
MySQL中的日志包括:通用查询日志、慢查询日志、错误日志、二进制日志等等。这里主要记录一下两种比较常用的日志:通用查询日志和慢查询日志。
(1)通用查询日志:记录建立的客户端连接和执行的语句。
(2)慢查询日志:记录所有执行时间超过long_query_time 秒的所有查询或者不使用索引的查询。
一、通用查询日志:
1、查看当前通用日志查询是否开启:
show variables like ‘%general%’;


如果general_log 的值为ON则为开启,为OFF则为关闭(默认关闭)
2、查看通用日志的输出格式:
show variables like ‘%log_output%’;

通用查询日志输出的格式可以是FILE(存储在数据库的数据文件中的hostname.log),也可以是TABLE(存储在数据库中的mysql.general_log)
3、开启MySQL通用查询日志 与 设置通用日志输出方式:
set global general_log=on; ##开启通用日志查询
set global general_log=off; ##关闭通用日志查询
set global log_output=’File; ##设置通用日志文件输出为文件方式
set global log_output=’TABLE’; ##设置通用日志文件输出为表方式
set global log_output=’File,TABLE’; ##设置通用日志文件输出为文件和表方式
(注意:上述命令只对当前生效,当MySQL重启失效,如果要永久生效,需要配置my.cnf或者my.ini文件,见第5点)
4、日志输出效果图:
(1)记录到mysql.general_log表中的数据如下:
select * from mysql.general_log;

记录到本地中的.log中的格式如下:
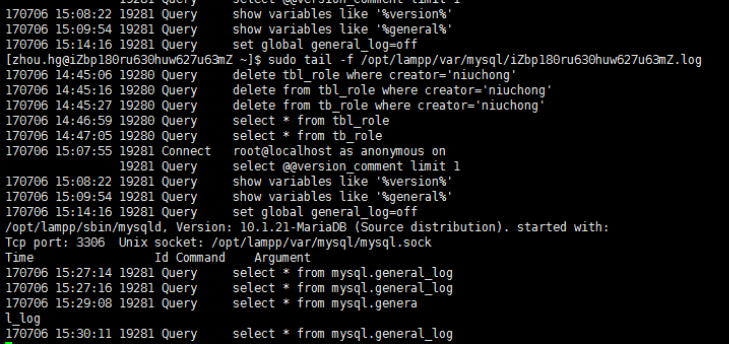
5、修改配置文件:
在my.cnf 或者my.ini 文件的 [mysqld]下的下方加入:
general_log=1 #为1表示开启通用日志查询,值为0表示关闭通用日志查询
log_output=FILE,TABLE#设置通用日志的输出格式为文件和表
二、慢查询日志:
MySQL的慢查询日志用来记录在MySQL中响应时间超过阈值的语句,具体指运行时间超过 long_query_time 值的SQL,则会被记录到慢查询日志中(日志可以写入文件或者数据库表,如果对性能要求高的话,建议写文件)。默认情况下,MySQL数据库是不开启慢查询日志的,long_query_time的默认值为10(即10秒,通常设置为1秒),即运行10秒以上的语句是慢查询语句。
一般来说,慢查询发生在大表(比如:一个表的数据量有几百万),且查询条件的字段没有建立索引,此时,要匹配查询条件的字段会进行全表扫描,耗时查过long_query_time,则为慢查询语句。
默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。
1、查询慢查询日志的开启情况:
show variables like ‘%quer%’;
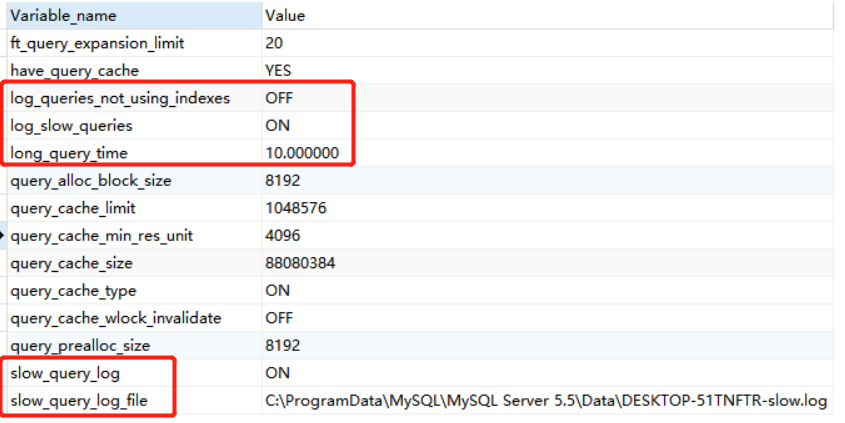
主要掌握以下的几个参数:
①slow_query_log 的值为ON为开启慢查询日志,OFF则为关闭慢查询日志。
②slow_query_log_file 的值是记录的慢查询日志到文件中路径(注意:默认名为主机名.log,慢查询日志是否写入指定文件中,需要指定慢查询的输出日志格式为文件,相关命令为:show variables like ‘%log_output%’;去查看输出的格式)。
③long_query_time 指定了慢查询的阈值,即如果执行语句的时间超过该阈值则为慢查询语句,默认值为10秒。
④log_queries_not_using_indexes 如果值设置为ON,则会记录所有没有利用索引的查询(注意:如果只是将log_queries_not_using_indexes设置为ON,而将slow_query_log设置为OFF,此时该设置也不会生效,即该设置生效的前提是slow_query_log的值设置为ON),一般在性能调优的时候会暂时开启。
2、慢查询相关配置(临时):
如果都是通过MySQL的shell将参数设置进去,重启MySQL后,所有设置好的参数将失效,如果想要永久的生效,需要将配置参数写入my.cnf文件中。
开启慢查询日志设置:
set global slow_query_log=’ON’;
set global slow_query_log=’OFF’; ##关闭慢查询日志
设置慢查询日志存放的位置:
set global slow_query_log_file=’/usr/local/mysql/data/slow.log’;
设置超时记录的阈值:
set long_query_time = 1;
3、慢查询相关配置(永久):
在my.cnf 或者my.ini 文件的 [mysqld]下的下方加入以下配置,重启MySQL服务:
[mysqld]
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slow.log
long_query_time = 1
4、设置慢查询存储的方式(默认是none):
set global log_output=’File; ##设置通用日志文件输出为文件方式
set global log_output=’TABLE’; ##设置通用日志文件输出为表方式
set global log_output=’File,TABLE’; ##设置通用日志文件输出为文件和表方式
5、执行测试sql语句:
select sleep(2);
6、慢查询日志记录:
(1)慢查询的日志记录myql.slow_log表中,格式如下:
select * from mysql.slow_log;

慢查询的日志记录到hostname.log文件中,格式如下:
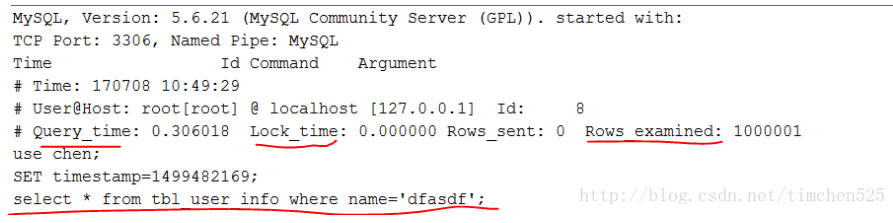
可以看到,不管是表还是文件,都具体记录了:是那条语句导致慢查询(sql_text),该慢查询语句的查询时间(query_time),锁表时间(Lock_time),以及扫描过的行数(rows_examined)等信息。
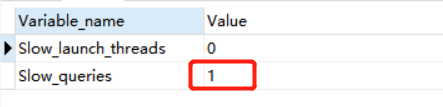
7、查询当前慢查的语句的个数:
show global status like ‘%slow%’;
三、使用慢查询日志分析工具mysqldumpslow分析日志:
我们通过查看慢查询日志可以发现,很乱,数据量大的时候,可能一天会产生几个G的日志,根本没有办法去清晰明了的分析。所以,这里,我们采用MySQL自带的慢查询日志分析工具析日志 mysqldumpslow工具进行分析。
查看 mysqldumpslow 的帮助信息:mysqldumpslow –help
-s: 表示按何种方式排序:
c: 访问次数
l: 锁定时间
r: 返回记录
t: 查询时间
al: 平均锁定时间
ar: 平均返回记录数
at: 平均查询时间
-t: 返回前面多少条的数据;
-g: 后边搭配一个正则匹配模式,大小写不敏感的。
得到返回记录集最多的10个SQL:
mysqldumpslow -s r -t 10 /var/lib/mysql/show.log
得到访问次数最多的10个SQL:
mysqldumpslow -s c -t 10 /var/lig/mysql/show.log
得到按照时间排序的前10条里面含有左连接的查询语句:
mysqldumpslow -s t -t 10 -g “left join” /var/lig/mysql/show.log
另外建议在使用这些命令时结构 | 和more使用,否则有可能出现爆屏情况:
mysqldumpslow -s r -t 10 /var/lig/mysql/show.log | more
相关博客:
https://blog.csdn.net/timchen525/article/details/75268151
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/100069.html原文链接:https://javaforall.net


