些工具可调用





api/json-prc
agent怎么知道有哪些工具?llm怎么知道有哪些工具



agent调用工具怎么知道要输入哪些内容,哪些参数
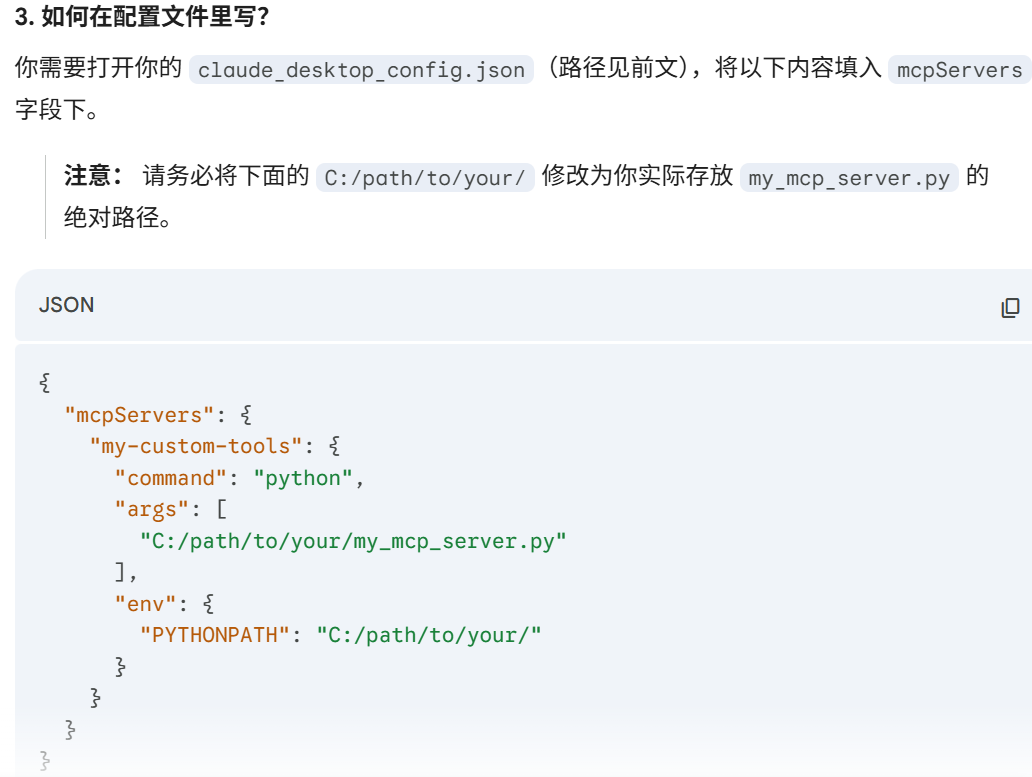
Agent 是通过工具的参数 schema + LLM 语义理解,自动推断并填充工具参数的



例子










Agent 怎么知道发给哪个 LLM? 给agent配置哪个llm就用哪个
Agent 发送请求到llm,需要 配置LLM 的哪些参数?
一般来说,Agent 通过 API 调用 LLM,需要提供 三个核心参数:
Model ID

举例

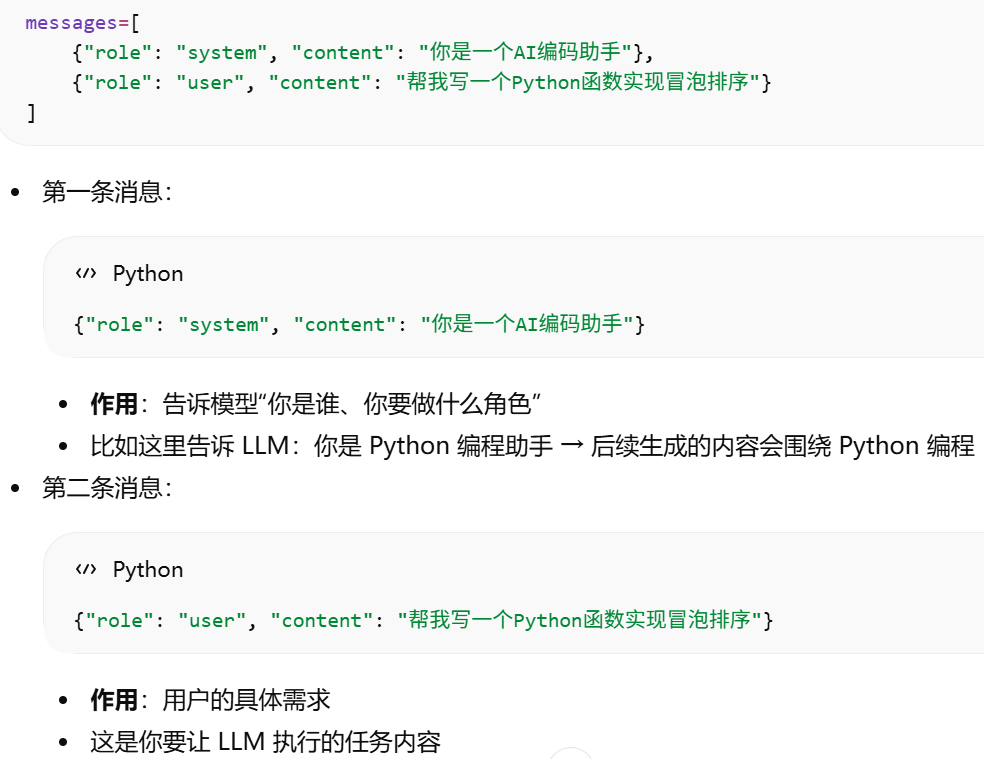
messages 列表 = Prompt,只是格式化成多条消息。system role = 设定模型身份/行为规则。user role = 用户输入/任务。assistant role 也是 Prompt(messages)的一部分,模型自身的角色,主要用于记录 LLM 自己之前的输出,让模型理解上下文、保持连贯性






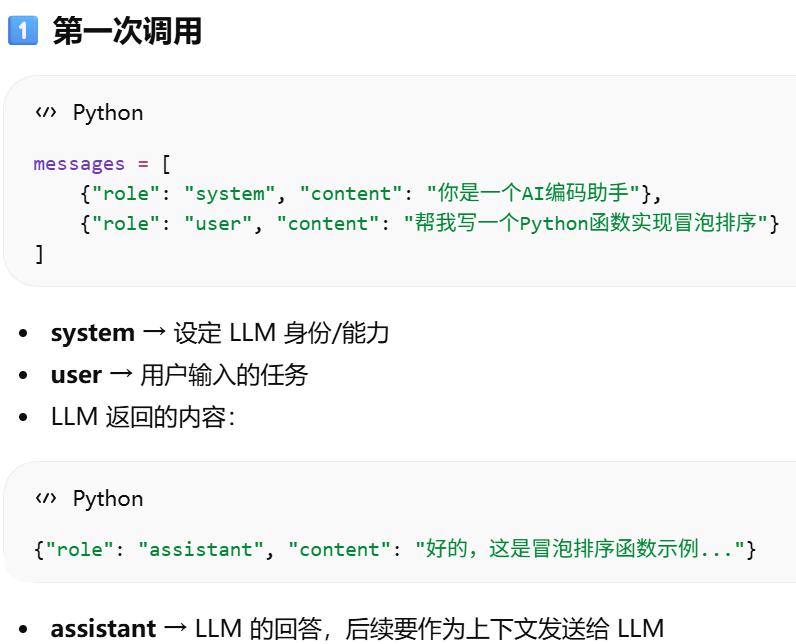

怎么实现工具才能让agent调用








tool/list 返回的内容,是 Schema 还是工具列表,以及谁生成 Schem






OpenAI 定义了一种”程序怎么调用大模型”的 API 写法,后来几乎所有模型公司都照着做了。
所以它被称为 事实标准(de facto standard)。




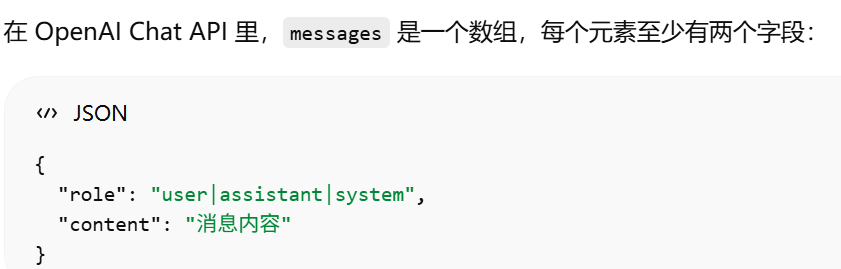
system
user
assistant
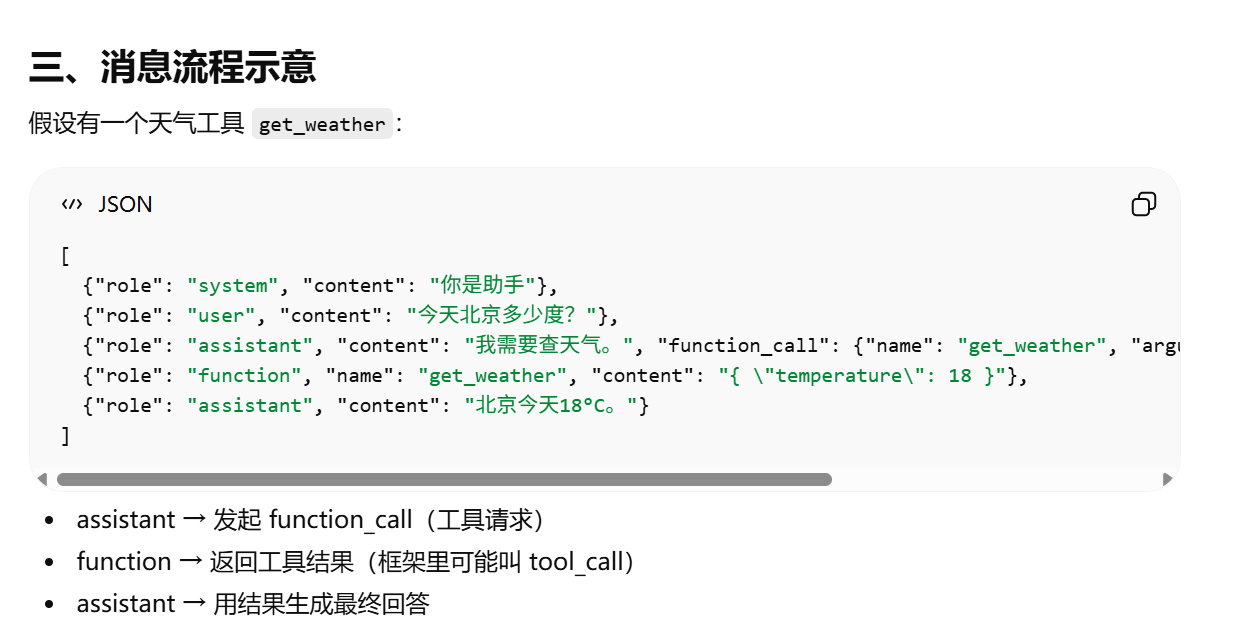
Function Call 的本质



role: function(可选) → 标识这是工具调用结果
工具调用的结果在 OpenAI 的 Chat API 里会以 role = “function” 的消息形式返回给模型,模型再根据这个内容生成回答。







“调用 API 不一定要写 URL”,URL 只是 HTTP REST 的形式;
API 本质上就是 函数的远程版本。远程的函数
调用 API 的形式。http api/grpc等都是rpc的实现方式
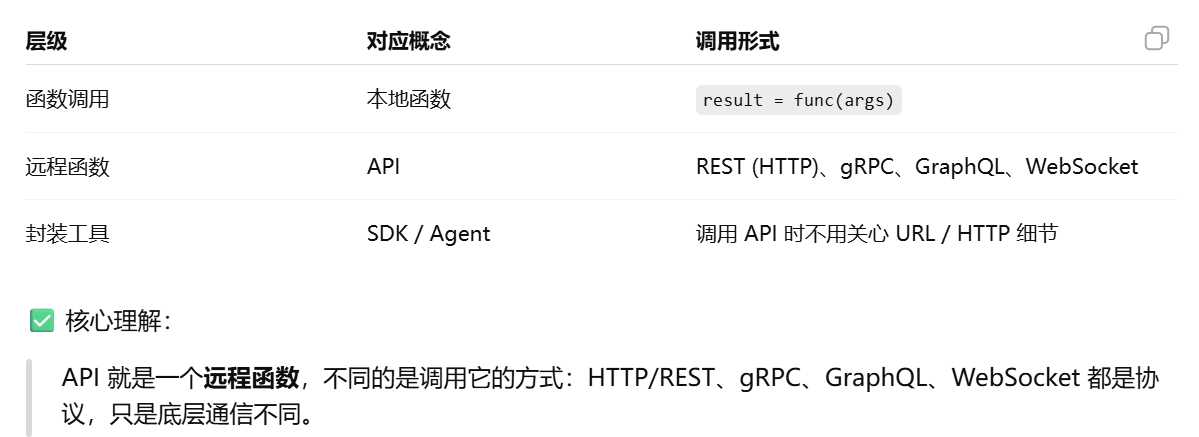

http rest
“调用 API 不一定要写 URL”,URL 只是 HTTP REST 的形式;SDK、Agent 框架、CLI、Webhook
等都是不同的封装形式,底层其实还是调用同一个 API,只是你不用自己拼 URL。
gRPC / RPC / GraphQL / WebSocket 流式.也是调用远程函数,只是 协议不同
为什么”写了 URL 就是调用 API”。属于http rest形式调取api

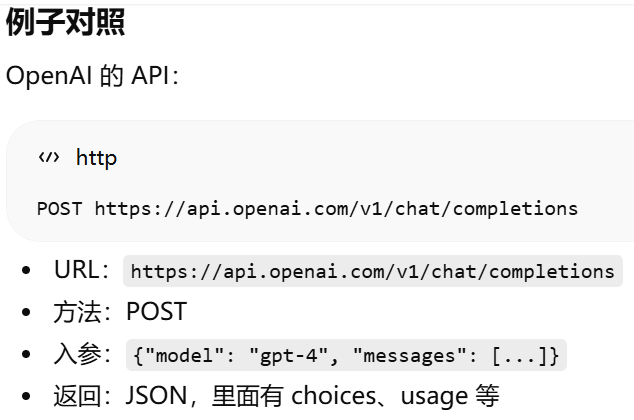
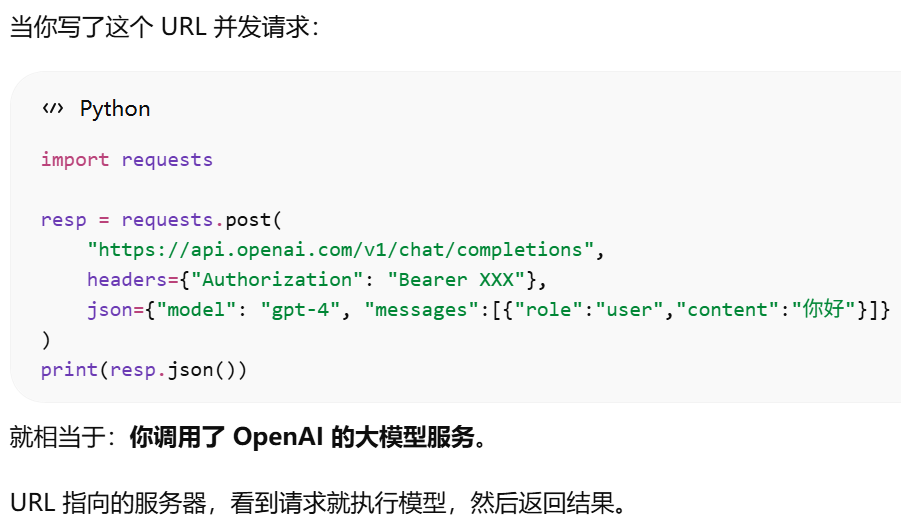
http rest形式:API 调用的四个核心要素.models参数意义


Model(模型参数)





API 的协议层、实现方式和调用方式
协议 / 数据格式”是什么?
协议 = 规则
就像你和朋友约定”聊天时要遵守的规则”:谁先说,谁回答,用什么语言,说完怎么确认收到。
网络上,协议就是计算机之间通信必须遵守的规则,保证双方能理解对方发送的信息。
数据格式 = 规定消息里写的内容怎么排列,就像写信用什么语言和排版。
简单理解:协议是传输规则,数据格式是内容排版。
协议 = 你用什么方式寄信:普通邮寄 / 快递 / 高速专线(HTTP / HTTP2 / WebSocket/sse)
数据格式 = 信里怎么写:用中文、英文、二进制编码(JSON / protobuf)。
协议 / 数据格式 = 消息怎么从你电脑传到服务器
不同协议:HTTP、HTTP/2、WebSocket
不同格式:JSON、protobuf
组合使用:
HTTP + JSON → 普通 API 调用
HTTP/2 + protobuf → gRPC 高效调用
WebSocket + JSON → 流式实时返回
详细解释
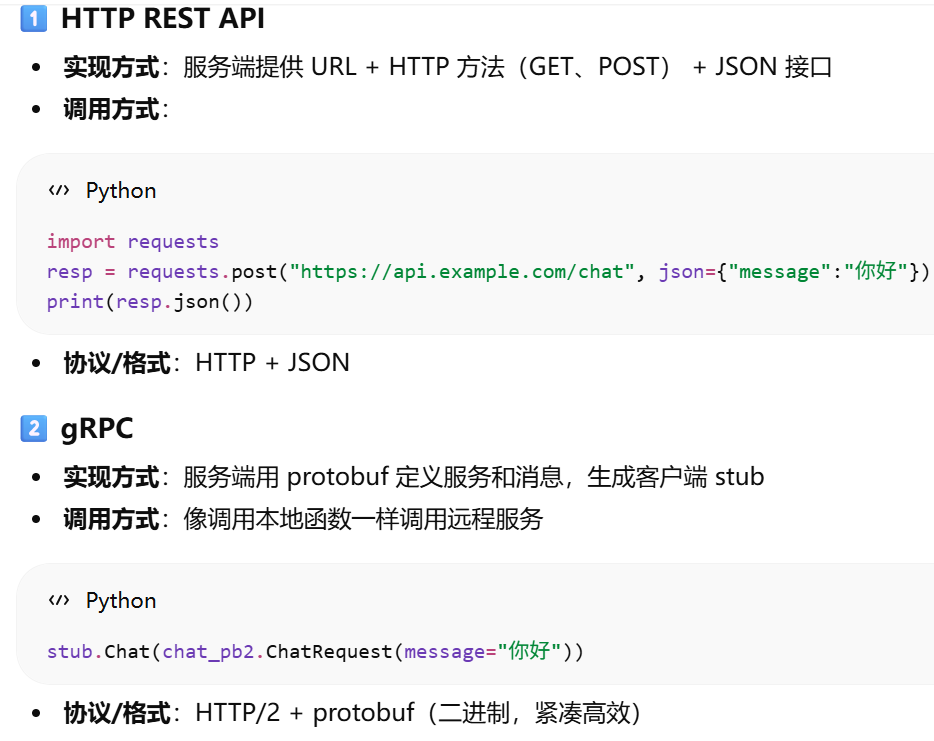



调用方式(风格) → 逻辑上”我怎么告诉服务端我想干什么”
REST、gRPC、GraphQL、JSON-RPC、WebSocket
实现方式(协议+数据格式) → 技术上”数据怎么在网络上传输”
HTTP + JSON、HTTP/2 + protobuf、WebSocket + JSON
选择方式:
如果服务端是 REST → 只能用 HTTP + JSON
如果服务端是 gRPC → 生成 stub,用 HTTP/2 + protobuf
如果服务端支持流式 → WebSocket / SSE
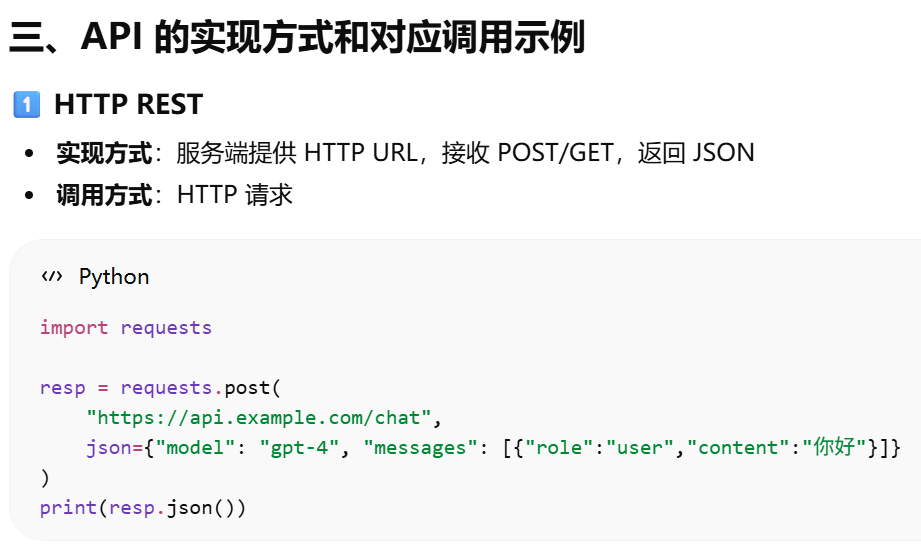
API 的实现方式和对应调用示例



选择哪一种形式
具体使用哪种形式,取决于几个因素:
API 的实现方式
如果服务端是 REST API → 只能用 HTTP 请求调用
如果服务端是 gRPC → 需要生成对应语言的 gRPC stub 调用
如果支持 JSON-RPC → 按 JSON-RPC 协议请求
换句话说,客户端调用方式必须匹配服务端实现协议
API(Application Programming Interface)
概念:接口的总称,指”调用某个功能的方法或约定”
广义理解:任何一种程序可以调用另一个程序功能的方式
实现方式多种多样:
HTTP REST API
gRPC
GraphQL
JSON-RPC
WebSocket / 流式 API
API = “抽象接口”,不限定协议和数据格式
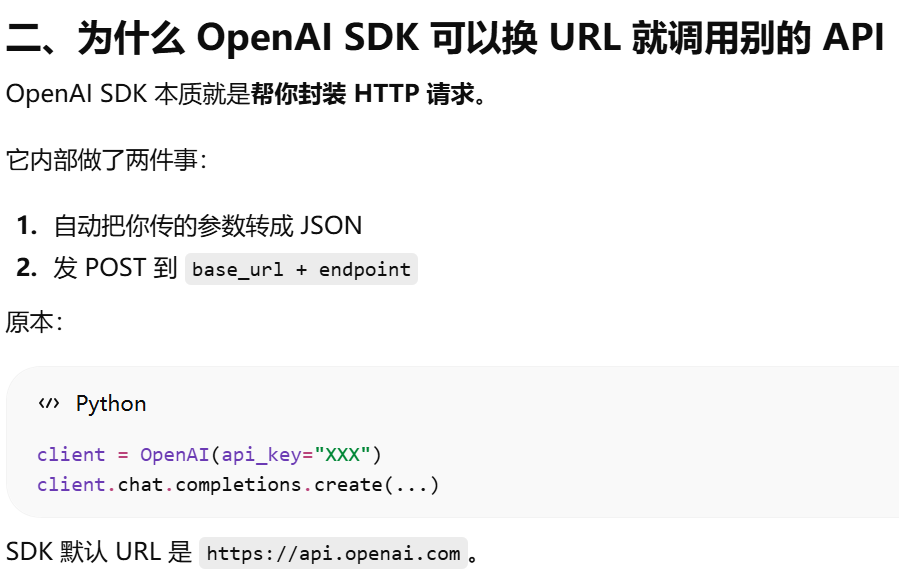
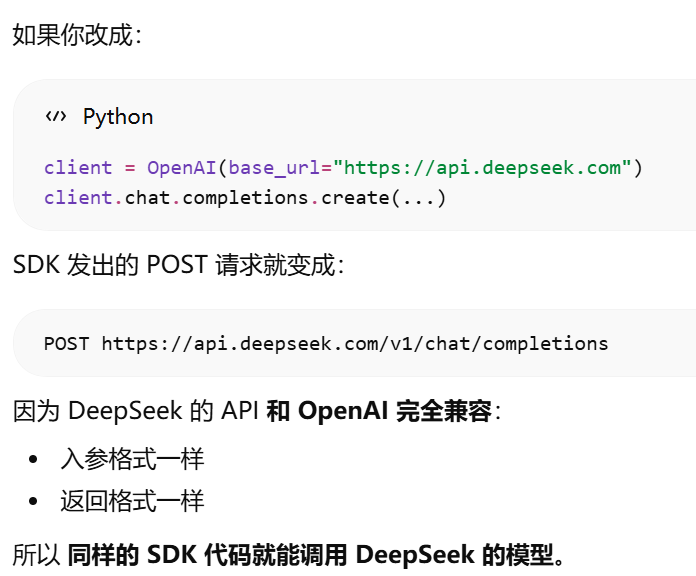
为什么 OpenAI SDK 可以换 URL 就调用别的 API?http rest形式调用api时,换url就是换api了。还可以使用openai sdk是因为别人的api的参数和返回结果与openai一样

Function Calling / Tool Calling 标准

JSON Schema 作为工具参数标准
JSON Schema 在工程里的三个典型用途。很多人第一次看到会懵,因为它其实是在说 Schema = 一种机器可读的接口说明书


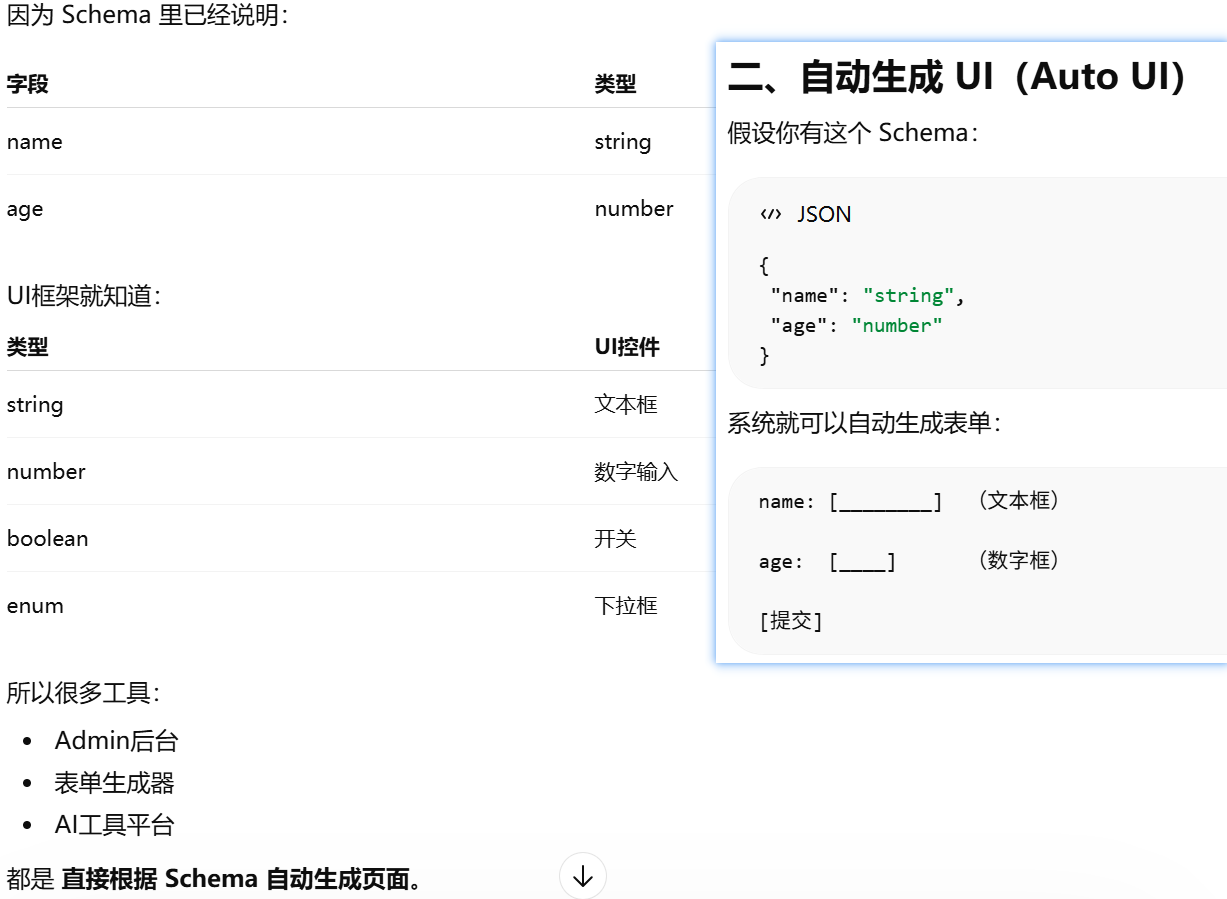
SDK = Software Development Kit(软件开发工具包)





Chat Message 协议,OpenAI 还定义了 对话消息结构标准
后来 Anthropic 提出了 Model Context Protocol (MCP)。把 OpenAI Function Calling 的思想扩展成跨工具协议
OpenAI后来又加了一条标准:模型输出必须符合指定 JSON Schema
五、OpenAI后来补充的标准
2023 → 2025 OpenAI不断补充。
主要新增:
1 Tool Calling(工具调用升级)
支持:
多工具
并行调用
自动选择
例如:
tools=[search, weather, db]
AI自己选。
2 Strict Mode
保证输出 100%符合 Schema。
例如:
“strict”: true
否则会报错。
3 Streaming Tool Calls
工具参数可以 边生成边调用。
降低延迟。
4 Parallel Tool Calls
AI一次调用多个工具。
例如:
查天气
查航班
查酒店
同时执行。
七、后续的新标准(不是 OpenAI)
最近 AI 生态又出现 两个新的协议:
1 MCP(Model Context Protocol)
作用:
标准化 AI 如何接工具。
流程:
Agent
↓
MCP server
↓
Tool
很多 IDE 在用:
Cursor
Claude Desktop
Windsurf
2 A2A(Agent to Agent)
让 AI 与 AI 协作。
例如:
规划Agent
编码Agent
测试Agent
互相通信。
八、整个 AI 标准体系(现在)
目前行业结构是:
LLM
│
│ Function Calling(OpenAI)
│
Agent Framework
│
│ MCP(工具协议)
│
Tools / APIs
再往上是:
Multi-Agent
(A2A)
Agents SDK
最新 Agent 标准:
https://platform.openai.com/docs/agents
包括:
tool
memory
workflow
tracing



任务拆分实现方式:Prompt-based Planning(最常见)


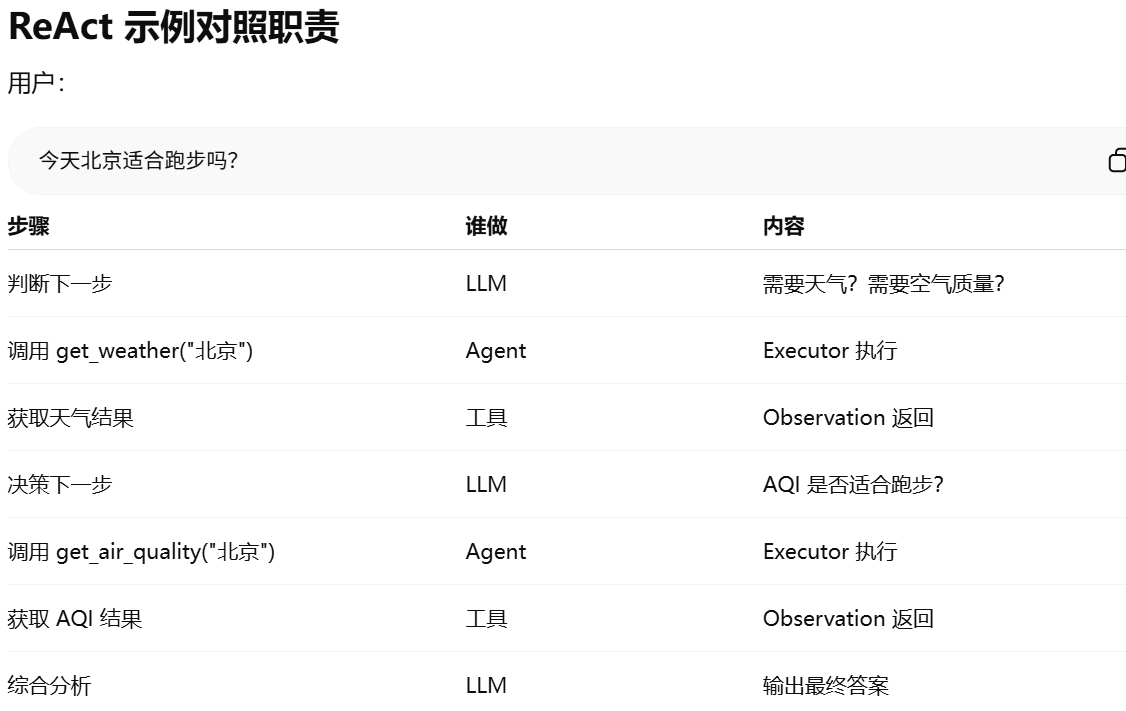
任务拆分实现方式:ReAct(最经典 Agent 方法)。Thought → Action → Observation
在 Thought → Action → Observation(ReAct 模式) 里:
Thought = LLM 内部生成的意图 / 下一步计划
Action = 调用工具(role=function)
Observation = 工具执行结果返回模型(role=function)
Observation 就是把 Action 执行后的结果返回给 LLM,让 LLM”看到”这个结果,再继续推理。




Agent 框架里的真实代码结构


任务拆分方式:Plan-and-Execute(更稳定)


发布者:Ai探索者,转载请注明出处:https://javaforall.net/285545.html原文链接:https://javaforall.net


