
多元:因变量为多分类变量;结果在三种及三种以上。如:机构养老、社区养老、居家养老。
自变量:可以是分类变量或连续变量,建议是分类变量;
协变量:必须是分类变量;
步骤:
1.【分析】【回归】【多项logistic】,打开主面板—— 因变量、自变量分别按照箭头指示移入对应的变量框内,点击【参考类别】按钮,默认勾选【最后一个类别】。(指以因变量和自变量的最后一个分类水平为参照,用其他分类依次与之对比,考察不同水平间的倾向。)
2.主面板中,点击【模型】,打开【多项logistic回归:模型】对话框,勾选【主效应】。本例主要考察自变量年龄、性别、婚姻状况的主效应,暂不考察它们之间的交互作用,然后点击【继续】。
3.主面板中,点击【统计】按钮,设置模型的统计量。主要【伪R方】【模型拟合信息】【分类表】【拟合优度】这几项必选,其他可以默认不勾选。这些参数主要用于说明建模的质量。
4.主面板中,点击【保存】按钮,勾选【估算响应概率】,我们要求SPSS软件帮我们估算每个个案三类早餐的概率。下主面板底部点击【确定】按钮,软件开始执行此处建模。
5.其余的参数主要和逐步回归有关系,本例采用主效应模型,人为指定进入模型的自变量,在其他研究中,可以根据情况选择逐步回归。
结果分析与解读:
3.拟合优度表,原假设模型能很好地拟合原始数据,最后一列皮尔逊卡方显著性值0.952,概率较大,原假设成立,说明模型对原始数据的拟合通过检验。
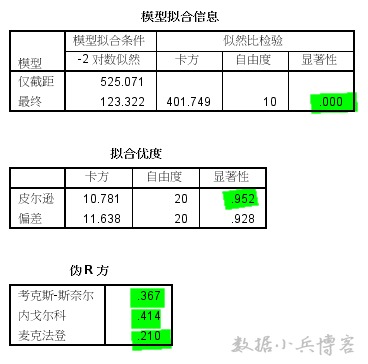

4.伪R方表,依次列出的3个伪R方值(类似于决定系数)均偏低,最高0.4,说明模型对原始变量变异的解释程度一般,还有一部分信息无法解释,拟合程度并不是很优秀。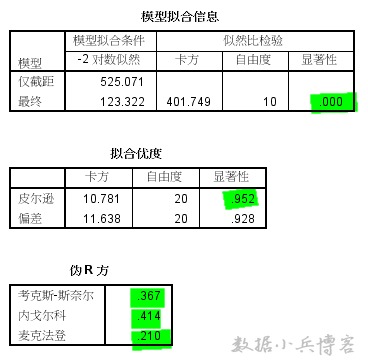
5.模型似然比检验表,我们能看到最终进入模型的效应包括截距、年龄、婚姻状况、生活态度,而且最后一列显著性值表明,三个自变量(影响因素)对模型构成均有显著贡献,研究它们是有意义的。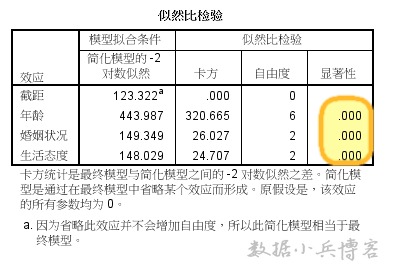
6.参数估计表,列出自变量不同分类水平对早餐选择的影响检验,是多项logistic回归非常重要的结果。
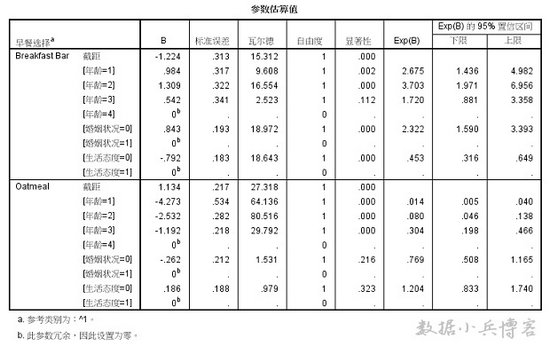
第二列B值,即各自变量不同分类水平在模型中的系数,正负符号表明它们与早餐选择是正比还是反比关系。第六列是瓦尔德检验显著性值,此值小于0.05说明对应自变量的系数具有统计意义,对因变量不同分类水平的变化有显著影响。
比如,早餐摊点和谷物类早餐相比,31-45岁的年轻人更偏向于选择在早餐摊点吃早餐,这种可能性是60岁以上人的3.7倍;燕麦类和谷物类早餐相比,结婚与否对早餐的选择没有差别。
多元logistic回归模型
1.经过对该早餐喜好民意调查数据进行多项logistic回归分析,由参数估计表,我们可以得到模型如下:
G1=LOG[P(早餐摊)/P(谷物类)]=-1.224+0.984年龄1+1.309年龄2+0.542年龄3+0.843婚姻状况0-0.792生活态度0
G2=LOG[P(燕麦类)/P(谷物类)]=1.134-4.273年龄1-2.532年龄2-1.192年龄3+0.843婚姻状况0+0.186生活态度0
G3=0 (对照组)
2.根据这个模型,我们首先计算某个受访者G1、G2、G3的值,然后带入如下公式,最终可得到三个早餐相应的概率。
P1=exp(G1)/[exp(G1)+exp(G2)+exp(G3)]
P2=exp(G2)/[exp(G1)+exp(G2)+exp(G3)]
P3=exp(G3)/[exp(G1)+exp(G2)+exp(G3)]
原始数据最右侧新增3个变量,依次为EST1_1、EST2_1、EST3_1,分别对应因变量“早餐选择”的三个分类水平(早餐摊、燕麦类、谷物类)的响应概率。比如第一个个案,他选择谷物类早餐的概率为0.55,在三种选择中数值最大,因此,模型会判定他选择谷物类早餐,这和原始记录的真值一致,说明模型判断准确。
当然,SPSS软件也输出了模型预测分类表,如下所示。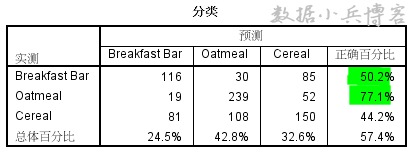
模型在预测燕麦类早餐选择倾向上准确率最高,达到77%,其他两个早餐选择的预测略低,模型总体预测准确率为57.4%,表现一般。前面伪R方数据显示,模型对总体变异的解释能力不足,这和总体预测准确率结论也一致。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233607.html原文链接:https://javaforall.net


