
(1)持久化数据库的缺点
平常我们使用的关系型数据库有Mysql、Oracle以及SqlServer等,在开发的过程中,
数据通常都是通过Web提供的数据库驱动来链接数据库进行增删改查。
那么,我们日常使用的数据库的数据都储存在哪里呢?我们以Mysql为例。
打开我们Mysql所在的文件夹目录下的data文件夹,如下所示: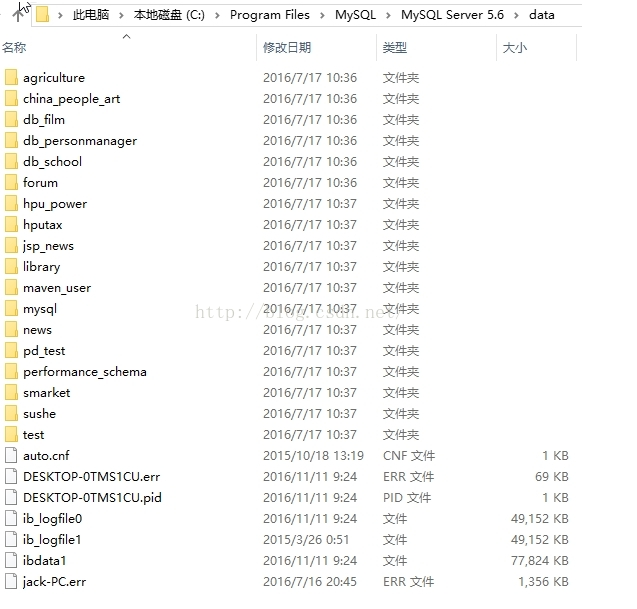

我们可以发现,里面都是我们创建的数据库,打开其中一个,可以看到我们创建的表,
他们以文件(格式frm和ibd)的形式存在: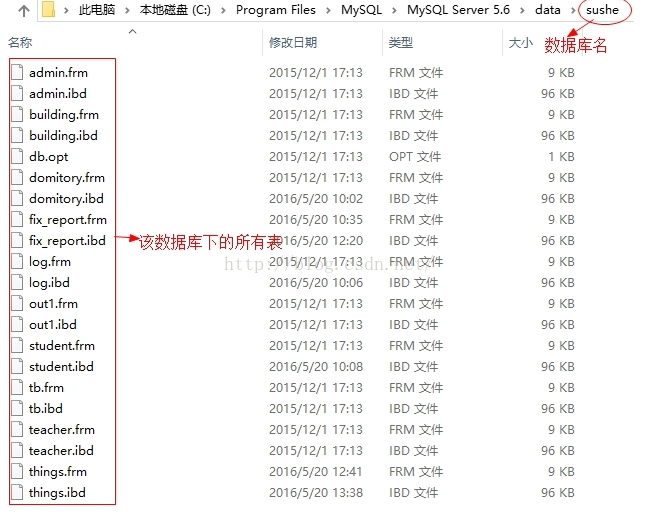
也就是说,我们日常使用的关系型数据中的数据,全部存储在我们部署数据库的机器
的硬盘中。
一般我们的网站开发完成,上线之后,服务器的读写效率是网站运行速度的重要条件,
当然还有服务器的带宽等,但是这些东西都可以通过硬件的更新升级来解决。
其实与网站运行效率息息相关的东西,就是我们的——数据库。
数据库处理数据的速度,与网站速度息息相关,而数据查询、数据处理等等,
都和数据库处理速度有关。提高数据库的处理数据的能力,其中一个方案就是
sql语句的优化技术,sql语句写的处理效率比较高,数据库处理能力就会上去,
而网站的数据处理能力也会快些。
但是,当网站的处理和访问量非常大的时候,我们的数据库的压力就变大了,数据库的
连接池,数据库同时处理数据的能力就会受到很大的挑战,一旦数据库承受了其最大承受
能力,网站的数据处理效率就会大打折扣。此时就要使用高并发处理、负载均衡和分布式数据库,
而这些技术既花费人力,又花费资金。
如果我们的网站不是非常大的网站,而有想要提高网站的效率,降低数据库的读写次数,我们就
需要引入缓存技术。
(2)缓存
缓存就是在内存中存储的数据备份,当数据没有发生本质改变的时候,我们就不让数据的查询去
数据库进行操作,而去内存中取数据,这样就大大降低了数据库的读写次数,而且从内存中读数据
的速度比去数据库查询要快一些,这样同时又提高了效率。
使用缓存减轻数据库的负载:
在开发网站的时候如果有一些数据在短时间之内不会发生变化,而它们还要被频繁访问,为了
提高用户的请求速度和降低网站的负载,就把这些数据放到一个读取速度更快的介质上(或者
是通过较少的计算量就可以获得该数据),该行为就称作对该数据的缓存。
该介质可以是文件/数据库/内存。内存经常用于数据库缓存。
缓存的两种形式:
页面缓存经常用在CMS(content manage system)内存管理系统里面。
数据缓存经常会用在页面的具体数据里面。
缓存分为两种:
页面缓存(smarty静态化技术)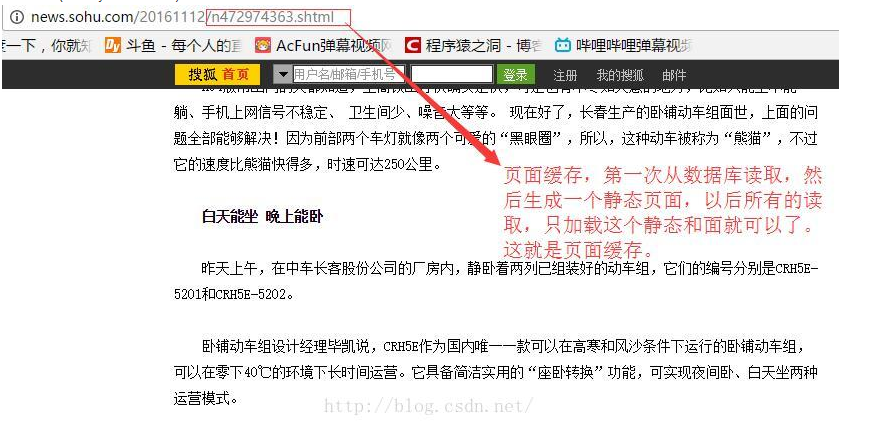
数据缓存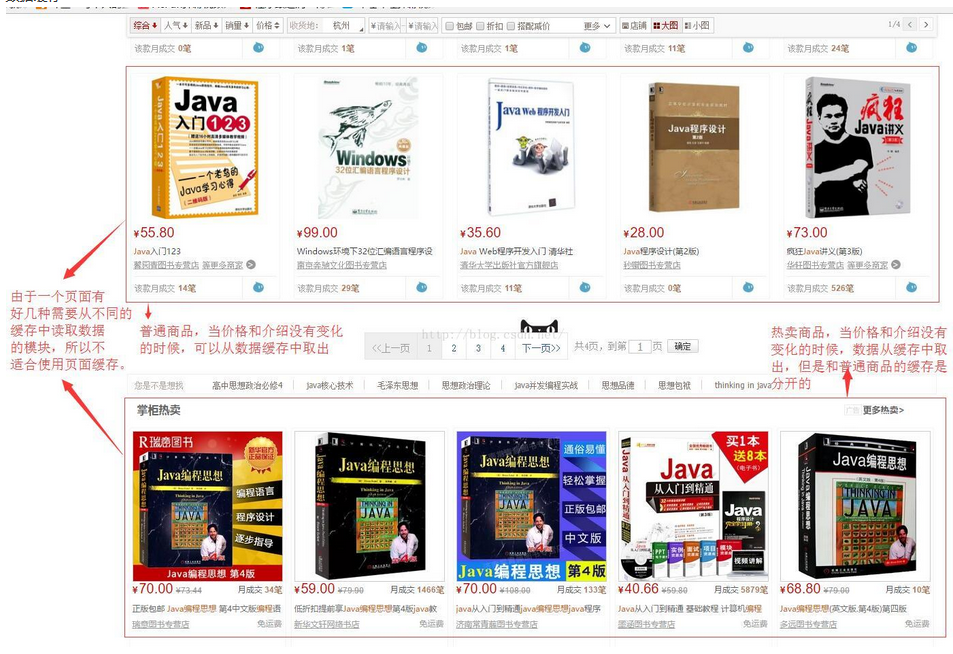
(3)Redis介绍
我们要学习的一个缓存技术就是—-Redis:
Redis是Remote Dictionary Server(远程数据服务)的缩写,由意大利人antirez(Salvatore Sanfilippo)开发的一款内存高速缓存数据库,该软件使用C语言编写,它的数据模型为key-value。
它支持丰富的数据结构(类型),比如String/List/Hash/Set/Sorted Set。
可持久化(一边运行,一边把数据往硬盘中备份一份,防止断电等情况导致数据丢失,等断电情况恢复之后,Redis再把硬盘中的数据恢复到内存中),保证了数据的安全。
(4)redis和memcache比较
1.Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2.Redis支持master-slave(主-从)模式应用
3.Redis支持数据持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
4.Redis单个value的最大限制是1GB,memcached只能保存1MB的数据。
转载请注明出处:http://blog.csdn.net/acmman/article/details/53167917
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/112738.html原文链接:https://javaforall.net


