
上一篇文章中,已经明确的搭建了Hadoop的四台虚拟环境。
在这里我将ssh工具有xshell换成了SecureCRT,使用方式和XShell,操作是一样的。
启动所有的虚拟机器。由于是克隆产生的,所以,所有的机器环境都是相同的。
启动所有的虚拟机,并启动SecureCRT,建立Session会话。为了便于操作,将四个会话的窗口进行如图的排列

为了保证机器间的正常通信,关闭所有的防火墙,并保证防火墙永久关闭:
systemctl stop firewalldsystemctl disable firewalld
启动hadoop
① 配置hadoop
进入hadoop目录
cd /usr/local/hadoop/etc/hadoop目录如下:
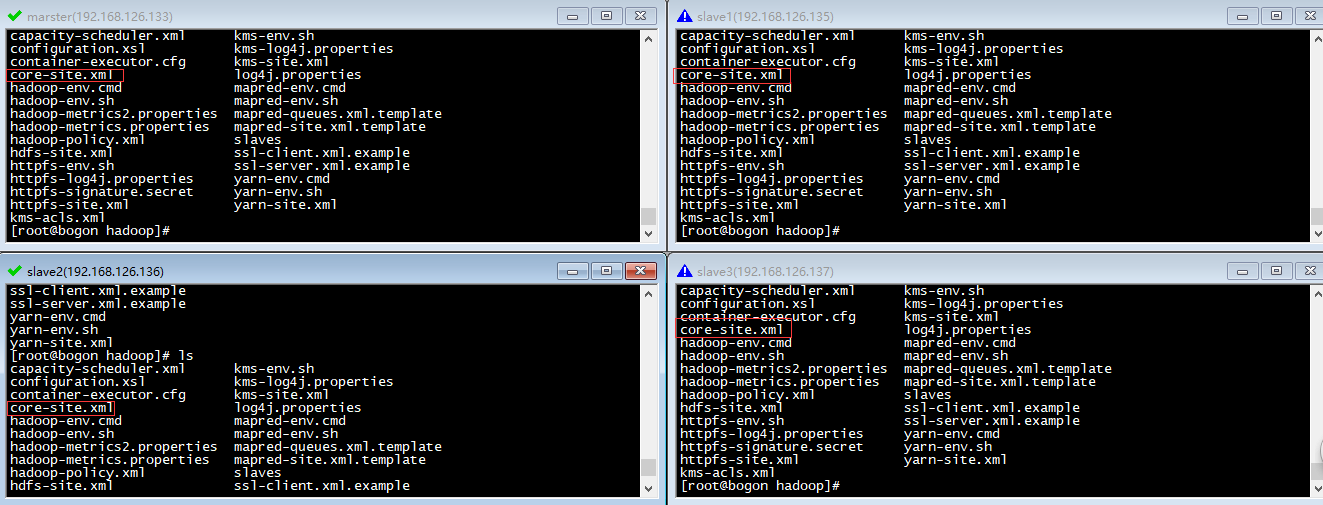
其中的core-site.xml文件,就是我们配置主机和从机的核心配置文件,此配置针对所有的hadoop机器
vim core-site.xml 打开配置文件,由于master和slaer之间是通过网络进行连接的,因此他们之间需要特定的协议,协议就在此文件中进行配置,进行如下配置
在所有的机器的该配置文件中做如下配置:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <--文件存储目录--> <property> <name>hadoop.tmp.dir</name> <value>/var/hadoop</value> </property> </configuration>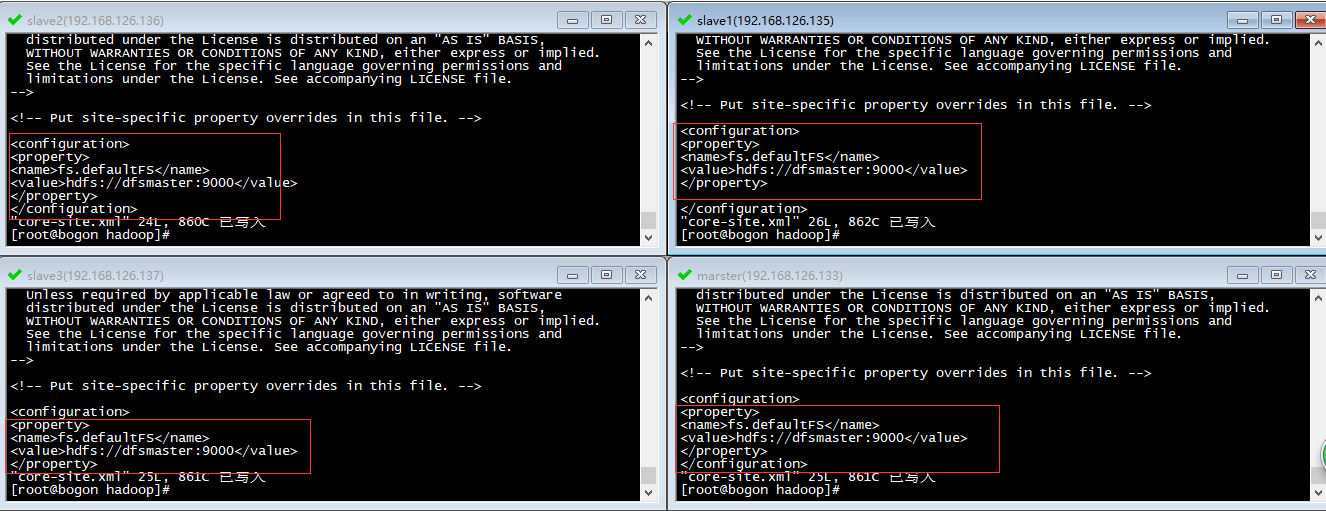
在master上配置hdfs-stie.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/var/hadoop</value> </property> </configuration>针对四台机器,master将作为主机,用来存储namenode,也就是至存储文件名称,其余的三台作为datanode,也就是真正数据存储在slaer上
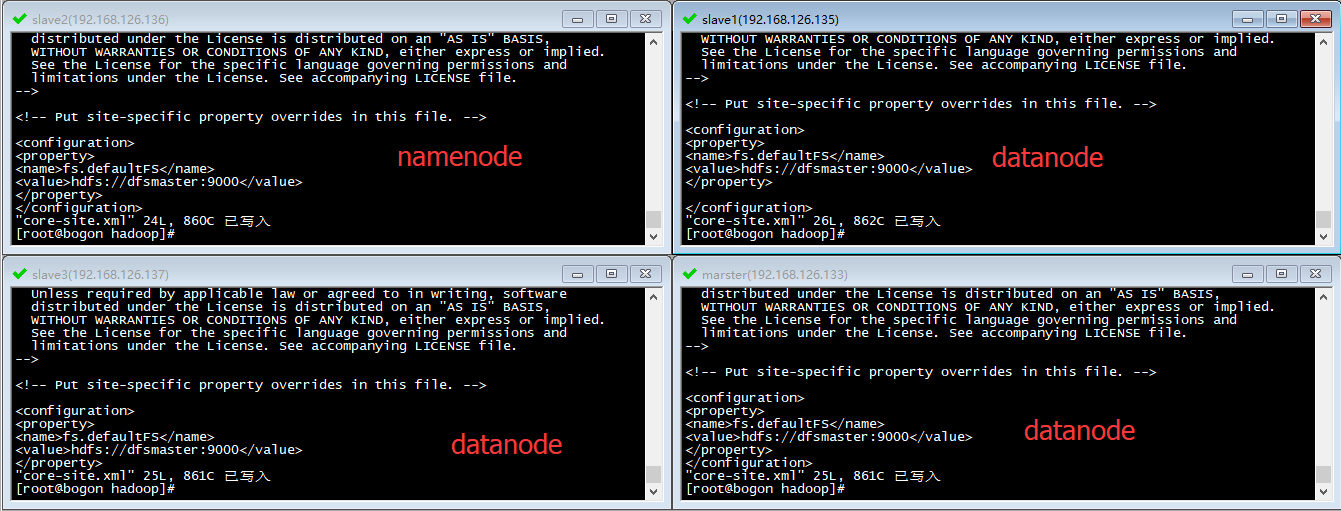
接下来分别启动master和slaer
1、格式化namenode
hdfs namenode -foramt2 、首先启动master
在master上单独执行命令:
hadoop-daemon.sh start namenode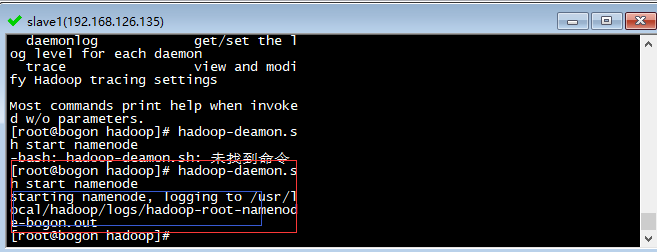
当输出蓝色框内的内容时,namenode启动成功
3 、以此启动3台slave
hadoop-daemon.sh start datanode4、停止namenode
hadoop-daemon.sh stop namenode5、停止datanode
hadoop-daemon.sh stop namenode
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/111292.html原文链接:https://javaforall.net


