
生成式 AI 的迭代速度早已超出想象,新术语、新技术层出不穷,稍不留意就可能跟不上行业节奏。RAG(检索增强生成)与 Agent(智能体)作为大语言模型(LLM)落地的两大核心应用范式,早已被从业者熟知。但最近频繁出现的 “Agentic RAG”,却让不少人犯了难 —— 它到底是 RAG 的升级版本,还是 Agent 的特殊形态?今天我们就从技术逻辑、应用场景到架构设计,全方位拆解 Agentic RAG,帮你彻底理清它的本质。
1、为什么需要Agentic RAG?
要理解 Agentic RAG 的价值,得先回到它的 “前身”—— 传统 RAG。简单来说,RAG 是通过引入外部检索到的知识,弥补 LLM 自身知识库的局限性,既能减少 “一本正经胡说八道” 的幻觉问题,又能让模型快速适配垂直领域需求。打个比方:传统 RAG 就像给 LLM 配了一个 “固定书架”,模型需要信息时只能从这个书架里找,虽然比 “凭记忆回答” 靠谱,但书架的范围和用法都是固定的。
RAG = LLM + 知识库 + 检索器
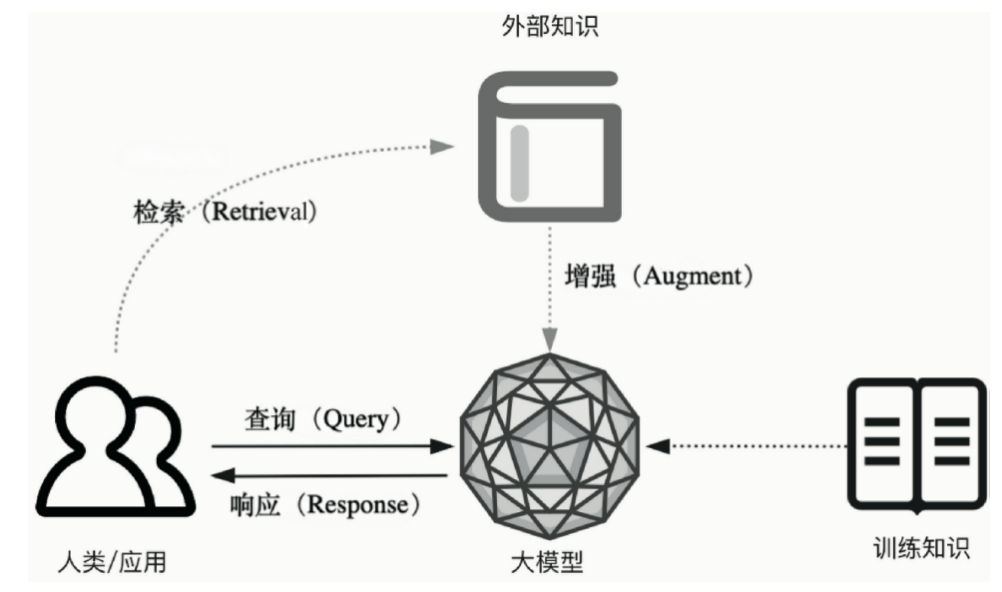

它可以让AI准确的回答诸如这样的问题:
- 公司的财务报销审核流程是怎样的?
- 上半年销售业绩前三名代理商是谁?
- 总结公司最新财报中的关键要点?
但随着企业应用场景的复杂化,传统 RAG 的 “固定书架” 开始暴露出明显短板。我们不妨看看这些真实业务中的查询需求:
场景 1:不同类型查询需要 “灵活切换工具”
同样是查询产品信息,用户可能问 “某型号笔记本的电池容量”(事实性查询),也可能问 “对比该笔记本与上一代的核心升级点”(分析性查询),还可能问 “总结该笔记本的用户差评核心原因”(总结性查询)。传统 RAG 的单一检索逻辑,很难同时适配这三类需求 —— 事实性查询需要精准匹配,分析性查询需要关联对比,总结性查询需要语义提炼,用一套检索规则应对所有场景,结果要么 “答非所问”,要么 “信息不全”。
场景 2:复杂问题需要 “跨数据源整合”
比如业务人员可能问:“找出本季度回款率最高的 3 家经销商,并整理他们近半年的合作项目与客户反馈”。这个问题里,“回款率” 存放在财务数据库(结构化数据),“合作项目” 记录在 CRM 系统的文档中(非结构化数据),“客户反馈” 则分散在客服系统的标签与评论里(半结构化数据)。传统 RAG 只能对接单一数据源,根本无法完成这种 “跨库联动” 的查询。
场景 3:动态需求需要 “调用外部工具”
再比如市场人员的需求:“对比我司新品与竞品 A、B 的核心功能差异,并抓取近一个月科技媒体对三者的评价关键词”。要满足这个需求,不仅需要从公司内部知识库调取 “新品功能”(本地检索),还需要通过网页搜索获取 “竞品信息”(外部检索),甚至需要调用舆情分析 API 提取 “媒体评价关键词”(工具调用)。传统 RAG 没有 “工具调用意识”,自然无法完成这类 “动态拓展” 的任务。
场景 4:结果质量需要 “自我反思优化”
传统 RAG 的流程是 “检索→拼接上下文→生成回答”,一旦检索到的信息不完整或不准确,模型只会 “照单全收”,不会主动检查 —— 比如查询 “2024 年公司营收数据” 时,若检索到的是 2023 年的旧数据,模型会直接基于旧数据回答,不会质疑 “数据是否过期”,也不会尝试 “重新检索最新数据”。这种 “无反思” 的机制,在对准确性要求极高的场景(如财务分析、合规查询)中风险极高。
正是这些传统 RAG 无法突破的瓶颈,催生了 “更聪明” 的 Agentic RAG—— 它不是对 RAG 的否定,而是用 Agent 的 “自主决策能力”,给 RAG 装上 “大脑”,让它能应对更复杂的业务场景。
2、什么是Agentic RAG?
Agentic RAG就是一种融合了Agent能力的RAG,而Agent的核心能力是自主推理与行动。所以Agentic RAG就是将AI智能体的自主规划(如路由、行动步骤、反思等)能力带入到传统的RAG,以适应更加复杂的RAG查询任务。
Agentic RAG如何应对这些典型的复杂任务?一起来看。
- 在不同类型的RAG管道间自主选择(路由),以适应任务的多样性:
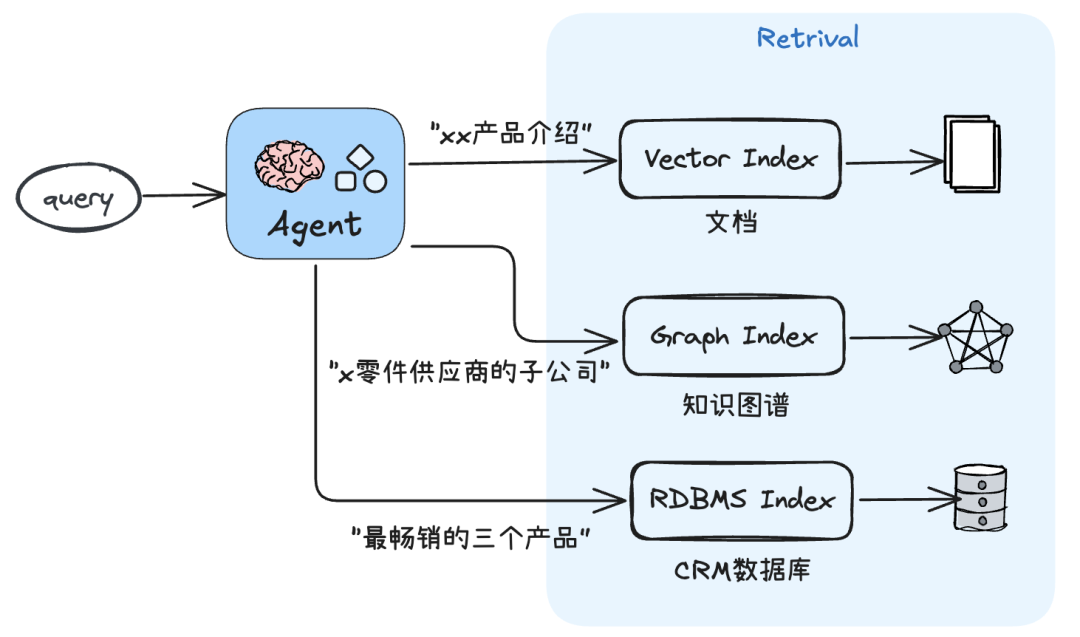
- 融合多种类型的RAG管道与数据源,以适应综合性复杂查询任务:
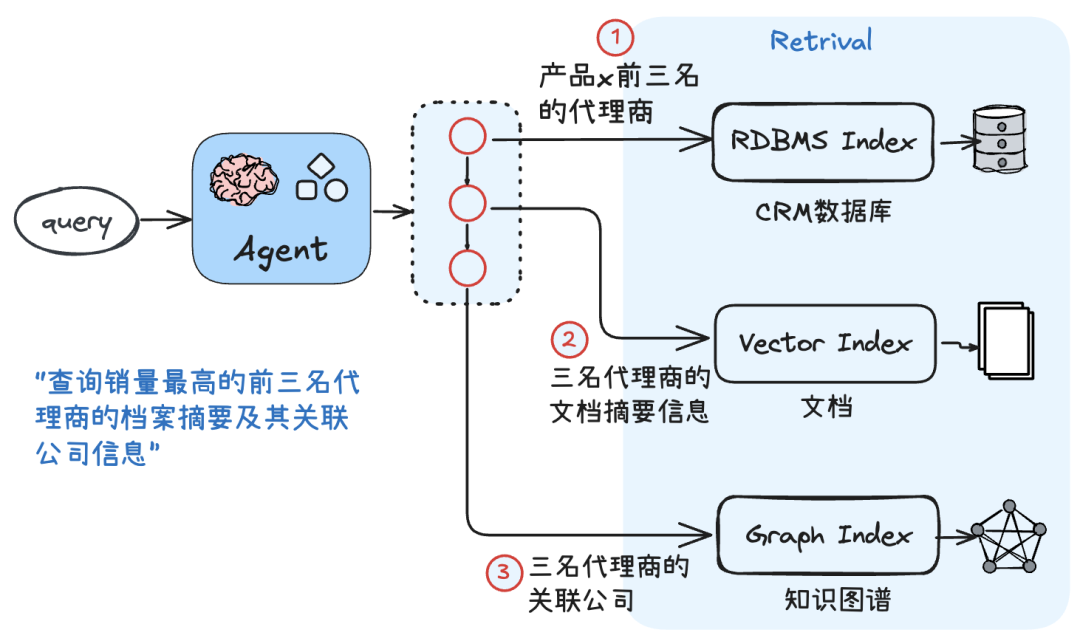
- 与必要的外部工具协作,以增强输出的准确性:
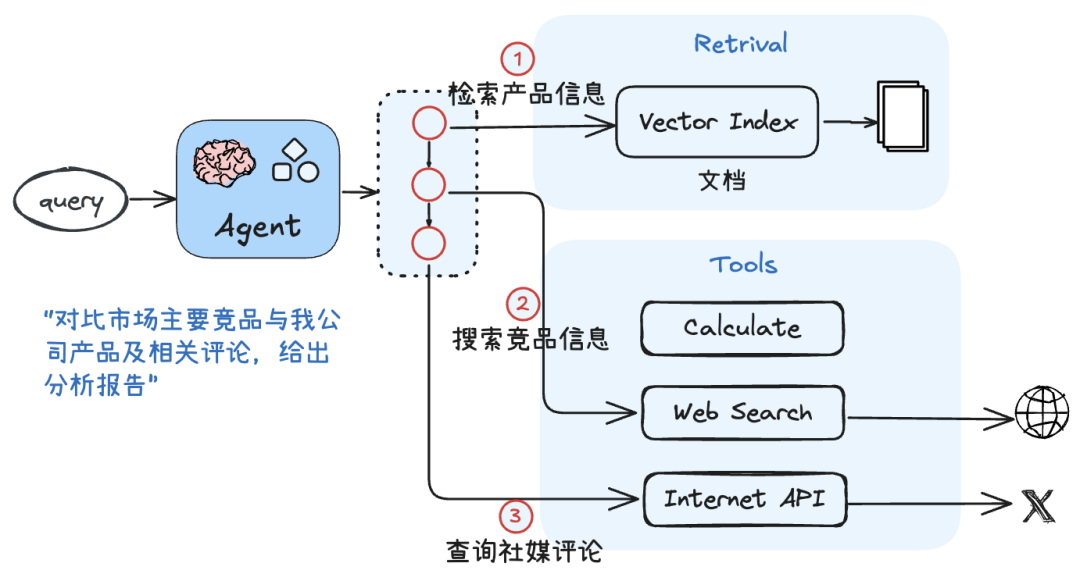
总结来说,Agentic RAG 的 “智能体属性” 主要体现在检索决策阶段,相比传统 RAG,它多了 5 个关键能力:
- 自主判断 “是否需要检索”(比如简单常识问题无需检索,直接回答);
- 自主选择 “用哪个检索器”(根据问题类型匹配检索工具);
- 自主规划 “检索步骤”(拆解复杂任务,分步骤检索);
- 自主评估 “检索结果”(检查信息质量,决定是否重新检索);
- 自主调用 “外部工具”(补充检索无法覆盖的需求)。
3、Agentic RAG VS 传统RAG
Agentic RAG在整体流程上与传统RAG一脉相承:检索-合成上下文-生成,但由于融入了Agent的自主能力,从而具有更强的适应性与任务质量。
这里的传统RAG指遵循“检索-上下文-生成”单一顺序流程的RAG应用。随着开发框架的不断完善,当前一些常用的高级RAG模块已经具备了部分Agentic的特征,比如:语义路由、多步骤查询转换、子问题查询转Agent 智能体换等。
4、Agentic RAG技术架构
与顺序式的传统RAG架构相比,Agentic RAG的核心是Agent,而RAG管道(通常是检索器,也可能是完整的RAG查询引擎)则可以看作是Agent使用的一种工具,从而完美的融合到Agent的架构中。
从这个角度说,Agentic RAG是RAG,但更是Agent。 从技术架构看,也存在单Agent架构与多Agent架构。
【单Agent的Agentic RAG】
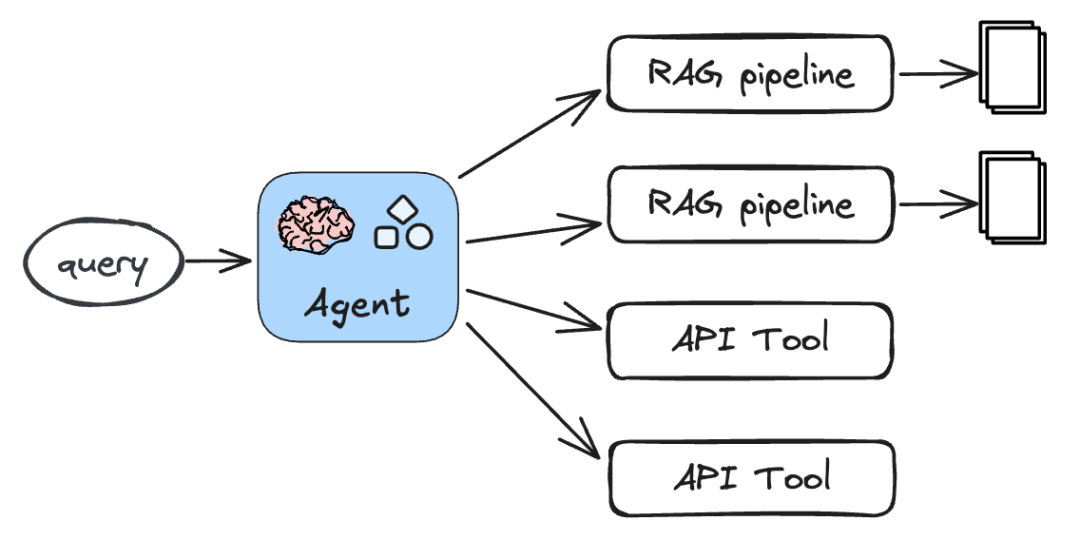
在这个架构中,只有一个具有自主能力的Agent。RAG管道与外部工具都作为Tool提供给Agent,Agent根据输入问题规划与决策这些工具的使用,检索与累积更全面的上下文,最后输出全面而准确的结果。
如果这里的Agent每次规划只会选择一个后端RAG检索管道,那么也就退化成了一个语义路由器模块。
【多Agent的Agentic RAG】
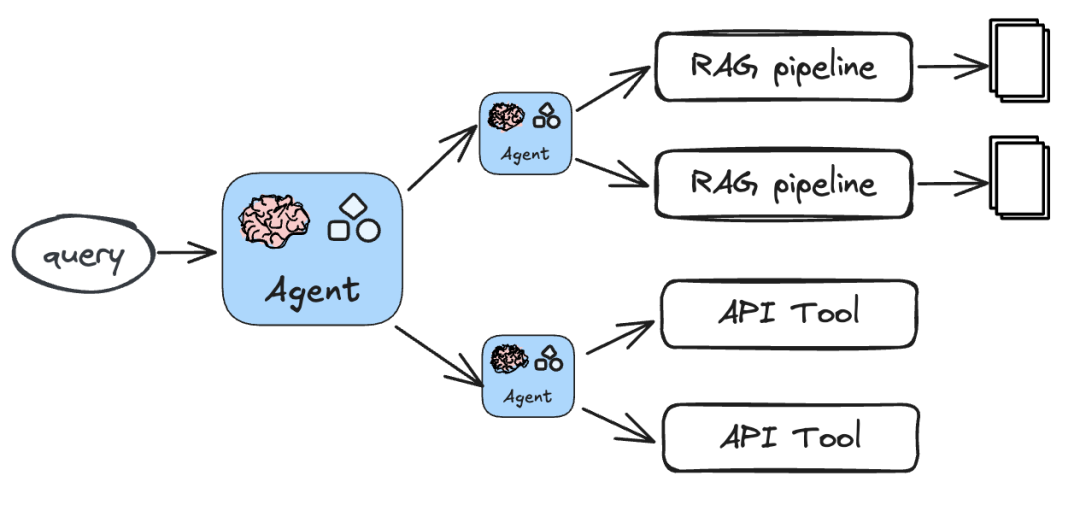
这是一个多层的Agent架构:一个顶层的Agent负责协调多个二级Agent,每个二级Agent再负责特定领域或特定类型的检索或查询任务,可以根据需要灵活划分不同Agent的职责。
比如,你可以这样设计:
- Agent1负责企业内部知识库的检索。协调使用多个不同索引类型的检索器,如向量、知识图谱、甚至SQL检索。
- Agent2负责客户相关数据的检索任务。协调使用多个不同地区客户数据的检索器。
- Agent3负责借助各种工具从互联网检索必要的外部信息。
- 顶层的Agent则负责管理与协调使用上面三个Agent来共同完成复杂查询任务,实现任务拆分、派发与搜集结果,并最终响应用户。
多Agent的Agentic RAG架构具备更大的灵活性,实际开发中,你可以对不同的Agent进行单独规划、实现与调试,最后组合成一个更完备的RAG系统,提供超越传统的查询能力。
5、总结
Agentic RAG通过将智能体的核心能力引入到传统RAG,借助Agent的规划与推理能力,极大的增强了RAG检索的全面性、灵活性与准确性,使得能够执行更复杂与多样的数据密集型的查询任务,激发了RAG应用的新潜力。
当然,进步也伴随着挑战。利用智能体思想完成复杂任务也带来了对LLM的更深层依赖,引发了新的响应延迟与不确定性的问题。因此,在开发和使用 Agentic RAG 系统时,需要审慎考虑其优劣,以实现更高效和可靠的应用。
这里给大家精心整理了一份,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料!
扫码免费领取全部内容

要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

扫码免费领取全部内容

发布者:Ai探索者,转载请注明出处:https://javaforall.net/285728.html原文链接:https://javaforall.net


