
大家好,又见面了,我是你们的朋友全栈君。
文件参考:https://www.cnblogs.com/tgzhu/p/5788634.html
以写入100M文件为例:

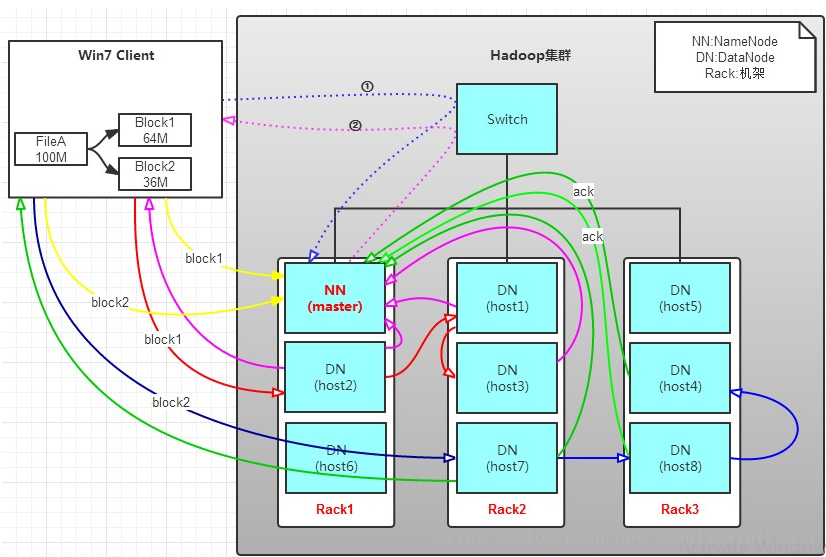
- Client将FileA按64M分块。分成两块,block1和Block2;
- Client向nameNode发送写数据请求,如图蓝色虚线①——>
- NameNode节点,记录block信息。并返回可用的DataNode (NameNode按什么规则返回DataNode? 参见第三单 hadoop机架感知),如粉色虚线②———>
- Block1: host2,host1,host3
- Block2: host7,host8,host4
- client向DataNode发送block1;发送过程是以流式写入,流式写入过程如下:
- 将64M的block1按64k的packet划分
- 然后将第一个packet发送给host2
- host2接收完后,将第一个packet发送给host1,同时client想host2发送第二个packet
- host1接收完第一个packet后,发送给host3,同时接收host2发来的第二个packet
- 以此类推,如图红线实线所示,直到将block1发送完毕
- host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示
- client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
- 发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示
- 说明:
-
- 当客户端向 HDFS 文件写入数据的时候,一开始是写到本地临时文件中。假设该文件的副 本系数设置为 3 ,当本地临时文件累积到一个数据块的大小时,客户端会从 Namenode 获取一个 Datanode 列表用于存放副本。然后客户端开始向第一个 Datanode 传输数据,第一个 Datanode 一小部分一小部分 (4 KB) 地接收数据,将每一部分写入本地仓库,并同时传输该部分到列表中 第二个 Datanode 节点。第二个 Datanode 也是这样,一小部分一小部分地接收数据,写入本地 仓库,并同时传给第三个 Datanode 。最后,第三个 Datanode 接收数据并存储在本地。因此, Datanode 能流水线式地从前一个节点接收数据,并在同时转发给下一个节点,数据以流水线的 方式从前一个 Datanode 复制到下一个
- 时序图如下:

- 小结:
-
- 写入的过程,按hdsf默认设置,1T文件,我们需要3T的存储,3T的网络流量
- 在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去
- 挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份
hdfs读文件:
- 读到文件示意图如下:

- 客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象时分布文件系统的一个实例;
- DistributedFileSystem通过使用RPC来调用NameNode以确定文件起始块的位置,同一Block按照重复数会返回多个位置,这些位置按照Hadoop集群拓扑结构排序,距离客户端近的排在前面 (详见第三章)
- 前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流,客户端对这个输入流调用read()方法
- 存储着文件起始块的DataNode地址的DFSInputStream随即连接距离最近的DataNode,通过对数据流反复调用read()方法,将数据从DataNode传输到客户端
- 到达块的末端时,DFSInputStream会关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode,这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流
- 一旦客户端完成读取,就对FSDataInputStream调用close()方法关闭文件读取
通俗说就是,客户端发送请求到namenode,并传去想要读取的文件,namenode确定文件在datanode的起始块位置,并返回给客户端,客户端通过对数据流反复调用read方法,将数据从datanode传输到客户端,当到达块末端时,会关闭与该datanode的连接,然后寻找下一个快的最佳Datanode,做同样的操作,一旦客户端完成读取,就调用close()犯法关闭文件读取。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/106118.html原文链接:https://javaforall.net


